前言
今天老K继续与大家分享第九期。
周末老K宅在家观战了两局精彩的“人狗”大战。老K既算不上科技迷,也算不上围棋迷,不过对此颇有感触:阿尔法狗不过是通过左右互博的方式不断学习围棋,然而依赖其最优的学习算法(学习方法)却能再短短的数月之内达到人类围棋水平的最顶端;而李世石在却是依赖其已有的经验结合人类特有的灵感下出“神之一手”,人类终究还是可以战胜拥有超强计算能力的阿尔法狗。这些不禁让老K想起了自己在工作过程中的最有艺术性的部分---“SQL tunning”,一方面要不断学习积累运用不同的优化方法,同时在必要时多一分想象力和灵感,这样面对不同的SQL问题,我们才能下出自己的“神之一手”。
好了,今天老K与大家分享的案例是SQL调优的案例,但老K更希望大家能从中体会到SQL tunning过程中的优化方法和思维方式,真正做到它山之石,可以攻玉。同时,大家如果觉得老K的方法还不错,不妨轻轻的转发一下,分享给身边更多的ORACLE技术爱好者。
今天分析的问题是客户DBA给过来的一条SQL语句,已经困扰其一段时间了,希望老K一起来分析解决。解决这个问题对老K来说并不是特别难,不过在这个问题的分析过程中,老K给出了几种优化的方向,最终选择了不论是对整个系统还是对该条SQL都可谓最佳的一种方式,最后在测试环境执行效果非常不错。
Part 1
摆问题、列信息
对于SQL tunning,老K上手最先关注的是SQL文本、执行计划和执行统计信息,当然也不要忘了关注一下系统/数据库版本。
操作系统 AIX 6.1
数据库 ORACLE 11.2.0.3 两节点RAC

信息都在这了,我们要关注些什么呢?老K的经验是,先找特征,再根据不同的特征来进一步提取自己需要的信息。
Part 2
找特征、补信息
>> exists子句 (part1)和update set部分(part2)的sql代码基本相同,如下图;
>> part1部分中,标量子查询的结果作为set列的目标值,说明从业务逻辑上能保证该部查询返回记录数最多为1;

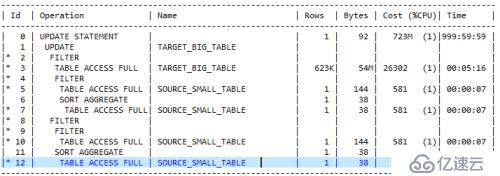
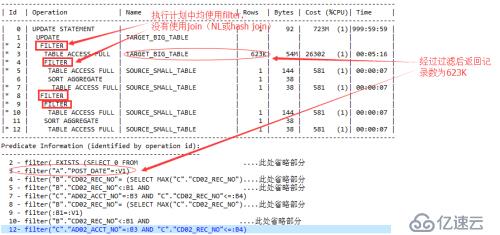
>> 该执行计划各过程均使用filter
>> 结合sql文本及predicate information可以看到,对目标表TARGET_BIG_TABLE经过滤条件POST_DATE=:V1后,返回记录数预估为623K条。
>> TARGET_BIG_TABLE大约2G大小,SOURCE_SMALL_TABLE大约3M 大小;
>> TARGET_BIG_TABLE表中记录数约250W左右,统计信息估算POST_DATE过滤后返回623K条记录,注意:这是预估值,实际值会随着传入的变量V1而变化。
>> SOURCE_SMALL_TABLE表中记录数约12W左右,ad02_acct_no列的选择度比较高;
注:TARGET_BIG_TABLE简称为T表 SOURCE_SMALL_TABLE 简称为S表
另注:解读关键----理解执行计划中的filter
>> 执行计划分开成两部分来看,其中ID2-7步表示对应SQL文本的part2部分,ID8-12步对应SQL文本的part1部分;
>> part2部分的过程:使用POST_DATE过滤T表,将过滤后的记录迭代入EXISTS子查询(T表的结果集此时作为变量传入子查询),在子查询执行的过程中,如果前面的关联条件符合,再次迭代入第二层子查询(select max()部分)进行匹配;
>> part1部分的过程:针对ID2-7步过滤出的结果集,逐条update,而update的目标值,同样是通过类似2-7步过程中的逐步迭代查询而来;
>> 在各步骤单表访问方式均为全表扫描;
>> 从执行计划中可以看到,在第3步对表T表进行过滤之后结果集估算为623K(rows列),其后对S表过滤后均为1;
>> 由此可以估算执行过程中表访问的情况应为:(老K建议在本分享中记住下面的公式,暂且称之为 “ 访问公式 ” 吧)
过滤过程的表访问=(T表全扫+ 623K 次 ×(S表全扫 +(0或者 1次)×(S表全扫)))
修改过程的表访问=(需要修改的记录数 ×(S表全扫 + (0或者 1次)×(S表全扫)))
总的访问过程=过滤过程的表访问次数 +修改过程的表访问
注意:此处的(0或者 1次)×(S表全扫)表示的是第二层子查询的情况,如果在第一层子查询过程中关联条件就不符合,则不再需要迭代入第二层,即0次S表全扫,否则即是1次S表全扫;所以过滤过程对S表最少需要做623K次全扫,最多需要做1246K次全扫;修改过程同理。
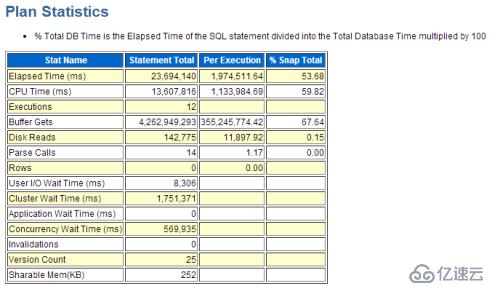
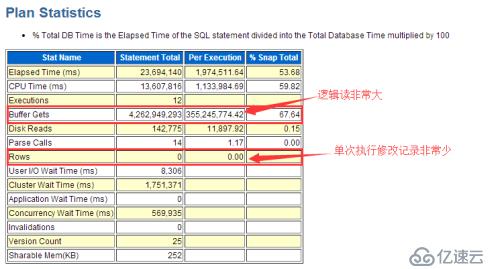
>> SQL单次执行平均逻辑读为355,245,774(block数)
>> SQL单次执行平均时间约2000秒
>> SQL单次平均修改记录数约为0条
Part 3
思考吧DBA
好了,信息收集完成了,进入老K的既定思考轨道,其实对于任何一个SQL tunning的问题,老K都会提出下面的三个问题,这个也不用例外;
>> 这个执行计划是否为当前SQL语句下最优的执行计划?(选择优化目标)
>> 我们想要的执行计划是什么样的?(确定优化目标)
>> 我们怎么来让SQL跑出我们想要的执行计划?(实现优化目标)
如果可以,正在阅读此文的你,也许也可以思考一下上面的三个问题,或者回忆一下当你面对SQL tunning的问题时你有没有思考过这三个问题,亦或者你会思考/思考过什么呢。
综合前期的分析思考片刻之后,老K郑重地给出了自己的答案:
老K先查看过该SQL的历史执行计划,只有这一个,但这并不意味着着就是该SQL的最优执行计划;
在执行计划解读部分,老K给出了这个执行计划的“访问公式”,从公式中可以知道其实S表虽小,但其实际上是整个执行计划的关键,整个过程中最多可能需要对S表进行1246K×2次访问呢,那我们可不可以提高对S表的访问效率呢?当然可以,从执行计划中的估算可以知道对S表的访问大约返回1-2条记录(这里老K还单独验证过),说明整体选择度比较高,我们只有创建合适的索引,就可以就可以大大将提高S表的访问效率。
我们简单来估算一下使用索引的情况下的执行效率是怎样的。原来对S表全扫所需的逻辑读数为3M(表大小)÷8192=375次,使用索引后预估对S表一次访问最多所需逻辑读数为:(2次索引块访问 + 2次数据块访问)=4次;所以说,使用索引的逻辑读约为使用全扫的的1%,估算创建索引后该语句单次执行平均逻辑读约在350w左右。
那么,新建索引,将S表的全扫都变为索引扫描,这就是老K想要的执行计划吗?
显然不是,这样的执行计划只是原执行计划的一个升级版而已,其过程还是一个迭代的过程,这样执行的时间/消耗的时间基本都会随着原计划中第3步返回的数据量(还记得623K这个值吗,就是它!它是可变的,可能随着传入的)变化而线性变化;所以这个执行计划虽然较原执行计划预计会有非常大的改善,但仍然不是老K想要的执行计划。
SQL文本告诉我们,其实SQL做的就是使用exists方式将T表和S表进行关联更新,老K想要的执行计划应该是使用NL或者hash join的方式来连接两表,而不是使用filter迭代的方式,这样就能保证SQL执行过程中只需要对T表和S表进行极少的一次或几次扫描,从而降低SQL执行的逻辑读。
要回答这个问题,我们首先要思考为什么SQL当前没有跑出我们想要的执行计划,是因为统计信息不准?索引设计不合理?还是列类型不匹配?
都不是!
我们再次回到SQL语句本身,来看看SQL语句的特别之处。
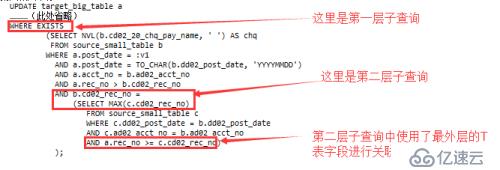
在这里,我们看到了问题的关键,正是因为最外层的T表与两层子查询均有关联关系,导致ORACLE无法自动改写SQL,最终生成执行计划时无法使用T表与S表进行JOIN,只能生成使用filter方式的执行计划。
所以,最终思考的结果已经出来:
>> 因为两层子查询的原因导致ORACLE无法使用JOIN的方式关联T表和S表
>> 要想生成较好的执行计划必须改写语句
>> 改写后的语句不应该存在类似的最外层表涉及第二层子查询的情况
其中最后一点,指出了我们改写的关键点。
Part 4
改写吧DBA
依据老K的经验,SQL语句的改写通常要求改写者对SQL涉及业务非常了解,通过业务特征重构出合理的SQL语句,才能更好的做到既不改变SQL的业务逻辑,又有效提高SQL性能;不过针对这个SQL,我们已经知道了导致其执行计划不优的根本原因,老K相信可以在不考虑业务特性的情况,利用数据库的特性来进行有效的改写。
基于SQL特性中,part1和part2基本相同的特性,老K先随性的对SQL做了如下改写(当然没有针对前面提到的改写关键点);
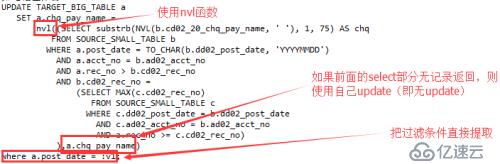
这一改写方式的几个关键点:
>> 先把post_date字段的过滤条件直接提取出来,与原逻辑一致
>> 基于part1和part2基本相同,使用了nvl函数代替了原来的exists子句
>> 如果select部分能查到记录(类似原来的exists子句成立),则用查询出的结果更新chq_pay_name字段
>> 如果select部分不能查到记录,则用原记录自身进行更新(set chq_pay_name=chq_pay_name),更新前后该记录的数据不变
以上几点保证了改写后的SQL与原SQL逻辑一致,不过有一点不一样的非常值得注意,原SQL只修改极少的几条记录,新SQL却修改了623K条记录,只是其中绝大多数是冗余的修改。
我们再看改写后的SQL执行计划:
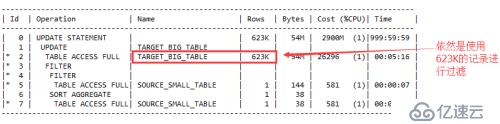
与原SQL执行计划类似,不过少了原执行计划的part1部分。
新的执行计划,老K又问了自己一句:
大家是否还记得原执行计划解析过程中老K给出的“访问公式”:
总的访问过程=过滤过程的表访问次数 +修改过程的表访问
那么,在这个执行计划下,因为去掉了冗余的一部分,公式就变成了:
总的访问过程=过滤过程的表访问次数
实际上就可以理解为,SQL在修改数据的过程中可以重用过滤过程中生成的数据;
不过针对这个语句,我们从执行统计信息里知道,每次语句执行最终修改的数据量都非常少,也就是说这样改写所减少的“修改过程的表访问”对整体执行效率影响并不大。
这样改写会带来什么坏处吗?
会!根本原因就在于上面提到的新SQL实际修改的记录数是623K条:
>> 持有行锁范围变大,可能大量导致其他对该表进行DML操作的会话被阻塞
>> 如果修改列上有索引,索引维护的时间将大大增加,导致新SQL执行效率更低
综上,针对这条SQL语句,这种改写方式并不合适。
不过,如果原SQL在执行过程中修改的数据量接近623K条,那么这种改写方式的收益就要高非常多,而其带来的坏处也就不复存在了,这种改写方式只是不适合这种业务环境下(每次只修改极少几条记录),然而却有一定的普遍性,所以老K也把这部分分享给大家,最重要的是解决问题过程中的思路和方法。
前面我们已经分析出改写的关键点:改写后的语句不应该存在类似的最外层表涉及第二层子查询的情况;下面我们就朝着这个目标去改写我们的SQL语句。
改写前信息补充:
改写思路在老K脑中酝酿好后,老K又补查了T表的信息,确认T表存在主键约束,主键列为ACCT_NO和JRNL_NO;
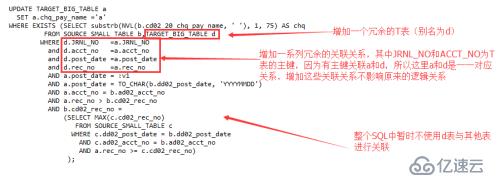
>> 在exists子句中增加一个冗余的T表,别名为d
>> 增加d表和a表的关联关系,其中jrnl_no列和acct_no列组合为T表的主键,其他冗余列的关联主要为下一步继续的改写作铺垫;
>> 整个SQL语句中没有使用d表与其他表进行关联;
>> 由于d表和a表使用的是主键进行关联,所以能确保对a表的每条记录,都能从d中找到且只能找到一条记录符合语句中的关联关系;
综上,可以知道上述增加冗余完全不改变SQL的逻辑关系。
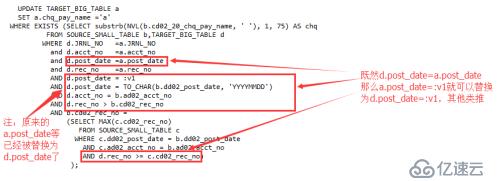
基于第一步冗余等价关系,将exists子句中的所有a与b、c的关联关系替换为d与b、c的关联关系。
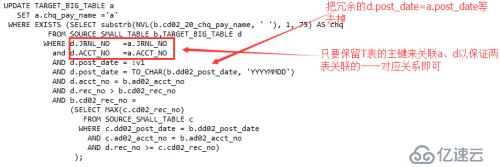
因为主键a、d的主键列值相等,即可保证a、d的其他列值必然相等,所以a、d的关联字段只需要保留主键字段即可(保留也是可以的,去掉显得更简洁)
以上一步一步的改写保证了逻辑的一致性,同时实现了最外层的T表不再涉及第二层子查询的关联,我们可以推断执行计划应该与老K预期的相差不远了:
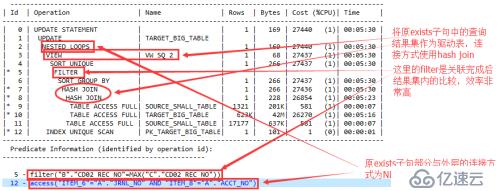
>> 执行计划中b、d、c表使用hash join进行关联
>> join完成后通过一系列SORT/FILTER后形成结果集VW_SQ_2,其中这里的filter部分为结果集内部的比较(即同一条记录的不同列的比较),效率非常高
>> 最后VW_SQ_2和外层的T表使用NL的方式进行join,关联字段为主键字段
执行计划出来以后,我们来估算一下这个SQL在执行过程中的“访问公式”:
总的访问过程 = S表全扫 + T表全扫 + S表全扫 + VW_SQ_2记录数 *(1个T表主键索引块 + 1个T表数据块)
原语句的part2部分修改的跟老K预期的差不多,原语句part1部分与part2部分一致,那么我们简单的修改part1部分成part2部分就可以了吗?显然不是!通常,使用merge into语句能很方便的改写update语句,这里我们更能利用原语句part1和part2一致的特性,改写如下:
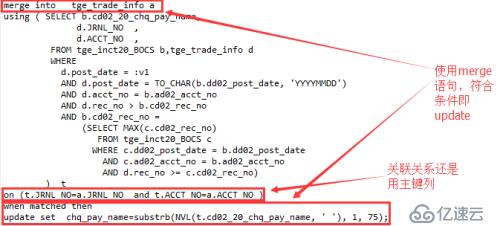
>> 将语句改写为merge into的方式;
>> Merge的源与上一步改写的exists子句中的内容一致,只是把与a的关联关系提取到merge语句的on 部分;
>> 这样改写后SQL执行过程中也会锁定需要修改的极少记录。
这里改写后的执行计划与前面的update语句类似,老K也就不单独列出分析了。
Part 5
最后的总览
最后我们再来看看我们改写后的语句及其执行计划:
语句如下:
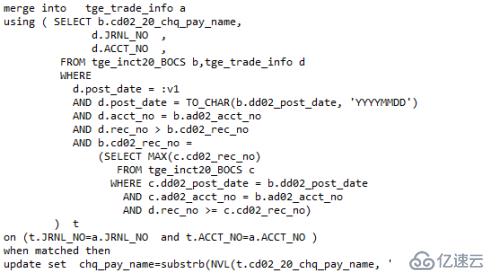
最终的执行计划:
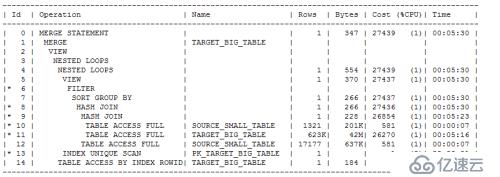
最终测试效果:

在测试环境,改写后的语句执行了两次,每次平均修改7.5条记录,耗时4s,逻辑读3.4w;细心的读者可能能从最终的执行计划中看到,对T表的全表扫描也许可以避免等,由于篇幅原因以及测试环境的原因,老K没有再在这里深究,毕竟老K分享的是SQL tuning的方法,而如何避免全表扫描以及如何分析避免了全表扫描后对SQL执行效率提升的预估,相信读者你一定已经学到了,不妨自己做一个估算。
写在最后
读到了最后,老K分享了什么,我们不妨来仔细回忆一番。
>> SQL分析过程中如何通过执行计划推算SQL执行的逻辑读
>> 针对CASE中的SQL如何通过添加索引来改善其执行效率
>> 针对CASE中的SQL通过使用NVL的方式进行改写,它在什么场景下是合适的,什么情况下是不合适的。
>> 怎样通过添加冗余关联来引导数据库生成我们想要的执行计划
>> 怎样使用merge语法来改写update语句
最后,老K再一次强调,在SQLtunning的过程中最重要的是优化的思路和对问题的思考方式,希望聪明的读者已从这次分享中得到启示。
编外:老K后来通过与应用开发团队沟通了解文中SQL的业务特征后,再次结合其业务特征改写了SQL,执行效率再次得到了极大的提升,可见,在SQLtunning的过程中,了解业务确实是非常重要的一环。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





