这篇文章主要介绍“Python文件操作的方法是什么”,在日常操作中,相信很多人在Python文件操作的方法是什么问题上存在疑惑,小编查阅了各式资料,整理出简单好用的操作方法,希望对大家解答”Python文件操作的方法是什么”的疑惑有所帮助!接下来,请跟着小编一起来学习吧!
字典的相关函数
# ### 字典的相关函数
dic = {}
# 增
# 1.普通方法 (推荐)
dic["top"] = "369"
dic["middle"] = "左手"
dic["bottom"] = "杰克爱"
print(dic)
# 2.fromkeys 使用一组键和默认值创建字典
tup = ("a","b","c")
# fromkeys(盛放键的容器,默认值)
dic = {}.fromkeys(tup,None)
print(dic)
# 注意点 (字典中的三个键默认指向的是同一个列表)
dic= {}.fromkeys(tup,[])
print(dic)
dic["a"].append(1)
print(dic)
# 改造
dic = {}
dic["top"] = []
dic["middle"] = []
dic["bottom"] = []
dic["top"].append("the boy")
print(dic)
# 删
dic = {'top': '369', 'middle': '左手', 'bottom': '杰克爱'}
#pop() 通过键去删除键值对 (若没有该键可设置默认值,预防报错)
res = dic.pop("middle")
print(res)
print(dic)
# 可以给pop设置第二个参数值,以防止键不存在时报错
res = dic.pop("middle1234","该键不存在")
print(res)
#popitem() 删除最后一个键值对
dic = {'top': '369', 'middle': '左手', 'bottom': '杰克爱'}
res = dic.popitem()
print(res)
print(dic)
#clear() 清空字典
dic.clear()
print(dic)
# 改
#update() 批量更新(有该键就更新,没该键就添加)
# 推荐使用
# 没该键就添加
dic_new = {"jungle":"karsa","support":"宝蓝"}
dic = {'top': '369', 'middle': '左手', 'bottom': '杰克爱'}
dic.update(dic_new)
print(dic)
# 有该键就更新
dic_new = {"top":"the bug","support":"xboyww","xiaozhang":"王思聪"}
dic.update(dic_new)
print(dic)
# (了解)
dic.update(ww="王文",zl="张磊")
print(dic)
# 查
# get() 通过键获取值(若没有该键可设置默认值,预防报错)
dic = {"top":"the bug","support":"xboyww","xiaozhang":"王思聪"}
# res = dic["top123"]
# get 在获取字典键时,如果不存在,不会发生任何报错,返回的是None
res = dic.get("top123")
# 可以在获取不到该键时,给与默认值提示.
res = dic.get("top123","抱歉,该键不存在")
print(res)
# 其他操作
#keys() 将字典的键组成新的可迭代对象
dic = {"top":"the bug","support":"xboyww","xiaozhang":"王思聪"}
res = dic.keys()
print(res , type(res))
#values() 将字典中的值组成新的可迭代对象 ***
res = dic.values()
print(res , type(res))
#items() 将字典的键值对凑成一个个元组,组成新的可迭代对象 ***
res = dic.items()
print(res , type(res))
# for i in res:
# print(i)
for k,v in res:
print(k,v)集合的相关操作 (交差并补)
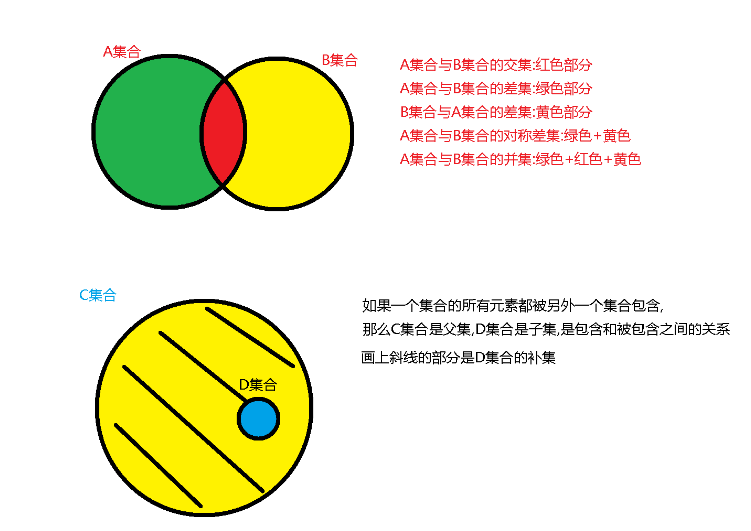
# ### 1.集合的相关操作 (交差并补)
# intersection() 交集
set1 = {"易烊千玺","王一博","刘某PDD","王文"}
set2 = {"倪萍","赵忠祥","金龟子大风车","小龙人","王文"}
res = set1.intersection(set2)
print(res)
# 简写 &
res = set1 & set2
print(res)
# difference() 差集
res = set1.difference(set2)
print(res)
# 简写 -
res = set1 - set2
print(res)
#union() 并集
res = set1.union(set2)
print(res)
# 简写 |
res = set1 | set2
print(res)
#symmetric_difference() 对称差集 (补集情况涵盖在其中)
res = set1.symmetric_difference(set2)
print(res)
# 简写 ^
res = set1 ^ set2
print(res)
#issubset() 判断是否是子集
set1 = {"刘德华","郭富城","张学友","王文"}
set2 = {"王文"}
res = set2.issubset(set1)
print(res)
# 简写
res = set2 < set1
print(res)
#issuperset 判断是否是父集
set1 = {"刘德华","郭富城","张学友","王文"}
set2 = {"王文"}
res = set1.issuperset(set2)
print(res)
# 简写
res = set1 > set2
print(res)
#isdisjoint() 检测两集合是否不相交 不相交 True 相交False
set1 = {"刘德华","郭富城","张学友","王文"}
set2 = {"王文"}
res = set1.isdisjoint(set2)
print(res)
# ### 2.集合的相关函数
# 增
#add() 向集合中添加数据
# 一次加一个
set1 = {"王文"}
set1.add("王伟")
print(set1)
#update() 迭代着增加
# 一次加一堆
set1 = {"王文"}
lst = ["a","b","c"]
lst = "ppp" # 迭代这添加,无序,会自动去重
set1.update(lst)
print(set1)
# 删
setvar = {'刘某PDD', '小龙人','倪萍', '赵忠祥'}
#clear() 清空集合
# setvar.clear()
# print(setvar)
#pop() 随机删除集合中的一个数据
# res = setvar.pop()
# print(res)
# print(setvar)
#discard() 删除集合中指定的值(不存在的不删除 推荐使用) ***
setvar.discard("刘某PDD111111") # success
# setvar.discard("刘某PDD")
# print(setvar)
#remove() 删除集合中指定的值(不存在则报错) (了解)
# setvar.remove("刘某PDD111") # error
# setvar.remove("刘某PDD")
# print(setvar)
# ### 3.冰冻集合 (额外了解)
"""frozenset 单纯的只能做交差并补操作,不能做添加或者删除的操作"""
lst = ["王文","宋健","何旭彤"]
fz1 = frozenset(lst)
print(fz1, type(fz1))
# 不能再冰冻集合中添加或者删除元素
# fz1.add(1)
# fz1.update("abc")
# fz1.discard("王文")
# 冰冻集合只能做交差并补
lst2 = ["王文","王同培","刘一缝"]
fz2 = frozenset(lst2)
print(fz2, type(fz2))
# 交集
res = fz1 & fz2
print(res)
# 遍历冰冻集合
for i in fz2:
print(i)# ### 文件操作
"""
语法:
fp = open(文件,模式,编码集)
fp => 文件的io对象 (文件句柄)
i => input 输入
o => outpur 输出
fp.read() 读取文件内容
fp.write() 写入文件的内容
"""
# 1.文件的写入操作
# (1) 打开文件
fp = open("ceshi1.txt",mode="w",encoding="utf-8")# 打开冰箱门
# (2) 写入内容
fp.write("把大象怼进去") # 把大象怼进去
# (3) 关闭文件
fp.close() # 把冰箱门关上
# 2.文件的读取操作
# (1) 打开文件
fp = open("ceshi1.txt",mode="r",encoding="utf-8")
# (2) 读取内容
res = fp.read()
# (3) 关闭文件
fp.close()
print(res)
# 3.文件存储二进制字节流
"""
二进制字节流:`用于传输数据或者存储数据的一种数据格式
b"abc" b开头的字节流要求数据只能是ascii编码中的字符,不能是中文
# 将字符串和字节流(Bytes流)类型进行转换 (参数写成转化的字符编码格式)
#encode() 编码 将字符串转化为字节流(Bytes流)
#decode() 解码 将Bytes流转化为字符串
"""
data = b"abc"
data = "中文".encode("utf-8")
print(data,type(data))
res = data.decode("utf-8")
print(res,type(res))
# utf-8下 一个中文占用3个字节
data = "中文".encode("utf-8")
# 计算字节总大小
print(len(data))
# 把中字这个字节流进行反解恢复成原来中的字符 "中"
res = b"\xe4\xb8\xad".decode()
print(res)
# 4.文件存储二进制的字节流
"""如果存储的是二进制字节流,指定模式wb,不要指定encoding编码集,否则报错"""
fp = open("ceshi2.txt",mode="wb")
strvar = "红鲤鱼绿鲤鱼与驴".encode("utf-8")
fp.write(strvar)
fp.close()
# 5.文件读取二进制的字节流
fp = open("ceshi2.txt",mode="rb")
res = fp.read()
fp.close()
print(res)
print(res.decode())
# 6.复制文件
"""所有的图片,音频,视频都需要通过二进制字节流来进行存储传输."""
# 先把原文件的二进制字节流读取出来
# 相对路径找集合.png 相对于当前3.py这个文件
# fp = open("集合.png",mode="rb")
# 绝对路径找集合.png 从最底层一级一级往上找
fp = open(r"D:\python32_python\day01\集合.png",mode="rb")
res = fp.read()
fp.close()
# 计算文件中的字节个数 => 文件大小
print(len(res))
# 在把二进制字节流写入到另外一个文件中,相当于复制
fp = open("集合2.png",mode="wb")
fp.write(res)
fp.close()文件操作的扩展模式
# ### 文件操作的扩展模式
"""
# (utf-8编码格式下 默认一个中文三个字节 一个英文或符号 占用一个字节)
#read() 功能: 读取字符的个数(里面的参数代表字符个数)
注意:从当前光标往右边读
#seek() 功能: 调整指针的位置(里面的参数代表字节个数)
seek(0) 把光标移动到文件的开头
seek(0,2) 把光标移动到文件的末尾
#tell() 功能: 当前光标左侧所有的字节数(返回字节数)
"""
# 1.r+ 先读后写
"""
fp = open("ceshi3.txt",mode="r+",encoding="utf-8")
# 先读
res = fp.read()
# 在写
fp.write("ab")
# 在读
fp.seek(0) # 通过seek把光标移动到开头
print(fp.read())
fp.close()
"""
# 2.r+ 先写后读
"""
fp = open("ceshi3.txt",mode="r+",encoding="utf-8")
# 移动光标到最后,否则r模式下,原字符会被覆盖
fp.seek(0,2)
# 先写
fp.write("cd")
# 把光标移动到文件的开头
fp.seek(0)
# 在读
res = fp.read()
print(res)
fp.close()
"""
# 3.w+ 可读可写,清空重写(默认可以创建新的文件)
"""
fp = open("ceshi4.txt",mode="w+",encoding="utf-8")
fp.write("abc")
fp.seek(0)
print(fp.read())
fp.close()
"""
# 4.a+ 可读可写,追加写入 (默认可以创建新的文件)
"""
fp = open("ceshi5.txt",mode="a+",encoding="utf-8")
fp.write("def")
# 读内容
fp.seek(0)
print(fp.read())
fp.close()
"""
# 5.r+和a+区别
"""
r+模式基于当前光标所在位置进行写入覆盖
a+模式会强制把光标放到文件末尾进行追加写入
"""
"""
# fp = open("ceshi5.txt",mode="r+",encoding="utf-8")
fp = open("ceshi5.txt",mode="a+",encoding="utf-8")
fp.seek(3) # 从头数 3个字节的位置
# fp.write("zxc") # 模式会强制把光标放到文件末尾进行追加写入
print(fp.read())
fp.close()
"""
# 6.seek,tell,read之间的使用
fp = open("ceshi5.txt",mode="r+",encoding="utf-8")
fp.seek(4)
# tell 当前光标左边所有内容的字节数
res = fp.tell()
print(res)
# 在r+模式下 read(2) 代表读取2个字符 在rb模式下 read(2) 代表读取2个字节
fp.read(2) # 当前光标往右所有的字符内容
print(fp.tell())
fp.close()
# 7.注意点 (seek在移动时,又可能移动到某个汉字的字节中间,导致原字节无法解析)
"""
fp = open("ceshi6.txt",mode="r+",encoding="utf-8")
fp.seek(3)
print(fp.read())
fp.close()
# print("你".encode())
# b'\xe4\xbd\xa0'
"""
# 8.with语法 自动实现文件关闭操作
# 方法一.读取二进制字节流
"""
with open("集合2.png",mode="rb") as fp:
res = fp.read()
with open("集合3.png",mode="wb") as fp:
fp.write(res)
"""
# 方法二.继续简化
with open("集合3.png",mode="rb") as fp1 , open("集合4.png",mode="wb") as fp2 :
res = fp1.read()
fp2.write(res)字符串、列表、元组用+做一个拼接 集合无序去重的 如果这个数据不想让别人任意修改,就把这些集合给冰冻起来 open一个类,来创建一个对象 decode(),括号里面不写,默认是utf-8 w模式,如果文件已经存在,也是先清空然后在写入内容 a模式,只能追加数据,不能读取数据 a+可以读取数据,读取数据不受影响,seek可以用(会强制把光标放到文件末尾进行追加写入,用seek移动光标也是没有用的) seek移动字节的时候还是应该慎用,因为一个中文字符占3个字节,一个应为字符占用一个字节,如果一个中文没有截取完整则会报错 seek(0) seek(0,2) 还有纯英文的 纯中文的文件使用seek 事实上,在移动我们的内容的位置用的不是seek、而是通过read readline等 文件,后面的的那些函数来实现的 关闭文件这个操作必须要写
到此,关于“Python文件操作的方法是什么”的学习就结束了,希望能够解决大家的疑惑。理论与实践的搭配能更好的帮助大家学习,快去试试吧!若想继续学习更多相关知识,请继续关注亿速云网站,小编会继续努力为大家带来更多实用的文章!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





