这篇文章主要介绍“JS的高级技巧总结”,在日常操作中,相信很多人在JS的高级技巧总结问题上存在疑惑,小编查阅了各式资料,整理出简单好用的操作方法,希望对大家解答”JS的高级技巧总结”的疑惑有所帮助!接下来,请跟着小编一起来学习吧!
这个问题是怎么安全地检测一个变量的类型,例如判断一个变量是否为一个数组。通常的做法是使用instanceof,如下代码所示:
let data = [1, 2, 3]; console.log(data instanceof Array); //true
但是上面的判断在一定条件下会失败——就是在iframe里面判断一个父窗口的变量的时候。写个demo验证一下,如下主页面的main.html:
<script>
window.global = {
arrayData: [1, 2, 3]
}
console.log("parent arrayData installof Array: " +
(window.global.arrayData instanceof Array));
</script>
<iframe src="iframe.html"></iframe>在iframe.html判断一下父窗口的变量类型:
<script>
console.log("iframe window.parent.global.arrayData instanceof Array: " +
(window.parent.global.arrayData instanceof Array));
</script>在iframe里面使用window.parent得到父窗口的全局window对象,这个不管跨不跨域都没有问题,进而可以得到父窗口的变量,然后用instanceof判断。最后运行结果如下:

可以看到父窗口的判断是正确的,而子窗口的判断是false,因此一个变量明明是Array,但却不是Array,这是为什么呢?既然这个是父子窗口才会有的问题,于是试一下把Array改成父窗口的Array,即window.parent.Array,如下图所示:

这次返回了true,然后再变换一下其它的判断,如上图,最后可以知道根本原因是上图最后一个判断:
Array !== window.parent.Array
它们分别是两个函数,父窗口定义了一个,子窗口又定义了一个,内存地址不一样,内存地址不一样的Object等式判断不成立,而window.parent.arrayData.constructor返回的是父窗口的Array,比较的时候是在子窗口,使用的是子窗口的Array,这两个Array不相等,所以导致判断不成立。
那怎么办呢?
由于不能使用Object的内存地址判断,可以使用字符串的方式,因为字符串是基本类型,字符串比较只要每个字符都相等就好了。ES5提供了这么一个方法Object.prototype.toString,我们先小试牛刀,试一下不同变量的返回值:

可以看到如果是数组返回"[object Array]",ES5对这个函数是这么规定的:
ES5函数地址:https://262.ecma-international.org/5.1/#sec-15.2.4.2

也就是说这个函数的返回值是“[object”开头,后面带上变量类型的名称和右括号。因此既然它是一个标准语法规范,所以可以用这个函数安全地判断变量是不是数组。
可以这么写:
Object.prototype.toString.call([1, 2, 3]) === "[object Array]"
注意要使用call,而不是直接调用,call的第一个参数是context执行上下文,把数组传给它作为执行上下文。
有一个比较有趣的现象是ES6的class也是返回function:

所以可以知道class也是用function实现的原型,也就是说class和function本质上是一样的,只是写法上不一样。
那是不是说不能再使用instanceof判断变量类型了?不是的,当你需要检测父页面的变量类型就得使用这种方法,本页面的变量还是可以使用instanceof或者constructor的方法判断,只要你能确保这个变量不会跨页面。因为对于大多数人来说,很少会写iframe的代码,所以没有必要搞一个比较麻烦的方式,还是用简单的方式就好了。
有时候需要在代码里面做一些兼容性判断,或者是做一些UA的判断,如下代码所示:
//UA的类型
getUAType: function() {
let ua = window.navigator.userAgent;
if (ua.match(/renren/i)) {
return 0;
}
else if (ua.match(/MicroMessenger/i)) {
return 1;
}
else if (ua.match(/weibo/i)) {
return 2;
}
return -1;
}这个函数的作用是判断用户是在哪个环境打开的网页,以便于统计哪个渠道的效果比较好。
这种类型的判断都有一个特点,就是它的结果是死的,不管执行判断多少次,都会返回相同的结果,例如用户的UA在这个网页不可能会发生变化(除了调试设定的之外)。所以为了优化,才有了惰性函数一说,上面的代码可以改成:
//UA的类型
getUAType: function() {
let ua = window.navigator.userAgent;
if(ua.match(/renren/i)) {
pageData.getUAType = () => 0;
return 0;
}
else if(ua.match(/MicroMessenger/i)) {
pageData.getUAType = () => 1;
return 1;
}
else if(ua.match(/weibo/i)) {
pageData.getUAType = () => 2;
return 2;
}
return -1;
}在每次判断之后,把getUAType这个函数重新赋值,变成一个新的function,而这个function直接返回一个确定的变量,这样以后的每次获取都不用再判断了,这就是惰性函数的作用。你可能会说这么几个判断能优化多少时间呢,这么点时间对于用户来说几乎是没有区别的呀。确实如此,但是作为一个有追求的码农,还是会想办法尽可能优化自己的代码,而不是只是为了完成需求完成功能。并且当你的这些优化累积到一个量的时候就会发生质变。我上大学的时候C++的老师举了一个例子,说有个系统比较慢找她去看一下,其中她做的一个优化是把小数的双精度改成单精度,最后是快了不少。
但其实上面的例子我们有一个更简单的实现,那就是直接搞个变量存起来就好了:
let ua = window.navigator.userAgent; let UAType = ua.match(/renren/i) ? 0 : ua.match(/MicroMessenger/i) ? 1 : ua.match(/weibo/i) ? 2 : -1;
连函数都不用写了,缺点是即使没有使用到UAType这个变量,也会执行一次判断,但是我们认为这个变量被用到的概率还是很高的。
我们再举一个比较有用的例子,由于Safari的无痕浏览会禁掉本地存储,因此需要搞一个兼容性判断:
Data.localStorageEnabled = true;
// Safari的无痕浏览会禁用localStorage
try{
window.localStorage.trySetData = 1;
} catch(e) {
Data.localStorageEnabled = false;
}
setLocalData: function(key, value) {
if (Data.localStorageEnabled) {
window.localStorage[key] = value;
}
else {
util.setCookie("_L_" + key, value, 1000);
}
}在设置本地数据的时候,需要判断一下是不是支持本地存储,如果是的话就用localStorage,否则改用cookie。可以用惰性函数改造一下:
setLocalData: function(key, value) {
if(Data.localStorageEnabled) {
util.setLocalData = function(key, value){
return window.localStorage[key];
}
} else {
util.setLocalData = function(key, value){
return util.getCookie("_L_" + key);
}
}
return util.setLocalData(key, value);
}这里可以减少一次if/else的判断,但好像不是特别实惠,毕竟为了减少一次判断,引入了一个惰性函数的概念,所以你可能要权衡一下这种引入是否值得,如果有三五个判断应该还是比较好的。
有时候要把一个函数当作参数传递给另一个函数执行,此时函数的执行上下文往往会发生变化,如下代码:
class DrawTool {
constructor() {
this.points = [];
}
handleMouseClick(event) {
this.points.push(event.latLng);
}
init() {
$map.on('click', this.handleMouseClick);
}
}click事件的执行回调里面this不是指向了DrawTool的实例了,所以里面的this.points将会返回undefined。第一种解决方法是使用闭包,先把this缓存一下,变成that:
class DrawTool {
constructor() {
this.points = [];
}
handleMouseClick(event) {
this.points.push(event.latLng);
}
init() {
let that = this;
$map.on('click', event => that.handleMouseClick(event));
}
}由于回调函数是用that执行的,而that是指向DrawTool的实例子,因此就没有问题了。相反如果没有that它就用的this,所以就要看this指向哪里了。
因为我们用了箭头函数,而箭头函数的this还是指向父级的上下文,因此这里不用自己创建一个闭包,直接用this就可以:
init() { $map.on('click', event => this.handleMouseClick(event));}复制代码
这种方式更加简单,第二种方法是使用ES5的bind函数绑定,如下代码:
init() { $map.on('click', this.handleMouseClick.bind(this));}这个bind看起来好像很神奇,但其实只要一行代码就可以实现一个bind函数:
Function.prototype.bind = function(context) {
return () => this.call(context);
}就是返回一个函数,这个函数的this是指向的原始函数,然后让它call(context)绑定一下执行上下文就可以了。
柯里化就是函数和参数值结合产生一个新的函数,如下代码,假设有一个curry的函数:
function add(a, b) {
return a + b;
}
let add1 = add.curry(1);
console.log(add1(5)); // 6
console.log(add1(2)); // 3怎么实现这样一个curry的函数?它的重点是要返回一个函数,这个函数有一些闭包的变量记录了创建时的默认参数,然后执行这个返回函数的时候,把新传进来的参数和默认参数拼一下变成完整参数列表去调原本的函数,所以有了以下代码:
Function.prototype.curry = function() {
let defaultArgs = arguments;
let that = this;
return function() {
return that.apply(this,
defaultArgs.concat(arguments)); }};但是由于参数不是一个数组,没有concat函数,所以需要把伪数组转成一个伪数组,可以用Array.prototype.slice:
Function.prototype.curry = function() {
let slice = Array.prototype.slice;
let defaultArgs = slice.call(arguments);
let that = this;
return function() {
return that.apply(this,
defaultArgs.concat(slice.call(arguments))); }};现在举一下柯里化一个有用的例子,当需要把一个数组降序排序的时候,需要这样写:
let data = [1,5,2,3,10]; data.sort((a, b) => b - a); // [10, 5, 3, 2, 1]
给sort传一个函数的参数,但是如果你的降序操作比较多,每次都写一个函数参数还是有点烦的,因此可以用柯里化把这个参数固化起来:
Array.prototype.sortDescending = Array.prototype.sort.curry((a, b) => b - a);
这样就方便多了:
let data = [1,5,2,3,10]; data.sortDescending(); console.log(data); // [10, 5, 3, 2, 1]
有时候你可能怕你的对象被误改了,所以需要把它保护起来。
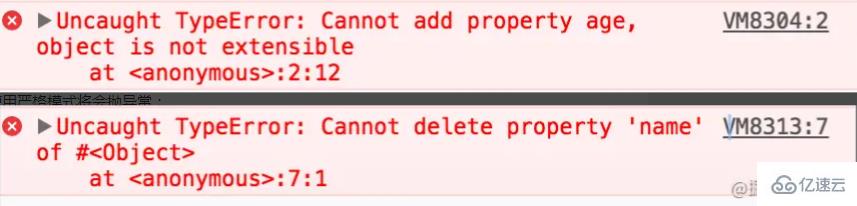
(1)Object.seal防止新增和删除属性
如下代码,当把一个对象seal之后,将不能添加和删除属性:

当使用严格模式将会抛异常:
(2)Object.freeze冻结对象
这个是不能改属性值,如下图所示:
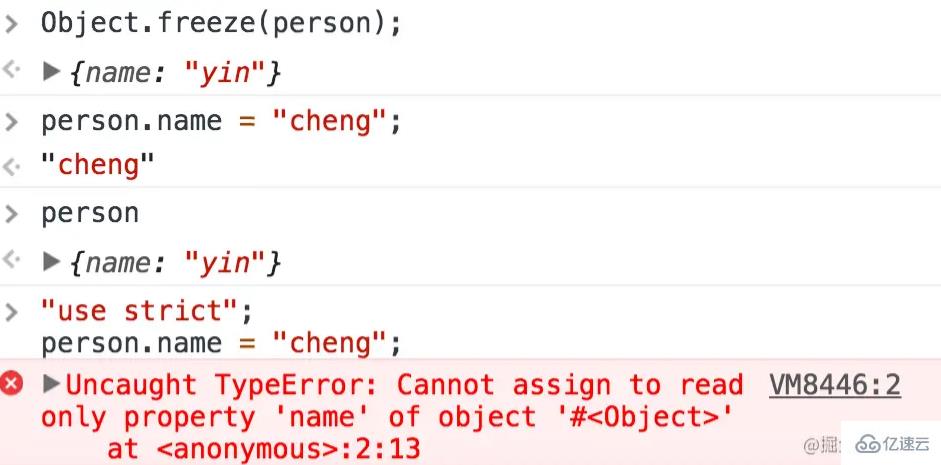
同时可以使用Object.isFrozen、Object.isSealed、Object.isExtensible判断当前对象的状态。
(3)defineProperty冻结单个属性
如下图所示,设置enumable/writable为false,那么这个属性将不可遍历和写:

怎么实现一个JS版的sleep函数?因为在C/C++/Java等语言是有sleep函数,但是JS没有。sleep函数的作用是让线程进入休眠,当到了指定时间后再重新唤起。你不能写个while循环然后不断地判断当前时间和开始时间的差值是不是到了指定时间了,因为这样会占用CPU,就不是休眠了。
这个实现比较简单,我们可以使用setTimeout + 回调:
function sleep(millionSeconds, callback) {
setTimeout(callback, millionSeconds);
}
// sleep 2秒
sleep(2000, () => console.log("sleep recover"));但是使用回调让我的代码不能够和平常的代码一样像瀑布流一样写下来,我得搞一个回调函数当作参数传值。于是想到了Promise,现在用Promise改写一下:
function sleep(millionSeconds) {
return new Promise(resolve =>
setTimeout(resolve, millionSeconds));
}
sleep(2000).then(() => console.log("sleep recover"));但好像还是没有办法解决上面的问题,仍然需要传递一个函数参数。
虽然使用Promise本质上是一样的,但是它有一个resolve的参数,方便你告诉它什么时候异步结束,然后它就可以执行then了,特别是在回调比较复杂的时候,使用Promise还是会更加的方便。
ES7新增了两个新的属性async/await用于处理的异步的情况,让异步代码的写法就像同步代码一样,如下async版本的sleep:
function sleep(millionSeconds) {
return new Promise(resolve =>
setTimeout(resolve, millionSeconds));
}
async function init() {
await sleep(2000);
console.log("sleep recover");
}
init();相对于简单的Promise版本,sleep的实现还是没变。不过在调用sleep的前面加一个await,这样只有sleep这个异步完成了,才会接着执行下面的代码。同时需要把代码逻辑包在一个async标记的函数里面,这个函数会返回一个Promise对象,当里面的异步都执行完了就可以then了:
init().then(() => console.log("init finished"));ES7的新属性让我们的代码更加地简洁优雅。
关于定时器还有一个很重要的话题,那就是setTimeout和setInterval的区别。如下图所示:
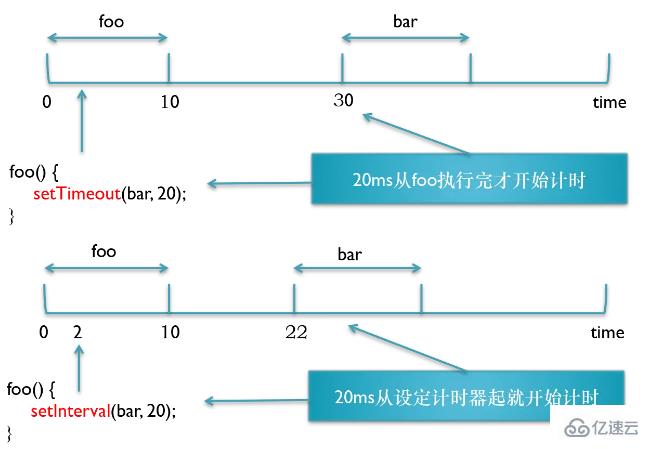
setTimeout是在当前执行单元都执行完才开始计时,而setInterval是在设定完计时器后就立马计时。可以用一个实际的例子做说明,这个例子我在《JS与多线程》这篇文章里面提到过,这里用代码实际地运行一下,如下代码所示:
let scriptBegin = Date.now();
fun1();
fun2();
// 需要执行20ms的工作单元
function act(functionName) {
console.log(functionName, Date.now() - scriptBegin);
let begin = Date.now();
while(Date.now() - begin < 20);
}
function fun1() {
let fun3 = () => act("fun3");
setTimeout(fun3, 0);
act("fun1");
}
function fun2() {
act("fun2 - 1");
var fun4 = () => act("fun4");
setInterval(fun4, 20);
act("fun2 - 2");
}这个代码的执行模型是这样的:
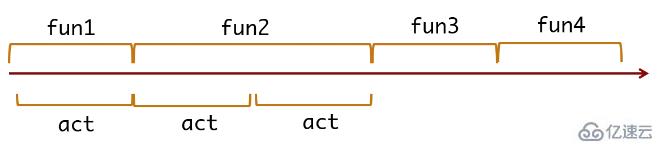
控制台输出:

与上面的模型分析一致。
接着再讨论最后一个话题,函数节流
节流的目的是为了不想触发执行得太快,如:
监听input触发搜索监听resize做响应式调整监听mousemove调整位置
我们先看一下,resize/mousemove事件1s种能触发多少次,于是写了以下驱动代码:
let begin = 0;
let count = 0;
window.onresize = function() {
count++;
let now = Date.now();
if (!begin) {
begin = now;
return;
}
if((now - begin) % 3000 < 60) {
console.log(now - begin,
count / (now - begin) * 1000);
}
};当把窗口拉得比较快的时候,resize事件大概是1s触发40次:
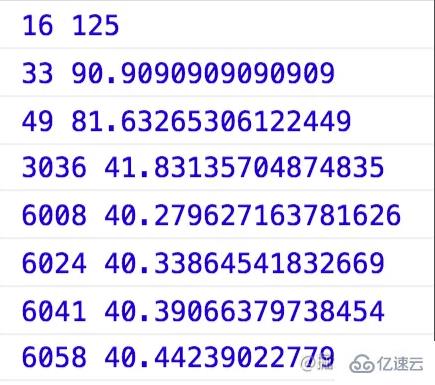
需要注意的是,并不是说你拉得越快,触发得就越快。实际情况是,拉得越快触发得越慢,因为拉动的时候页面需要重绘,变化得越快,重绘的次数也就越多,所以导致触发得更少了。
mousemove事件在我的电脑的Chrome上1s大概触发60次:
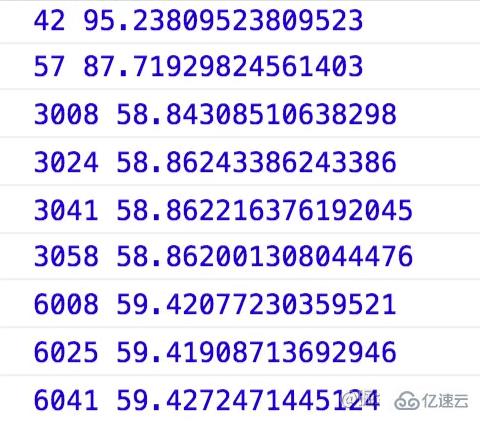
如果你需要监听resize事件做DOM调整的话,这个调整比较费时,1s要调整40次,这样可能会响应不过来,并且不需要调整得这么频繁,所以要节流。
怎么实现一个节流呢,书里是这么实现的:
function throttle(method, context) {
clearTimeout(method.tId);
method.tId = setTimeout(function() {
method.call(context);
}, 100);
}每次执行都要setTimeout一下,如果触发得很快就把上一次的setTimeout清掉重新setTimeout,这样就不会执行很快了。但是这样有个问题,就是这个回调函数可能永远不会执行,因为它一直在触发,一直在清掉tId,这样就有点尴尬,上面代码的本意应该是100ms内最多触发一次,而实际情况是可能永远不会执行。这种实现应该叫防抖,不是节流。
把上面的代码稍微改造一下:
function throttle(method, context) {
if (method.tId) {
return;
}
method.tId = setTimeout(function() {
method.call(context);
method.tId = 0;
}, 100);
}这个实现就是正确的,每100ms最多执行一次回调,原理是在setTimeout里面把tId给置成0,这样能让下一次的触发执行。实际实验一下:
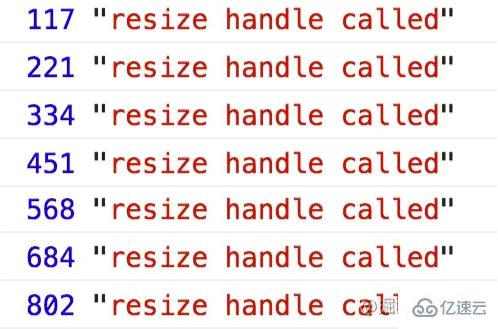
大概每100ms就执行一次,这样就达到我们的目的。
但是这样有一个小问题,就是每次执行都是要延迟100ms,有时候用户可能就是最大化了窗口,只触发了一次resize事件,但是这次还是得延迟100ms才能执行,假设你的时间是500ms,那就得延迟半秒,因此这个实现不太理想。
需要优化,如下代码所示:
function throttle(method, context) {
// 如果是第一次触发,立刻执行
if (typeof method.tId === "undefined") {
method.call(context);
}
if (method.tId) {
return;
}
method.tId = setTimeout(function() {
method.call(context);
method.tId = 0;
}, 100);
}先判断是否为第一次触发,如果是的话立刻执行。这样就解决了上面提到的问题,但是这个实现还是有问题,因为它只是全局的第一次,用户最大化之后,隔了一会又取消最大化了就又有延迟了,并且第一次触发会执行两次。那怎么办呢?
笔者想到了一个方法:
function throttle(method, context) {
if (!method.tId) {
method.call(context);
method.tId = 1;
setTimeout(() => method.tId = 0, 100);
}
}每次触发的时候立刻执行,然后再设定一个计时器,把tId置成0,实际的效果如下:
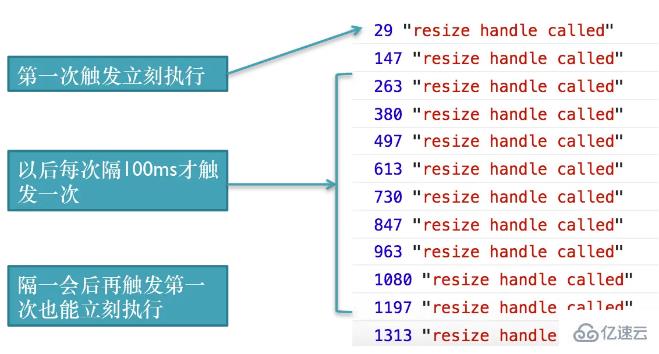
这个实现比之前的实现还要简洁,并且能够解决延迟的问题。
所以通过节流,把执行次数降到了1s执行10次,节流时间也可以控制,但同时失去了灵敏度,如果你需要高灵敏度就不应该使用节流,例如做一个拖拽的应用。如果拖拽节流了会怎么样?用户会发现拖起来一卡一卡的。
到此,关于“JS的高级技巧总结”的学习就结束了,希望能够解决大家的疑惑。理论与实践的搭配能更好的帮助大家学习,快去试试吧!若想继续学习更多相关知识,请继续关注亿速云网站,小编会继续努力为大家带来更多实用的文章!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





