namenode的文件存储
namenode数据存储分为两个文件,fsp_w_picpath与edits文件,edits文件记录了所有namenode的操作,相当于日志记录。fsp_w_picpath记录了namenode的数据。在namenode启动时,会加载fsp_w_picpath的数据到内存中,并从edits文件中解析所有数据信息到内存,两个数据合并后共同组成了namenode全量信息。
secondarynamenode的作用
secondarynamenode 按一定规则将edits文件和fsp_w_picpath文件合并,合并后namenode会启用新的edits文件,这样会减小edits文件的文件大小,控制edits文件的大小会减少namenode在启动阶段解析加载edits文件的时长。
secondarynamenode合并文件规则
配置 fs.checkpoint.period 执行检查点合并文件检查时间 默认3600s
fs.checkpoint.size 实行检查点合并文件阀值大小 默认64M
两个条件满足其一则合并文件
工作原理示意图
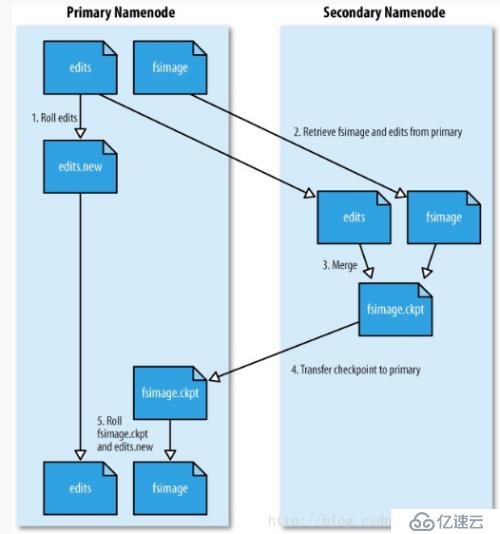
架构分析
fsp_w_picpath与edits文件对于namenode存储数据有什么区别,为什么要分开两个文件进行存储?
fsp_w_picpath存储着所有目录和文件的序列化信息,而edits保存了所有写或更新的信息,在namenode运行过程中只向edits文件中写相关的操作信息和文件信息
分两个文件存储是因为fsp_w_picpath由于保存了所有namenode的信息,所以文件大小通常比较大,这样在一个大的文件中进行写操作比较费系统资源而且延迟了系统的反应时间,而edits文件由于有secondarynamenode进行合并,通常大小要小于fsp_w_picpath,所以在edits文件中进行更新写操作会降低系统资源的消耗。
为什么会引入sencondarynamenode,只用namenode会有什么问题?
由于namenode进行分文件保存,但又不能使edits文件过大,所以需要进行文件合并,但进行文件合并会占用系统内存等资源,如果直接使用namenode进行文件合并,会导致在合并文件期间,系统文件管理能力下降卡顿等。另外由于secondarynamenode与namenode进行分离,可以将namenode和secondarynamenode分开部署到不同机器上,提高系统的稳定与安全性。除此之外,secondarynamenode由于进行了检查点,在namenode完全宕机数据丢失的情况下,secondarynamenode可以在检查点上恢复系统数据,当然,也会造成检查点之后的数据丢失。
-----史龙刚
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





