本篇内容主要讲解“Raft共识算法是什么”,感兴趣的朋友不妨来看看。本文介绍的方法操作简单快捷,实用性强。下面就让小编来带大家学习“Raft共识算法是什么”吧!
Raft算法主要应用于分布式集群系统中,如果保证高可用和数据一致性,它主要定义两方面的规范:选主(Leader Election)和复制日志(Log Replication)
Raft定义了集群节点三个状态:Leader(主)、Follower (从)、Candidate(候选)
主:负责与对接外部输入 ,并保持与从的心跳
从:备份数据、主挂了的时候要挑起重担
候选:当从timeout时间内(150ms 到 300ms,每个节点不一样)没有收到主的心跳,转为此状态
从以下几种情形中分析选主是如何运作的
开始所有节点都是Follower状态,当其中一个节点在timeout过后,就会转变成Candidate并向其它节点发送投票请求,并开始新的timeout。
超过半数Follower节点收到请求并回复确认后,Candidate节点就会转变成Leader节点,并向Follower节点发送心跳
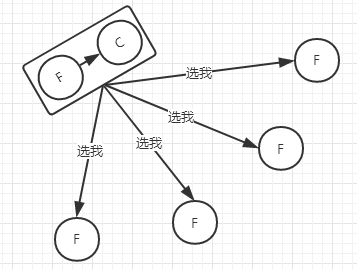

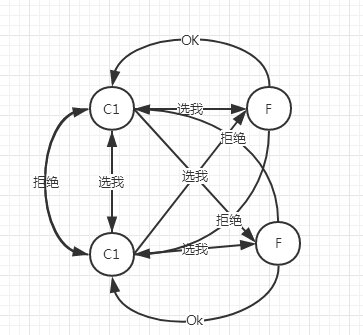
当有多个Candidate时,会向其余节点发送选举请求,Candidate节点会拒绝其它节点的请求,Follower节点接收到其中一个Candidate节点请求后,会拒绝同一选举轮回的其它请求,如果此时其中一个节点获得半数节点同意,自动成为Leader,如果两个Candidate节点没有分出胜负后,当timeout节点会发起第二轮选举请求,此时就看谁先timeout结束并获得半数节点同意,就成为Leader

数据复制主要是为了保证数据的可靠和一致性,当数据变更时,Leader将数据同步给Follower
从以下几种场景如何执行数据复制
大致可以分为8个步骤
外部向Leader发布数据,
1.Leader将数据保存,状态为uncommit
2.Leader将数据通过appendEntries发送给Follower
3.Follower将数据保存,状态为uncommit
4.Follower返回确认给Leader
5.Leader收到半数以上Follower的确认后,将数据状态更改为commit
6.Leader返回确认
7.Leader再次通过appendEntries将数据发送给Follower
8.Follower将数据状态更改为commit
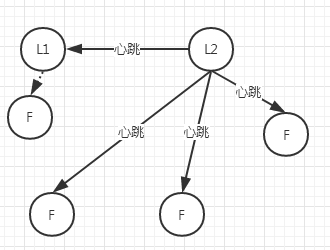
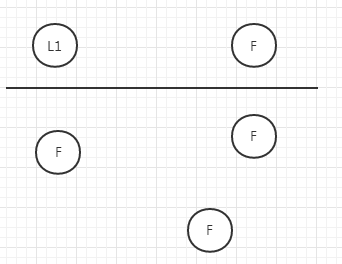
也就是在部分节点网络问题没法通信情况下
没有Leader的一方,通过选举得到leader,此Leader的选举轮次+1
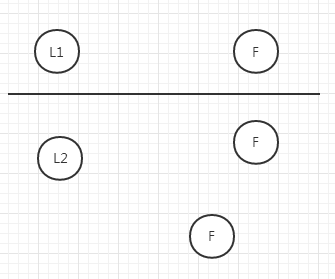
此时就出现了两个Leader可以对外提供服务
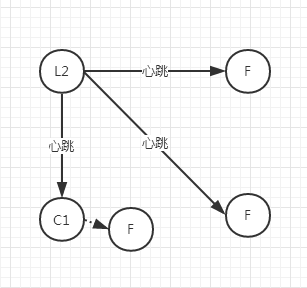
如果此时有外部数据进来,分别传给了L1和L2,未超过半数的一方因为得到确认的数量也未达到半数,所以数据都是uncommit状态,返回也是失败
而超过半数的一方数据为commit
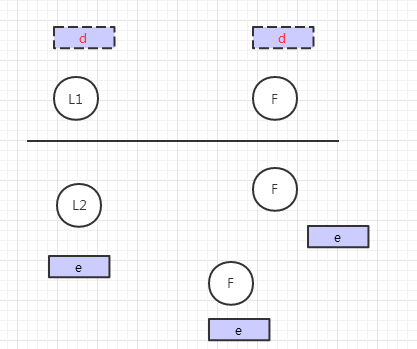
此时如果网络恢复了,通过选举规则,轮次高的Leader一方为继续为Leader,另一方降级为Follower
此时uncommite的数据将被删除,未同步的数据将会被补充
到此,相信大家对“Raft共识算法是什么”有了更深的了解,不妨来实际操作一番吧!这里是亿速云网站,更多相关内容可以进入相关频道进行查询,关注我们,继续学习!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





