本篇内容主要讲解“Python数据结构与算法中的栈怎么构建”,感兴趣的朋友不妨来看看。本文介绍的方法操作简单快捷,实用性强。下面就让小编来带大家学习“Python数据结构与算法中的栈怎么构建”吧!
栈有时也被称作“下推栈”。它是有序集合,添加操作和移除操作总发生在同一端,即栈的 “顶端”,栈的另一端则被称为 “底端”。所以最新添加的元素将被最先移除,而且栈中的元素离底端越近,代表其在栈中的时间越长。
这种排序原则被称作LIFO(last-in first-out),即后进先出。它提供了一种基于在集合中的时间来排序的方式。 最近添加的元素靠近顶端,旧元素则靠近底端。
栈的例子在日常生活中比比皆是。几乎所有咖啡馆都有一个由托盘或盘子构成的栈,你可以从顶部取走一个,下一 个顾客则会取走下面的托盘或盘子。
考虑到栈的反转特性,我们可以想到在使用计算机时的一些例子。例如,每一个浏览器都有返回按钮。当我们从一个网页跳转到另一个网页时,这些网页——实际上是URL,都被存放在一个栈中。当前正在浏览的网页位于栈的顶端,最早浏览的网页则位于底端。如果点击返回按钮, 便开始反向浏览这些网页。
如前所述,栈是元素的有序集合,添加操作与移除操作都发生在其顶端。栈的操作顺序是LIFO,它支持以下操作:
将一个元素添加到栈的顶端
将栈顶端的元素移除
返回栈顶端的元素
返回栈中元素的数目
明确了栈的基本特性之后,我们开始用代码构建它。在面向对象的编程语言中(以Python为例),每当需要在Python中实现像栈这样的抽象数据类型时 ,就可以通过创建一个类的途径实现它,且数据类型的特性、操作方法等也可以通过在类中定义方法实现。
我们来明确一下这个类的具体方法:
创建一个空栈。它不需要参数,且会返回一个空栈。 Stack()
将一个元素添加到栈的顶端。它需要一 个参数item ,且无返回值。 push(item)
将栈顶端的元素移除。它不需要参数,但会返回顶端的元素,并且修改栈的内容。 pop()
返回栈顶端的元素,但是并不移除该元素。 它不需要参数,也不会修改栈的内容。 peek()
返回栈中元素的数目。它不需要参数,且会返回一个整数。 size()
检查栈是否为空。它不需要参数,且会返回一个布尔值。 isEmpty()
打印这个栈/列表,它不需要参数,会输出栈的内容。 look()
因为栈是元素的集合,所以完全可以利用Python提供的强大、简单的原生集合来实现。这里,我们将使用列表。 列表的最左端将用来表示栈底,最右边将用来表示栈顶:
class Stack:
# 定义一个列表/构造一个栈
def __init__(self):
self.items = []
print("你创造了一个栈!")
def isEmpty(self):
return self.items == []
def look(self):
print(self.items)
def push(self, item):
self.items.append(item)
print("你给栈顶加了个%s" % item)
def pop(self):
return self.items.pop()
def peek(self):
return self.items[len(self.items) - 1]
def size(self):
return len(self.items)以下展示了栈的操作及其返回结果:
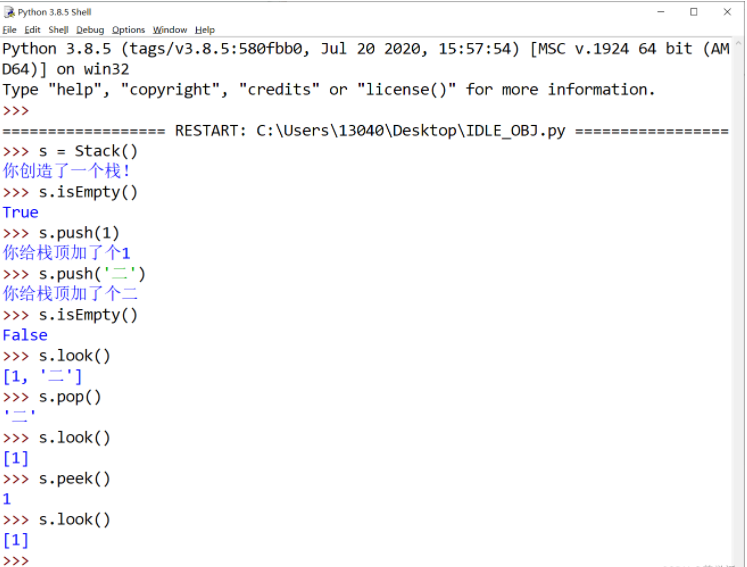
值得注意的是,也可以选择将列表的头部(左边)作为栈的顶端。 不过在这种情况下,便无法直接使用列表的pop方法和append方法,而必须要用列表的pop方法和insert方法显式地访问下标为0的元素,即列表中的第1个元素。以下代码展现了这种方式:
class Stack: def __init__(self): self.items = [] def isEmpty(self): return self.items == [] def look(self): print(self.items) def push(self, item): self.items.insert(0, item) def pop(self): return self.items.pop(0) def peek(self): return self.items[0] def size(self): return len(self.items)
尽管上述两种实现都可行,但是二者在性能方面肯定有差异。append 方法和 pop 方法的时间复杂度都是 o ( 1 ) o(1) o(1),这意味着不论栈中有多少个元素, 第一种实现中的 push 操作和 pop 操作都会在恒定的时间内完成。第二种实现的性能则受制于栈中的元素个数,这 是因为 insert(0) 和 pop(0) 的时间复杂度都是 o ( n ) o(n) o(n),元素越多就越慢。
显而易见,尽管两种实现在逻辑上是相等的,但是它们在进行基准测试时耗费的时间会有很大的差异。
到此,相信大家对“Python数据结构与算法中的栈怎么构建”有了更深的了解,不妨来实际操作一番吧!这里是亿速云网站,更多相关内容可以进入相关频道进行查询,关注我们,继续学习!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





