这篇文章将为大家详细讲解有关如何理解Mybatis源码中的Cache,文章内容质量较高,因此小编分享给大家做个参考,希望大家阅读完这篇文章后对相关知识有一定的了解。
通过复杂业务计算得来的数据,在计算过程中可能耗费大量的时间,需要将数据缓存
读多写少的数据
缓存的容量
缓存的有效时间
访问的缓存不存在,直接去访问数据库。通常查找的key没有对应的缓存,可以设计为返回空值,不去查找数据库。
大量的缓存穿透会导致有大量请求,访问都会落到数据库上,造成缓存雪崩。所以如果访问的key在缓存中找不到,不要直接去查询数据库,也就是要避免缓存穿透,可以设置缓存为永久缓存,然后通过后台定时更新缓存。也可以为缓存更新添加锁保护,确保当前只有一个线程更新数据。
使用范围:SESSION,STATEMENT。默认为SESSION,如果不想使用一级缓存,可以修改为STATEMENT,每次调用后都会清掉缓存。
//STATEMENT或者SESSION,默认为SESSION
<setting name="localCacheScope" value="STATEMENT"/>一级缓存执行的流程: 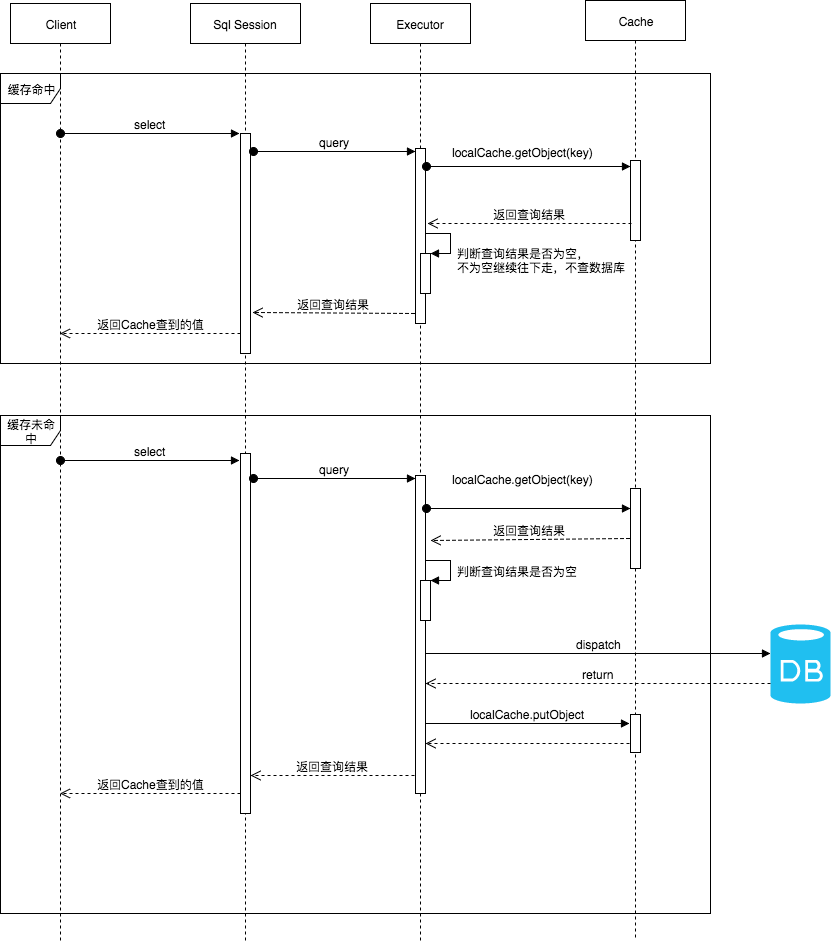
//BaseExecutor.query
public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
ErrorContext.instance().resource(ms.getResource()).activity("executing a query").object(ms.getId());
...
List<E> list;
try {
...
//先根据cachekey从localCache去查
list = resultHandler == null ? (List<E>) localCache.getObject(key) : null;
if (list != null) {
//若查到localCache缓存,处理localOutputParameterCache
handleLocallyCachedOutputParameters(ms, key, parameter, boundSql);
} else {
//从数据库查
list = queryFromDatabase(ms, parameter, rowBounds, resultHandler, key, boundSql);
}
} finally {
//清空堆栈
queryStack--;
}
...
if (configuration.getLocalCacheScope() == LocalCacheScope.STATEMENT) {
// issue #482
//如果是STATEMENT,清本地缓存
clearLocalCache();
}
return list;
}什么情况下有效?在,一个sqlSession打开和关闭的范围内,所以,如果被Spring托管并且没有开启事务,那么一级缓存是失效的。
注意: 打开两个sqlsession: sqlsession1,sqlsession2,sqlsession1.select从一级缓存中取数据,sqlsession2更新此条数据,sqlsession1.select再次获取数据,还是缓存中的。
SessionFactory层面给各个SqlSession 对象共享
怎么配置:
<setting name="cacheEnabled" value="true" /> (或@CacheNamespace)
<cache/>,<cache-ref/>或@CacheNamespace
//每个select设置
<select id="queryDynamicFlightVOs" resultType="com.ytkj.aoms.aiis.flightschedule.vo.DynamicFlightVO" useCache="false">如果配置了二级缓存,那么在获取Executor的时候会返回CachingExecutor
//Configuration.java
//产生执行器
public Executor newExecutor(Transaction transaction, ExecutorType executorType) {
executorType = executorType == null ? defaultExecutorType : executorType;
//这句再做一下保护,,防止粗心大意的人将defaultExecutorType设成null?
executorType = executorType == null ? ExecutorType.SIMPLE : executorType;
Executor executor;
//然后就是简单的3个分支,产生3种执行器BatchExecutor/ReuseExecutor/SimpleExecutor
if (ExecutorType.BATCH == executorType) {
executor = new BatchExecutor(this, transaction);
} else if (ExecutorType.REUSE == executorType) {
executor = new ReuseExecutor(this, transaction);
} else {
executor = new SimpleExecutor(this, transaction);
}
//如果要求缓存,生成另一种CachingExecutor(默认就是有缓存),装饰者模式,所以默认都是返回CachingExecutor
if (cacheEnabled) {
executor = new CachingExecutor(executor);
}
//此处调用插件,通过插件可以改变Executor行为
executor = (Executor) interceptorChain.pluginAll(executor);
return executor;
}开启了二级缓存后,会先使用CachingExecutor查询,查询不到在查一级缓存。 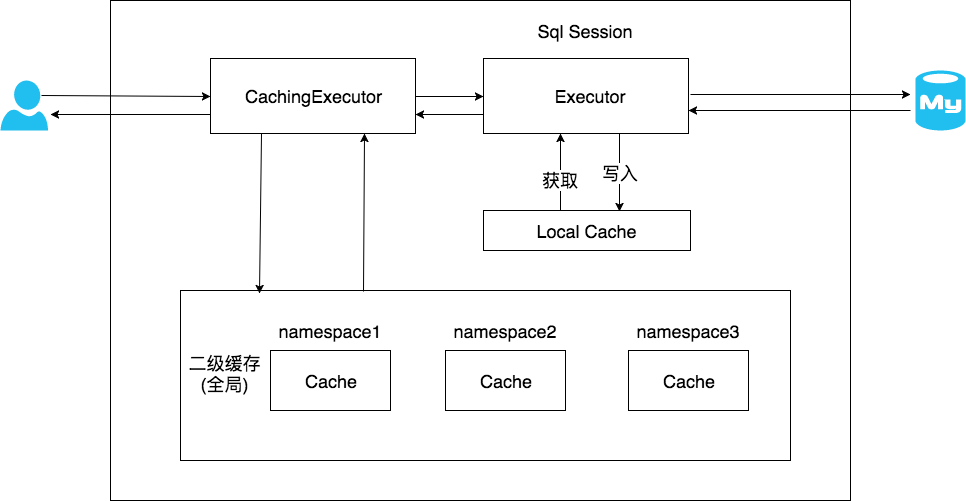
public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
//namespace配置作用
Cache cache = ms.getCache();
if (cache != null) {
//是否执行刷新缓存操作
this.flushCacheIfRequired(ms);
//useCache标签作用
if (ms.isUseCache() && resultHandler == null) {
this.ensureNoOutParams(ms, parameterObject, boundSql);
List<E> list = (List)this.tcm.getObject(cache, key);
if (list == null) {
list = this.delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
this.tcm.putObject(cache, key, list);
}
return list;
}
}
return this.delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
}由于二级缓存中的数据是基于namespace的,即不同namespace中的数据互不干扰。在多个namespace中若均存在对同一个表的操作,那么这多个namespace中的数据可能就会出现不一致现象
在分布式环境下,由于默认的MyBatis Cache实现都是基于本地的,分布式环境下必然会出现读取到脏数据,需要使用集中式缓存将MyBatis的Cache接口实现,有一定的开发成本,直接使用Redis、Memcached等分布式缓存可能成本更低,安全性也更高
通过装饰器模式,我们可以向一个现有的对象添加新的功能,同时不改变其结构。
Mybatis中不同类型的缓存,正是使用了此类设计。
PerpetualCache实现了Cache接口,完成了基本的Cache功能,其他的装饰类对其进行功能扩展。以LruCache为例:
public class LruCache implements Cache {
//持有实现类
private final Cache delegate;
//额外用了一个map才做lru,但是委托的Cache里面其实也是一个map,这样等于用2倍的内存实现lru功能
private Map<Object, Object> keyMap;
private Object eldestKey;
public LruCache(Cache delegate) {
this.delegate = delegate;
setSize(1024);
}
.....
}LruCache使用了一个LinkedHashMap作为keyMap,最多存1024个key的值,超过之后新加对象到缓存时,会将不经常使用的key从keyMap中移除,并且删除掉缓存中对应的key。利用了LinkedHashMap的特性:
每次访问或者插入一个元素都会把元素放到链表末尾
//LinkedHashMap的get方法
public V get(Object key) {
Node<K,V> e;
if ((e = getNode(hash(key), key)) == null)
return null;
if (accessOrder)
afterNodeAccess(e);
return e.value;
}调用put,putAll方法的时候会调用removeEldestEntry方法,所以LruCache在new LinkedHashMap的时候重写了removeEldestEntry方法
public void setSize(final int size) {
keyMap = new LinkedHashMap<Object, Object>(size, .75F, true) {
private static final long serialVersionUID = 4267176411845948333L;
//核心就是覆盖 LinkedHashMap.removeEldestEntry方法,
//返回true或false告诉 LinkedHashMap要不要删除此最老键值
//LinkedHashMap内部其实就是每次访问或者插入一个元素都会把元素放到链表末尾,
//这样不经常访问的键值肯定就在链表开头啦
@Override
protected boolean removeEldestEntry(Map.Entry<Object, Object> eldest) {
boolean tooBig = size() > size;
if (tooBig) {
//根据eldestKey去缓存中删除
eldestKey = eldest.getKey();
}
return tooBig;
}
};
}
private void cycleKeyList(Object key) {
keyMap.put(key, key);
//keyMap是linkedhashmap,最老的记录已经被移除了,然后这里我们还需要移除被委托的那个cache的记录
if (eldestKey != null) {
delegate.removeObject(eldestKey);
eldestKey = null;
}
}BlockingCache:阻塞版本的缓存装饰器,它保证只有一个线程到数据库中查找指定key对应的数据, 加入线程A 在BlockingCache 中未查找到keyA对应的缓存项时,线程A会获取keyA对应的锁,这样后续线程在查找keyA是会发生阻塞。
FifoCache:先进先出缓存,FifoCache在putObject的时候会将Key放到一个List中,list长度为1024,如果超过,则删除第一个缓存,最后一位添加当前缓存
LoggingCache:日志缓存,它持有日志接口,根据日志的设置可打印sql和命中率等。
LruCache:最近最少使用算法。核心思想是当缓存满时,会优先淘汰那些近期最少使用的缓存。
ScheduledCache:定时调度缓存,每次访问和添加缓存的时候会判断当前时间和上次清理的时间是否超过阈值,超过则会清理缓存。
SerializedCache:序列化缓存。缓存的值会被序列化。取值的时候会反序列化。要求缓存的对象实现Serializable接口。
SoftCache:软引用缓存。对于软引用关联着的对象,只有在内存不足的时候JVM才会回收该对象,使用SoftReference可以避免OOM异常
WeakCache:弱引用缓存,类似SoftCache。与软引用区别在于当JVM进行垃圾回收时,无论内存是否充足,都会回收被弱引用关联的对象。
TransactionalCache:事务缓存
关于如何理解Mybatis源码中的Cache就分享到这里了,希望以上内容可以对大家有一定的帮助,可以学到更多知识。如果觉得文章不错,可以把它分享出去让更多的人看到。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/lfy2008/blog/3104470



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



