这篇文章主要为大家展示了“Hadoop单机模式如何部署”,内容简而易懂,条理清晰,希望能够帮助大家解决疑惑,下面让小编带领大家一起研究并学习一下“Hadoop单机模式如何部署”这篇文章吧。
一、Hadoop部署模式
单机模式:默认情况下运行为一个单独机器上的独立Java进程,主要用于调试环境
伪分布模式:在单个机器上模拟成分布式多节点环境,每一个Hadoop守护进程都作为一个独立的Java进程运行
完全分布式模式:真实的生产环境,搭建在完全分布式的集群环境
二、添加用户和组
$ sudo adduser hadoop ##创建用户hadoop
$ sudo usermod -G sudo hadoop ##将hadoop用户添加进sudo用户组三、安装相关软件
$ sudo apt-get update
$ sudo apt-get -y install openssh-server rsync openjdk-7-jdk
$ sudo service ssh restart
$ java -version
四、配置SSH免密登录
$ su -l hadoop ##切换至hadoop用户
$ ssh-keygen -t rsa -P "" ##配置SSH免密登录
$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys ##将公钥追加到authorized_keys中
$ ssh localhost ##验证五、Hadoop配置
①下载安装Hadoop
$ su -l hadoop
$ wget http://apache.fayea.com/hadoop/common/hadoop-2.7.1/hadoop-2.7.1.tar.gz
$ tar -zxvf hadoop-2.7.1.tar.gz
$ sudo mv hadoop-2.7.1 /usr/local/hadoop
②配置Hadoop
a.添加环境变量
$ vi /home/hadoop/.bashrc
#HADOOP START
export JAVA_HOME=/usr/lib/jvm/java-7-openjdk-amd64
export HADOOP_INSTALL=/usr/local/hadoop/
export PATH=$PATH:$HADOOP_INSTALL/bin
export PATH=$PATH:$HADOOP_INSTALL/sbin
export HADOOP_MAPRED_HOME=$HADOOP_INSTALL
export HADOOP_COMMON_HOME=$HADOOP_INSTALL
export HADOOP_HDFS_HOME=$HADOOP_INSTALL
export YARN_HOME=$HADOOP_INSTALL
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_INSTALL/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_INSTALL/lib"
#HADOOP END
$ . /home/hadoop/.bashrc ##重载使其生效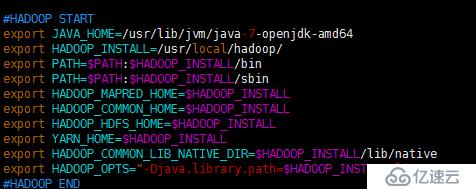
六、测试
①创建输入数据
$ su -l hadoop
$ cd /usr/local/hadoop
$ sudo mkdir input
$ sudo cp /etc/passwd input/②执行Hadoop WordCount应用(词频统计)
$ bin/hadoop jar share/hadoop/mapreduce/sources/hadoop-mapreduce-examples-2.7.1-sources.jar org.apache.hadoop.examples.WordCount input output
③查看生成的单词统计数据
$ hadoop dfs -ls output
-rw-r--r-- 1 hadoop hadoop 0 2015-12-18 13:18 output/_SUCCESS
-rw-r--r-- 1 hadoop hadoop 2128 2015-12-18 13:18 output/part-r-00000
$ hadoop dfs -cat output/*以上是“Hadoop单机模式如何部署”这篇文章的所有内容,感谢各位的阅读!相信大家都有了一定的了解,希望分享的内容对大家有所帮助,如果还想学习更多知识,欢迎关注亿速云行业资讯频道!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



