这篇文章主要介绍TensorFlow中MNIST数据集的示例分析,文中介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们一定要看完!
MNIST 包含 0~9 的手写数字, 共有 60000 个训练集和 10000 个测试集. 数据的格式为单通道 28*28 的灰度图.
LeNet 网络最早由纽约大学的 Yann LeCun 等人于 1998 年提出, 也称 LeNet5. LeNet 是神经网络的鼻祖, 被誉为卷积神经网络的 “Hello World”.

from tensorflow.keras.datasets import mnist from matplotlib import pyplot as plt import numpy as np import tensorflow as tf
# ------------------1. 读取 & 查看数据------------------ # 读取数据 (X_train, y_train), (X_test, y_test) = mnist.load_data() # 数据集查看 print(X_train.shape) # (60000, 28, 28) print(y_train.shape) # (60000,) print(X_test.shape) # (10000, 28, 28) print(y_test.shape) # (10000,) print(type(X_train)) # <class 'numpy.ndarray'> # 图片显示 plt.imshow(X_train[0], cmap="Greys") # 查看第一张图片 plt.show()
# ------------------2. 数据预处理------------------ # 格式转换 (将图片从28*28扩充为32*32) X_train = np.pad(X_train, ((0, 0), (2, 2), (2, 2)), "constant", constant_values=0) X_test = np.pad(X_test, ((0, 0), (2, 2), (2, 2)), "constant", constant_values=0) print(X_train.shape) # (60000, 32, 32) print(X_test.shape) # (10000, 32, 32) # 数据集格式变换 X_train = X_train.astype(np.float32) X_test = X_test.astype(np.float32) # 数据正则化 X_train /= 255 X_test /= 255 # 数据维度转换 X_train = np.expand_dims(X_train, axis=-1) X_test = np.expand_dims(X_test, axis=-1) print(X_train.shape) # (60000, 32, 32, 1) print(X_test.shape) # (10000, 32, 32, 1)
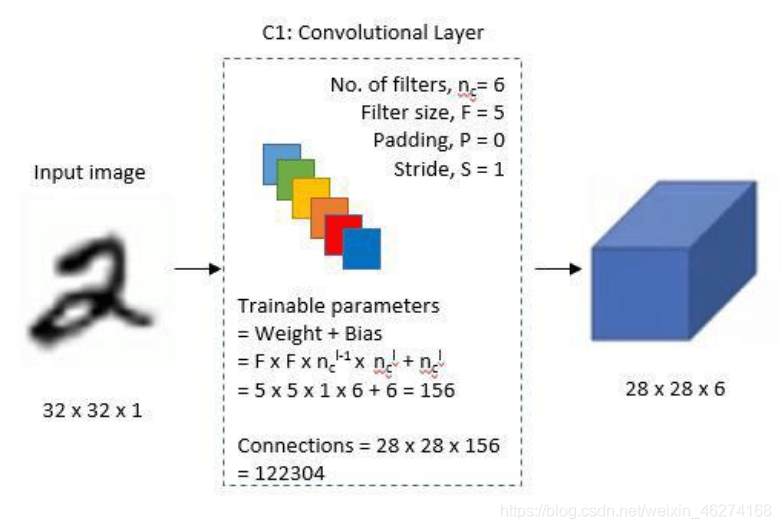
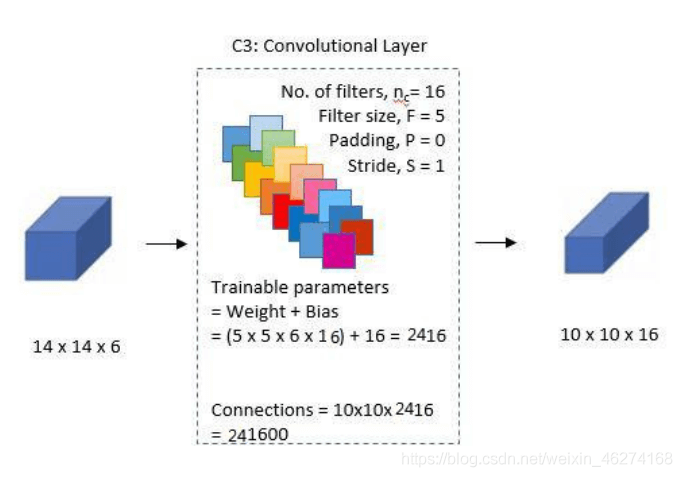
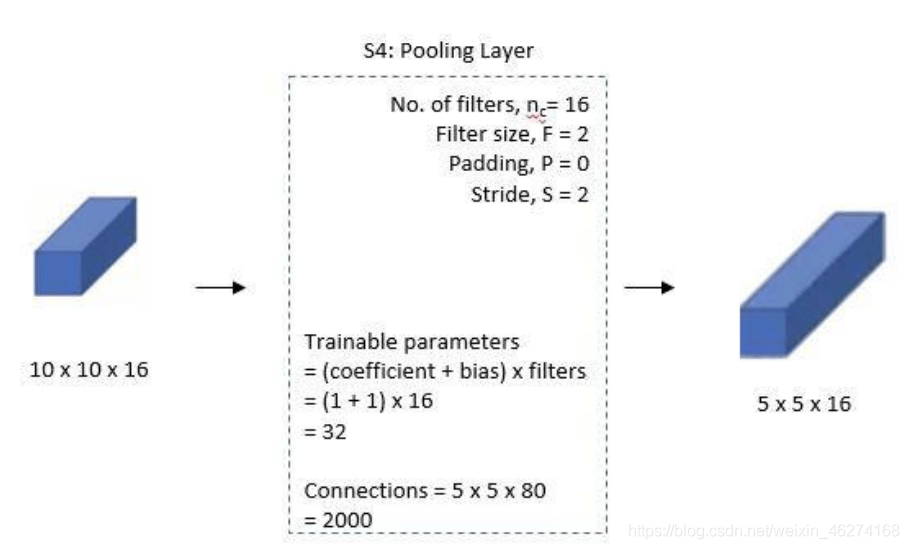
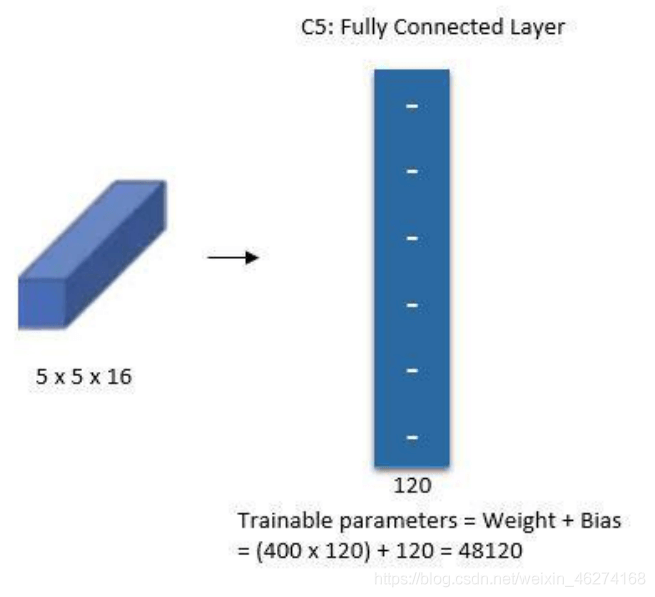
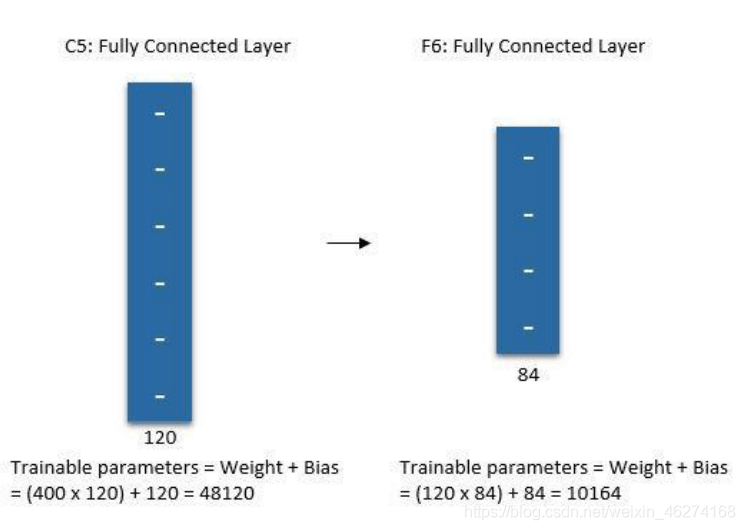
# 第一个卷积层 conv_layer_1 = tf.keras.layers.Conv2D(filters=6, kernel_size=(5, 5), padding="valid", activation=tf.nn.relu) # 第一个池化层 pool_layer_1 = tf.keras.layers.MaxPool2D(pool_size=(2, 2), padding="same") # 第二个卷积层 conv_layer_2 = tf.keras.layers.Conv2D(filters=16, kernel_size=(5, 5), padding="valid", activation=tf.nn.relu) # 第二个池化层 pool_layer_2 = tf.keras.layers.MaxPool2D(padding="same") # 扁平化 flatten = tf.keras.layers.Flatten() # 第一个全连接层 fc_layer_1 = tf.keras.layers.Dense(units=120, activation=tf.nn.relu) # 第二个全连接层 fc_layer_2 = tf.keras.layers.Dense(units=84, activation=tf.nn.softmax) # 输出层 output_layer = tf.keras.layers.Dense(units=10, activation=tf.nn.softmax)
卷积 Conv2D 的用法:
filters: 卷积核个数
kernel_size: 卷积核大小
strides = (1, 1): 步长
padding = “vaild”: valid 为舍弃, same 为补齐
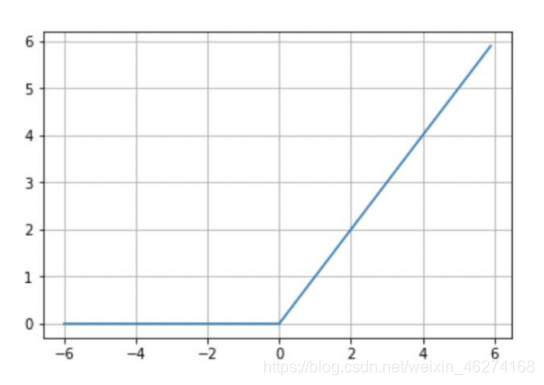
activation = tf.nn.relu: 激活函数
data_format = None: 默认 channels_last
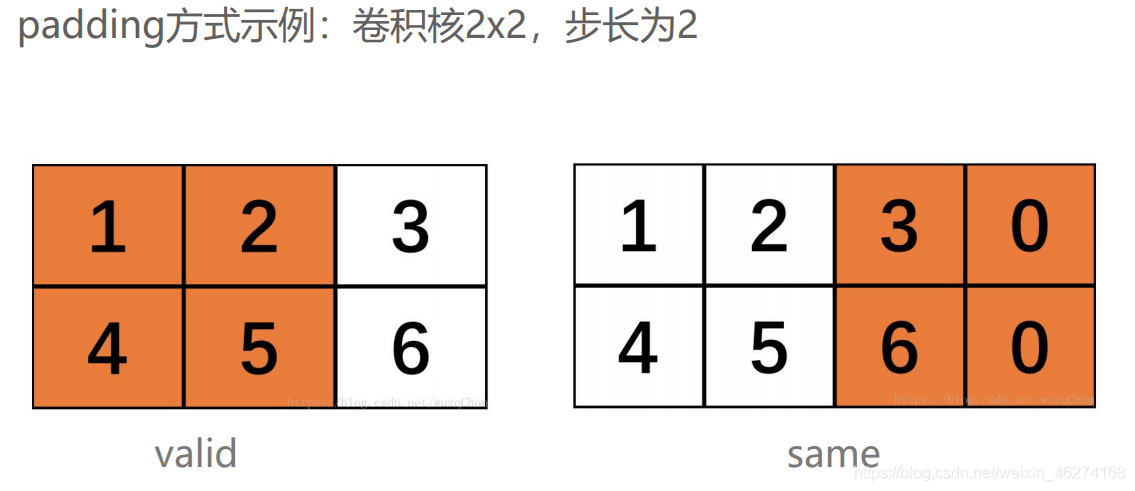
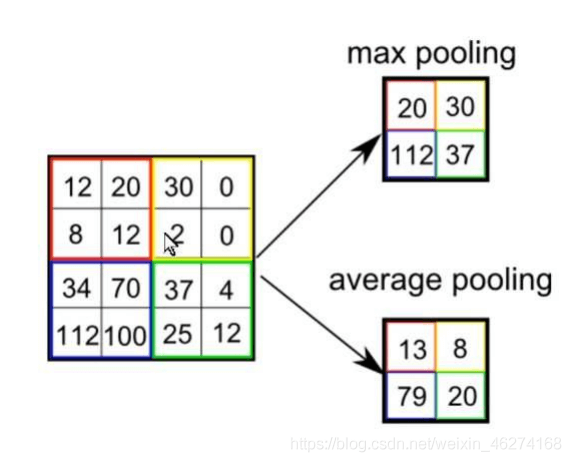
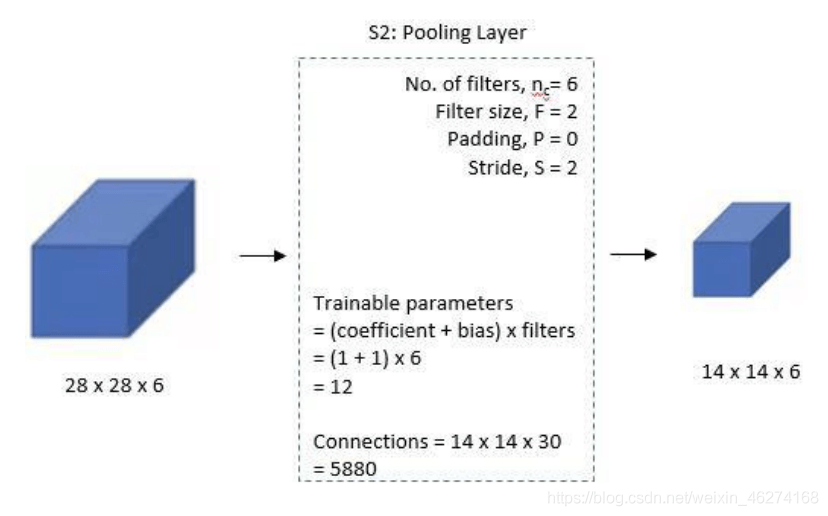
池化 AveragePooling2D 的用法:
pool_size: 池的大小
strides = (1, 1): 步长
padding = “vaild”: valid 为舍弃, same 为补齐
activation = tf.nn.relu: 激活函数
data_format = None: 默认 channels_last
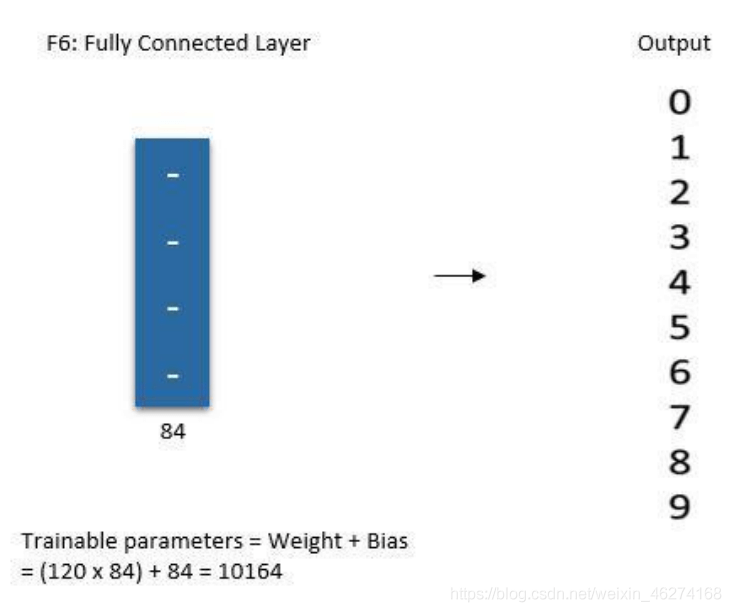
全连接 Dense 的用法:
units: 输出的维度
activation: 激活函数
strides = (1, 1): 步长
padding = “vaild”: valid 为舍弃, same 为补齐
activation = tf.nn.relu: 激活函数
data_format = None: 默认 channels_last
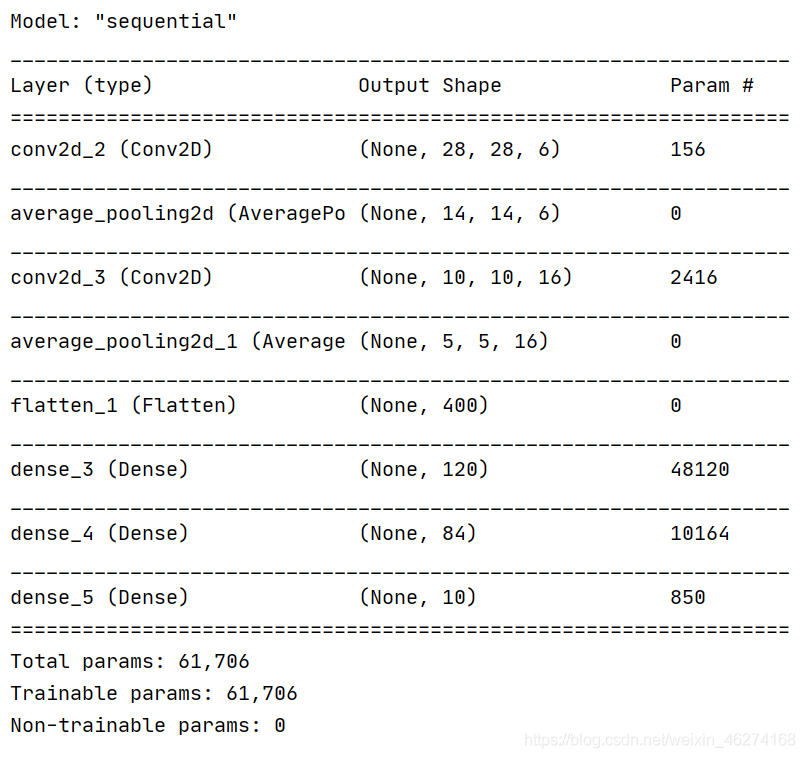
# 模型实例化 model = tf.keras.models.Sequential([ tf.keras.layers.Conv2D(filters=6, kernel_size=(5, 5), padding='valid', activation=tf.nn.relu, input_shape=(32, 32, 1)), # relu tf.keras.layers.AveragePooling2D(pool_size=(2, 2), strides=(2, 2), padding='same'), tf.keras.layers.Conv2D(filters=16, kernel_size=(5, 5), padding='valid', activation=tf.nn.relu), tf.keras.layers.AveragePooling2D(pool_size=(2, 2), strides=(2, 2), padding='same'), tf.keras.layers.Flatten(), tf.keras.layers.Dense(units=120, activation=tf.nn.relu), tf.keras.layers.Dense(units=84, activation=tf.nn.relu), tf.keras.layers.Dense(units=10, activation=tf.nn.softmax) ]) # 模型展示 model.summary()
输出结果:
# ------------------4. 训练模型------------------ # 设置超参数 num_epochs = 10 # 训练轮数 batch_size = 1000 # 批次大小 learning_rate = 0.001 # 学习率
# 定义优化器 adam_optimizer = tf.keras.optimizers.Adam(learning_rate) model.compile(optimizer=adam_optimizer,loss=tf.keras.losses.sparse_categorical_crossentropy,metrics=['accuracy'])
complie 的用法:
optimizer: 优化器
loss: 损失函数
metrics: 评价
with tf.Session() as sess: # 初始化所有变量 init = tf.global_variables_initializer() sess.run(init) model.fit(x=X_train,y=y_train,batch_size=batch_size,epochs=num_epochs) # 评估指标 print(model.evaluate(X_test, y_test)) # loss value & metrics values
输出结果:

fit 的用法:
x: 训练集
y: 测试集
batch_size: 批次大小
enpochs: 训练遍数
# ------------------5. 保存模型------------------
model.save('lenet_model.h6')
from tensorflow.keras.datasets import mnist
from matplotlib import pyplot as plt
import numpy as np
import tensorflow as tf
# ------------------1. 读取 & 查看数据------------------
# 读取数据
(X_train, y_train), (X_test, y_test) = mnist.load_data()
# 数据集查看
print(X_train.shape) # (60000, 28, 28)
print(y_train.shape) # (60000,)
print(X_test.shape) # (10000, 28, 28)
print(y_test.shape) # (10000,)
print(type(X_train)) # <class 'numpy.ndarray'>
# 图片显示
plt.imshow(X_train[0], cmap="Greys") # 查看第一张图片
plt.show()
# ------------------2. 数据预处理------------------
# 格式转换 (将图片从28*28扩充为32*32)
X_train = np.pad(X_train, ((0, 0), (2, 2), (2, 2)), "constant", constant_values=0)
X_test = np.pad(X_test, ((0, 0), (2, 2), (2, 2)), "constant", constant_values=0)
print(X_train.shape) # (60000, 32, 32)
print(X_test.shape) # (10000, 32, 32)
# 数据集格式变换
X_train = X_train.astype(np.float32)
X_test = X_test.astype(np.float32)
# 数据正则化
X_train /= 255
X_test /= 255
# 数据维度转换
X_train = np.expand_dims(X_train, axis=-1)
X_test = np.expand_dims(X_test, axis=-1)
print(X_train.shape) # (60000, 32, 32, 1)
print(X_test.shape) # (10000, 32, 32, 1)
# ------------------3. 模型建立------------------
# 第一个卷积层
conv_layer_1 = tf.keras.layers.Conv2D(filters=6, kernel_size=(5, 5), padding="valid", activation=tf.nn.relu)
# 第一个池化层
pool_layer_1 = tf.keras.layers.MaxPool2D(pool_size=(2, 2), padding="same")
# 第二个卷积层
conv_layer_2 = tf.keras.layers.Conv2D(filters=16, kernel_size=(5, 5), padding="valid", activation=tf.nn.relu)
# 第二个池化层
pool_layer_2 = tf.keras.layers.MaxPool2D(padding="same")
# 扁平化
flatten = tf.keras.layers.Flatten()
# 第一个全连接层
fc_layer_1 = tf.keras.layers.Dense(units=120, activation=tf.nn.relu)
# 第二个全连接层
fc_layer_2 = tf.keras.layers.Dense(units=84, activation=tf.nn.softmax)
# 输出层
output_layer = tf.keras.layers.Dense(units=10, activation=tf.nn.softmax)
# 模型实例化
model = tf.keras.models.Sequential([
tf.keras.layers.Conv2D(filters=6, kernel_size=(5, 5), padding='valid', activation=tf.nn.relu,
input_shape=(32, 32, 1)),
# relu
tf.keras.layers.AveragePooling2D(pool_size=(2, 2), strides=(2, 2), padding='same'),
tf.keras.layers.Conv2D(filters=16, kernel_size=(5, 5), padding='valid', activation=tf.nn.relu),
tf.keras.layers.AveragePooling2D(pool_size=(2, 2), strides=(2, 2), padding='same'),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(units=120, activation=tf.nn.relu),
tf.keras.layers.Dense(units=84, activation=tf.nn.relu),
tf.keras.layers.Dense(units=10, activation=tf.nn.softmax)
])
# 模型展示
model.summary()
# ------------------4. 训练模型------------------
# 设置超参数
num_epochs = 10 # 训练轮数
batch_size = 1000 # 批次大小
learning_rate = 0.001 # 学习率
# 定义优化器
adam_optimizer = tf.keras.optimizers.Adam(learning_rate)
model.compile(optimizer=adam_optimizer,loss=tf.keras.losses.sparse_categorical_crossentropy,metrics=['accuracy'])
with tf.Session() as sess:
# 初始化所有变量
init = tf.global_variables_initializer()
sess.run(init)
model.fit(x=X_train,y=y_train,batch_size=batch_size,epochs=num_epochs)
# 评估指标
print(model.evaluate(X_test, y_test)) # loss value & metrics values
# ------------------5. 保存模型------------------
model.save('lenet_model.h6')以上是“TensorFlow中MNIST数据集的示例分析”这篇文章的所有内容,感谢各位的阅读!希望分享的内容对大家有帮助,更多相关知识,欢迎关注亿速云行业资讯频道!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





