PythonзҲ¬иҷ«дёӯзҡ„scrapyзҲ¬иҷ«е®һдҫӢ
жң¬зҜҮеҶ…е®№д»Ӣз»ҚдәҶвҖңPythonзҲ¬иҷ«дёӯзҡ„scrapyзҲ¬иҷ«е®һдҫӢвҖқзҡ„жңүе…ізҹҘиҜҶпјҢеңЁе®һйҷ…жЎҲдҫӢзҡ„ж“ҚдҪңиҝҮзЁӢдёӯпјҢдёҚе°‘дәәйғҪдјҡйҒҮеҲ°иҝҷж ·зҡ„еӣ°еўғпјҢжҺҘдёӢжқҘе°ұи®©е°Ҹзј–еёҰйўҶеӨ§е®¶еӯҰд№ дёҖдёӢеҰӮдҪ•еӨ„зҗҶиҝҷдәӣжғ…еҶөеҗ§пјҒеёҢжңӣеӨ§е®¶д»”з»Ҷйҳ…иҜ»пјҢиғҪеӨҹеӯҰжңүжүҖжҲҗпјҒ
йЎ№зӣ®йңҖжұӮ
еңЁдё“й—ЁдҫӣзҲ¬иҷ«еҲқеӯҰиҖ…и®ӯз»ғзҲ¬иҷ«жҠҖжңҜзҡ„зҪ‘з«ҷпјҲhttp://quotes.toscrape.com)дёҠзҲ¬еҸ–еҗҚиЁҖиӯҰеҸҘгҖӮ
еҲӣе»әйЎ№зӣ®
еңЁејҖе§ӢзҲ¬еҸ–д№ӢеүҚпјҢеҝ…йЎ»еҲӣе»әдёҖдёӘж–°зҡ„ScrapyйЎ№зӣ®гҖӮиҝӣе…ҘжӮЁжү“з®—еӯҳеӮЁд»Јз Ғзҡ„зӣ®еҪ•дёӯпјҢиҝҗиЎҢдёӢеҲ—е‘Ҫд»Ө:
(base) О» scrapy startproject quotes
New scrapy project 'quotes 'пјҢ using template directory 'd: \anaconda3\lib\site-packages\scrapy\temp1ates\project ', created in:
D:\XXX
You can start your first spider with :
cd quotes
scrapy genspider example example. com
йҰ–е…ҲеҲҮжҚўеҲ°ж–°е»әзҡ„зҲ¬иҷ«йЎ№зӣ®зӣ®еҪ•дёӢпјҢд№ҹе°ұжҳҜ/quotesзӣ®еҪ•дёӢгҖӮ然еҗҺжү§иЎҢеҲӣе»әзҲ¬иҷ«ж–Ү件зҡ„е‘Ҫд»Ө:
D:\XXX(master)
(base) О» cd quotes\
D:\XXX\quotes (master)
(base) О» scrapy genspider quotes quotes.com
cannot create a spider with the same name as your project
D :\XXX\quotes (master)
(base) О» scrapy genspider quote quotes.com
created spider 'quote' using template 'basic' in module:quotes.spiders.quote
иҜҘе‘Ҫд»Өе°ҶдјҡеҲӣе»әеҢ…еҗ«дёӢеҲ—еҶ…е®№зҡ„quotesзӣ®еҪ•:

robots.txt
robotsеҚҸи®®д№ҹеҸ«robots.txt(з»ҹдёҖе°ҸеҶҷпјүжҳҜдёҖз§Қеӯҳж”ҫдәҺзҪ‘з«ҷж №зӣ®еҪ•дёӢзҡ„ASCIIзј–з Ғзҡ„ж–Үжң¬ж–Ү件пјҢе®ғйҖҡеёёе‘ҠиҜүзҪ‘з»ңжҗңзҙўеј•ж“Һзҡ„зҪ‘з»ңиңҳиӣӣпјҢжӯӨзҪ‘з«ҷдёӯзҡ„е“ӘдәӣеҶ…е®№жҳҜдёҚеә”иў«жҗңзҙўеј•ж“Һзҡ„зҲ¬иҷ«иҺ·еҸ–зҡ„пјҢе“ӘдәӣжҳҜеҸҜд»Ҙиў«зҲ¬иҷ«иҺ·еҸ–зҡ„гҖӮ
robotsеҚҸ议并дёҚжҳҜдёҖдёӘ规иҢғпјҢиҖҢеҸӘжҳҜзәҰе®ҡдҝ—жҲҗзҡ„гҖӮ
#filename : settings.py
#obey robots.txt rules
ROBOTSTXT__OBEY = False
еҲҶжһҗйЎөйқў
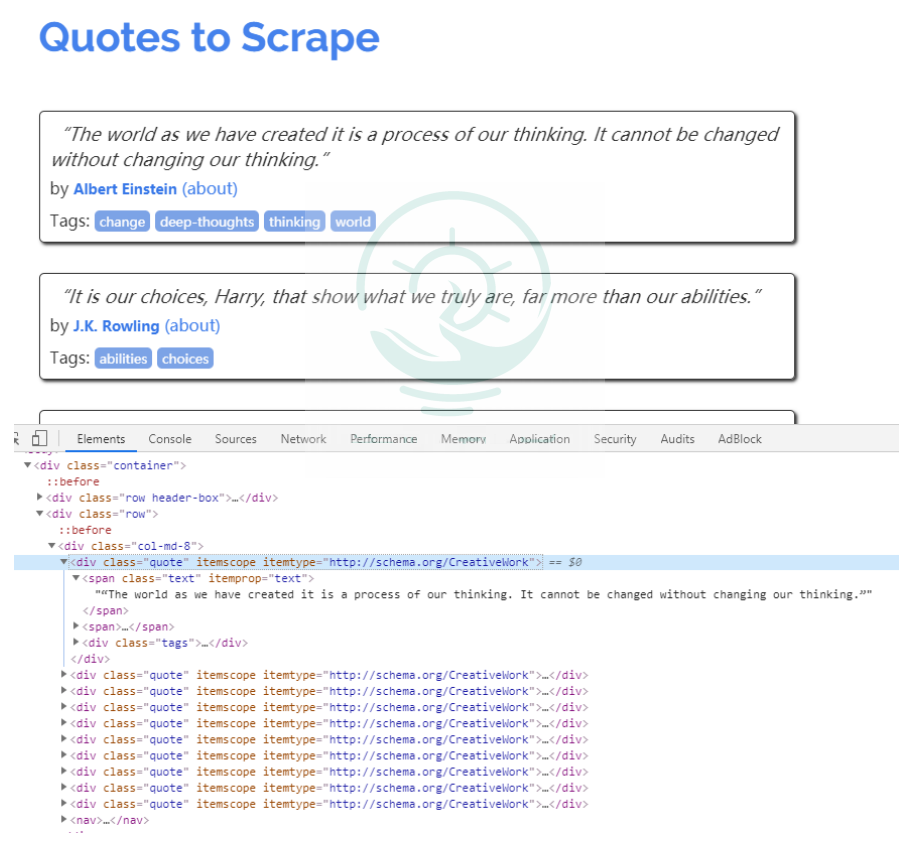
зј–еҶҷзҲ¬иҷ«зЁӢеәҸд№ӢеүҚпјҢйҰ–е…ҲйңҖиҰҒеҜ№еҫ…зҲ¬еҸ–зҡ„йЎөйқўиҝӣиЎҢеҲҶжһҗпјҢдё»жөҒзҡ„жөҸи§ҲеҷЁдёӯйғҪеёҰжңүеҲҶжһҗйЎөйқўзҡ„е·Ҙе…·жҲ–жҸ’件пјҢиҝҷйҮҢжҲ‘们йҖүз”ЁChromeжөҸи§ҲеҷЁзҡ„ејҖеҸ‘иҖ…е·Ҙе…·(ToolsвҶ’Developer toolsпјүеҲҶжһҗйЎөйқўгҖӮ
ж•°жҚ®дҝЎжҒҜ
еңЁChromeжөҸи§ҲеҷЁдёӯжү“ејҖйЎөйқўhttp://lquotes.toscrape.comпјҢ然еҗҺйҖүжӢ©"Elements"пјҢжҹҘзңӢе…¶HTMLд»Јз ҒгҖӮ
еҸҜд»ҘзңӢеҲ°жҜҸдёҖдёӘж ҮзӯҫйғҪеҢ…иЈ№еңЁ
зј–еҶҷspider
еҲҶжһҗе®ҢйЎөйқўеҗҺпјҢжҺҘдёӢжқҘзј–еҶҷзҲ¬иҷ«гҖӮеңЁScrapyдёӯзј–еҶҷдёҖдёӘзҲ¬иҷ«пјҢ еңЁscrapy.Spiderдёӯзј–еҶҷд»Јз ҒSpiderжҳҜз”ЁжҲ·зј–еҶҷз”ЁдәҺд»ҺеҚ•дёӘзҪ‘з«ҷ(жҲ–иҖ…-дәӣзҪ‘з«ҷ)зҲ¬еҸ–ж•°жҚ®зҡ„зұ»гҖӮ
е…¶еҢ…еҗ«дәҶ-дёӘз”ЁдәҺдёӢиҪҪзҡ„еҲқе§ӢURL,еҰӮдҪ•и·ҹиҝӣзҪ‘йЎөдёӯзҡ„й“ҫжҺҘд»ҘеҸҠеҰӮдҪ•еҲҶжһҗйЎөйқўдёӯзҡ„еҶ…е®№пјҢжҸҗеҸ–з”ҹжҲҗitemзҡ„ж–№жі•гҖӮ
дёәдәҶеҲӣе»әдёҖдёӘSpider, жӮЁеҝ…须继жүҝscrapy.Spiderзұ»пјҢдё”е®ҡд№үд»ҘдёӢдёүдёӘеұһжҖ§:
name:з”ЁдәҺеҢәеҲ«SpiderгҖӮиҜҘеҗҚеӯ—еҝ…йЎ»жҳҜе”ҜдёҖ-зҡ„, жӮЁдёҚеҸҜд»ҘдёәдёҚеҗҢзҡ„Spiderи®ҫе®ҡзӣёеҗҢзҡ„еҗҚеӯ—гҖӮ
start _urls:еҢ…еҗ«дәҶSpiderеңЁеҗҜеҠЁж—¶иҝӣиЎҢзҲ¬еҸ–зҡ„urеҲ—иЎЁгҖӮеӣ жӯӨпјҢ 第дёҖдёӘиў«иҺ·еҸ–еҲ°зҡ„йЎөйқўе°ҶжҳҜе…¶дёӯд№ӢдёҖгҖӮеҗҺз»ӯзҡ„URLеҲҷд»ҺеҲқе§Ӣзҡ„URLиҺ·еҸ–еҲ°зҡ„ж•°жҚ®дёӯжҸҗеҸ–гҖӮ
parse():жҳҜspiderзҡ„дёҖдёҖдёӘж–№жі•гҖӮиў«и°ғз”Ёж—¶пјҢжҜҸдёӘеҲқе§ӢURLе®ҢжҲҗдёӢиҪҪеҗҺз”ҹжҲҗзҡ„ResponseеҜ№иұЎе°ҶдјҡдҪңдёәе”ҜдёҖзҡ„еҸӮж•°дј йҖ’з»ҷиҜҘеҮҪж•°гҖӮиҜҘж–№жі•иҙҹиҙЈи§Јжһҗиҝ”еӣһзҡ„ж•°жҚ®(response data),жҸҗеҸ–ж•°жҚ®(з”ҹжҲҗitem)д»ҘеҸҠз”ҹжҲҗйңҖиҰҒиҝӣдёҖжӯҘеӨ„зҗҶзҡ„URL зҡ„RequestеҜ№иұЎгҖӮ
import scrapy
class QuoteSpi der(scrapy . Spider):
name ='quote'
allowed_ domains = [' quotes. com ']
start_ urls = ['http://quotes . toscrape . com/']
def parse(selfпјҢ response) :
pass
дёӢйқўеҜ№quoteзҡ„е®һзҺ°еҒҡз®ҖеҚ•иҜҙжҳҺгҖӮ
scrapy.spider :зҲ¬иҷ«еҹәзұ»пјҢжҜҸдёӘе…¶д»–зҡ„spiderеҝ…须继жүҝиҮӘиҜҘзұ»(еҢ…жӢ¬ScrapyиҮӘеёҰзҡ„е…¶д»–spiderд»ҘеҸҠжӮЁиҮӘе·ұзј–еҶҷзҡ„spider)гҖӮ
nameжҳҜзҲ¬иҷ«зҡ„еҗҚеӯ—пјҢжҳҜеңЁgenspiderзҡ„ж—¶еҖҷжҢҮе®ҡзҡ„гҖӮ
allowed_domainsжҳҜзҲ¬иҷ«иғҪжҠ“еҸ–зҡ„еҹҹеҗҚпјҢзҲ¬иҷ«еҸӘиғҪеңЁиҝҷдёӘеҹҹеҗҚдёӢжҠ“еҸ–зҪ‘йЎөпјҢеҸҜд»ҘдёҚеҶҷгҖӮ
start_ur1sжҳҜScrapyжҠ“еҸ–зҡ„зҪ‘з«ҷпјҢжҳҜеҸҜиҝӯд»Јзұ»еһӢпјҢеҪ“然еҰӮжһңжңүеӨҡдёӘзҪ‘йЎөпјҢеҲ—иЎЁдёӯеҶҷе…ҘеӨҡдёӘзҪ‘еқҖеҚіеҸҜпјҢеёёз”ЁеҲ—иЎЁжҺЁеҜјејҸзҡ„еҪўејҸгҖӮ
parseз§°дёәеӣһи°ғеҮҪж•°пјҢиҜҘж–№жі•дёӯзҡ„responseе°ұжҳҜstart_urls зҪ‘еқҖеҸ‘еҮәиҜ·жұӮеҗҺеҫ—еҲ°зҡ„е“Қеә”гҖӮеҪ“然д№ҹеҸҜд»ҘжҢҮе®ҡе…¶д»–еҮҪж•°жқҘжҺҘ收е“Қеә”гҖӮдёҖдёӘйЎөйқўи§ЈжһҗеҮҪж•°йҖҡеёёйңҖиҰҒе®ҢжҲҗд»ҘдёӢдёӨдёӘд»»еҠЎ:
1.жҸҗеҸ–йЎөйқўдёӯзҡ„ж•°жҚ®(reгҖҒXPathгҖҒCSSйҖүжӢ©еҷЁ)
2.жҸҗеҸ–йЎөйқўдёӯзҡ„й“ҫжҺҘпјҢ并дә§з”ҹеҜ№й“ҫжҺҘйЎөйқўзҡ„дёӢиҪҪиҜ·жұӮгҖӮ
йЎөйқўи§ЈжһҗеҮҪж•°йҖҡеёёиў«е®һзҺ°жҲҗдёҖдёӘз”ҹжҲҗеҷЁеҮҪж•°пјҢжҜҸдёҖйЎ№д»ҺйЎөйқўдёӯжҸҗеҸ–зҡ„ж•°жҚ®д»ҘеҸҠжҜҸдёҖдёӘеҜ№й“ҫжҺҘйЎөйқўзҡ„дёӢиҪҪиҜ·жұӮйғҪз”ұyieldиҜӯеҸҘжҸҗдәӨз»ҷScrapyеј•ж“ҺгҖӮ
и§Јжһҗж•°жҚ®
import scrapy
def parse(se1fпјҢresponse) :
quotes = response.css('.quote ')
for quote in quotes:
text = quote.css( '.text: :text ' ).extract_first()
auth = quote.css( '.author : :text ' ).extract_first()
tages = quote.css('.tags a: :text' ).extract()
yield dict(text=textпјҢauth=authпјҢtages=tages)йҮҚзӮ№пјҡ
response.css(зӣҙжҺҘдҪҝз”ЁcssиҜӯжі•еҚіеҸҜжҸҗеҸ–е“Қеә”дёӯзҡ„ж•°жҚ®гҖӮ
start_ur1s дёӯеҸҜд»ҘеҶҷеӨҡдёӘзҪ‘еқҖпјҢд»ҘеҲ—иЎЁж јејҸеҲҶеүІејҖеҚіеҸҜгҖӮ
extract()жҳҜжҸҗеҸ–cssеҜ№иұЎдёӯзҡ„ж•°жҚ®пјҢжҸҗеҸ–еҮәжқҘд»ҘеҗҺжҳҜеҲ—иЎЁпјҢеҗҰеҲҷжҳҜдёӘеҜ№иұЎгҖӮ并且еҜ№дәҺ
extract_first()жҳҜжҸҗеҸ–第дёҖдёӘ
иҝҗиЎҢзҲ¬иҷ«
еңЁ/quotesзӣ®еҪ•дёӢиҝҗиЎҢscrapycrawlquotesеҚіеҸҜиҝҗиЎҢзҲ¬иҷ«йЎ№зӣ®гҖӮ
иҝҗиЎҢзҲ¬иҷ«д№ӢеҗҺеҸ‘з”ҹдәҶд»Җд№Ҳ?
ScrapyдёәSpiderзҡ„start_urlsеұһжҖ§дёӯзҡ„жҜҸдёӘURLеҲӣе»әдәҶscrapy.RequestеҜ№иұЎпјҢ并е°Ҷparseж–№жі•дҪңдёәеӣһи°ғеҮҪж•°(callback)иөӢеҖјз»ҷдәҶRequestгҖӮ
RequestеҜ№иұЎз»ҸиҝҮи°ғеәҰпјҢжү§иЎҢз”ҹжҲҗscrapy.http.ResponseеҜ№иұЎе№¶йҖҒеӣһз»ҷspider parse()ж–№жі•иҝӣиЎҢеӨ„зҗҶгҖӮ
е®ҢжҲҗд»Јз ҒеҗҺпјҢиҝҗиЎҢзҲ¬иҷ«зҲ¬еҸ–ж•°жҚ®пјҢеңЁshellдёӯжү§иЎҢscrapy crawl <SPIDER_NAME>е‘Ҫд»ӨиҝҗиЎҢзҲ¬иҷ«'quote',并е°ҶзҲ¬еҸ–зҡ„ж•°жҚ®еӯҳеӮЁеҲ°csvж–Ү件дёӯ:
(base) О» scrapy craw1 quote -o quotes.csv
2021-06-19 20:48:44 [scrapy.utils.log] INF0: Scrapy 1.8.0 started (bot: quotes)
зӯүеҫ…зҲ¬иҷ«иҝҗиЎҢз»“жқҹеҗҺпјҢе°ұдјҡеңЁеҪ“еүҚзӣ®еҪ•дёӢз”ҹжҲҗдёҖдёӘquotes.csvзҡ„ж–Ү件пјҢйҮҢйқўзҡ„ж•°жҚ®е·Іcsvж јејҸеӯҳж”ҫгҖӮ
-oж”ҜжҢҒдҝқеӯҳдёәеӨҡз§Қж јејҸгҖӮдҝқеӯҳж–№ејҸд№ҹйқһеёёз®ҖеҚ•пјҢеҸӘиҰҒз»ҷдёҠж–Ү件зҡ„еҗҺзјҖеҗҚе°ұеҸҜд»ҘдәҶгҖӮ(csvгҖҒjsonгҖҒpickleзӯү)
вҖңPythonзҲ¬иҷ«дёӯзҡ„scrapyзҲ¬иҷ«е®һдҫӢвҖқзҡ„еҶ…е®№е°ұд»Ӣз»ҚеҲ°иҝҷйҮҢдәҶпјҢж„ҹи°ўеӨ§е®¶зҡ„йҳ…иҜ»гҖӮеҰӮжһңжғідәҶи§ЈжӣҙеӨҡиЎҢдёҡзӣёе…ізҡ„зҹҘиҜҶеҸҜд»Ҙе…іжіЁдәҝйҖҹдә‘зҪ‘з«ҷпјҢе°Ҹзј–е°ҶдёәеӨ§е®¶иҫ“еҮәжӣҙеӨҡй«ҳиҙЁйҮҸзҡ„е®һз”Ёж–Үз« пјҒ





