这篇文章主要介绍“如何用Python制作一个MOOC公开课下载器”,在日常操作中,相信很多人在如何用Python制作一个MOOC公开课下载器问题上存在疑惑,小编查阅了各式资料,整理出简单好用的操作方法,希望对大家解答”如何用Python制作一个MOOC公开课下载器”的疑惑有所帮助!接下来,请跟着小编一起来学习吧!
Python版本:3.7.8
相关模块:
DecryptLogin模块;
tqdm模块;
click模块;
argparse模块;
以及一些python自带的模块。
安装Python并添加到环境变量,pip安装需要的相关模块即可。
运行方式:
python moocdl.py --url 课程链接
效果如下:
moocdl
随便挑的一个课程测试的,结果是m3u8格式的,所以下载起来有点慢。默认会把所有的课件这些东西也一起下载下来放到对应的目录。
首先,我们需要先模拟登录中国大学MOOC,这样才能下载对应的课程资料,这里借助公众号之前开源的DecryptLogin包就好啦:
'''登录''' def login(self, username, password): lg = login.Login() infos_return, session = lg.icourse163(username, password) return infos_return, session
接着,我们简单讲解一下如何下载对应课程里的资料。首先,我们需要获得课程相关的基本资料,随便点开个课程主页就可以发现直接在返回的页面里就有:
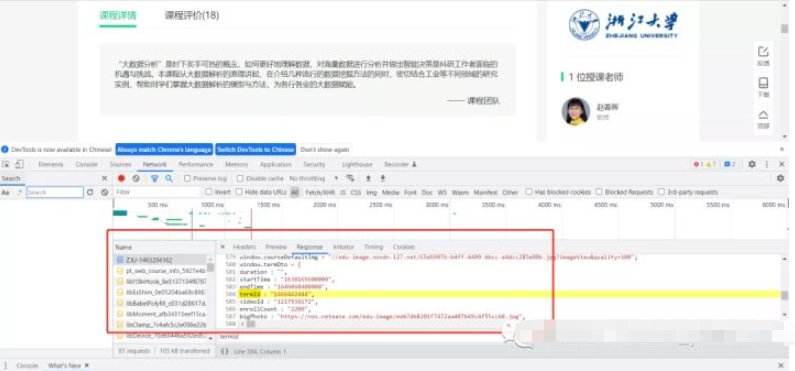
提取我们需要的课程信息的代码实现如下:
# 从课程主页面获取信息
url = url.replace('learn/', 'course/')
response = self.session.get(url)
term_id = re.findall(r'termId : "(\d+)"', response.text)[0]
course_name = ' - '.join(re.findall(r'name:"(.+)"', response.text))
course_name = self.filterBadCharacter(course_name)
course_id = re.findall(r'https?://www.icourse163.org/(course|learn)/\w+-(\d+)', url)[0]
print(f'从课程主页面获取的信息如下:\n\t[课程名]: {course_name}, [课程ID]: {course_name}, [TID]: {term_id}')接着利用这些信息来爬取对应的资源列表:
# 获取资源列表
resource_list = []
data = {
'tid': term_id,
'mob-token': self.infos_return['results']['mob-token'],
}
response = self.session.post('https://www.icourse163.org/mob/course/courseLearn/v1', data=data)
course_info = response.json()
file_types = [1, 3, 4]
for chapter_num, chapter in enumerate(course_info.get('results', {}).get('termDto', {}).get('chapters', [])):
for lesson_num, lesson in enumerate(chapter.get('lessons', [])) if chapter.get('lessons') is not None else []:
for unit_num, unit in enumerate(lesson.get('units', [])):
if unit['contentType'] not in file_types: continue
savedir = course_name
self.checkdir(savedir)
for item in [self.filterBadCharacter(chapter['name']), self.filterBadCharacter(lesson['name']), self.filterBadCharacter(unit['name'])]:
savedir = os.path.join(savedir, item)
self.checkdir(savedir)
if unit['contentType'] == file_types[0]:
savename = self.filterBadCharacter(unit['name']) + '.mp4'
resource_list.append({
'savedir': savedir,
'savename': savename,
'type': 'video',
'contentId': unit['contentId'],
'id': unit['id'],
})
elif unit['contentType'] == file_types[1]:
savename = self.filterBadCharacter(unit['name']) + '.pdf'
resource_list.append({
'savedir': savedir,
'savename': savename,
'type': 'pdf',
'contentId': unit['contentId'],
'id': unit['id'],
})
elif unit['contentType'] == file_types[2]:
if unit.get('jsonContent'):
json_content = eval(unit['jsonContent'])
savename = self.filterBadCharacter(json_content['fileName'])
resource_list.append({
'savedir': savedir,
'savename': savename,
'type': 'rich_text',
'jsonContent': json_content,
})
print(f'成功获得资源列表, 数量为{len(resource_list)}')最后根据资源类型解析下载即可:
# 下载对应资源
pbar = tqdm(resource_list)
for resource in pbar:
pbar.set_description(f'downloading {resource["savename"]}')
# --下载视频
if resource['type'] == 'video':
data = {
'bizType': '1',
'mob-token': self.infos_return['results']['mob-token'],
'bizId': resource['id'],
'contentType': '1',
}
while True:
response = self.session.post('https://www.icourse163.org/mob/j/v1/mobileResourceRpcBean.getResourceToken.rpc', data=data)
if response.json()['results'] is not None: break
time.sleep(0.5 + random.random())
signature = response.json()['results']['videoSignDto']['signature']
data = {
'enVersion': '1',
'clientType': '2',
'mob-token': self.infos_return['results']['mob-token'],
'signature': signature,
'videoId': resource['contentId'],
}
response = self.session.post('https://vod.study.163.com/mob/api/v1/vod/videoByNative', data=data)
# ----下载视频
videos = response.json()['results']['videoInfo']['videos']
resolutions, video_url = [3, 2, 1], None
for resolution in resolutions:
for video in videos:
if video['quality'] == resolution:
video_url = video["videoUrl"]
break
if video_url is not None: break
if '.m3u8' in video_url:
self.m3u8download({
'download_url': video_url,
'savedir': resource['savedir'],
'savename': resource['savename'],
})
else:
self.defaultdownload({
'download_url': video_url,
'savedir': resource['savedir'],
'savename': resource['savename'],
})
# ----下载字幕
srt_info = response.json()['results']['videoInfo']['srtCaptions']
if srt_info:
for srt_item in srt_info:
srt_name = os.path.splitext(resource['savename'])[0] + '_' + srt_item['languageCode'] + '.srt'
srt_url = srt_item['url']
response = self.session.get(srt_url)
fp = open(os.path.join(resource['savedir'], srt_name), 'wb')
fp.write(response.content)
fp.close()
# --下载PDF
elif resource['type'] == 'pdf':
data = {
't': '3',
'cid': resource['contentId'],
'unitId': resource['id'],
'mob-token': self.infos_return['results']['mob-token'],
}
response = self.session.post('http://www.icourse163.org/mob/course/learn/v1', data=data)
pdf_url = response.json()['results']['learnInfo']['textOrigUrl']
self.defaultdownload({
'download_url': pdf_url,
'savedir': resource['savedir'],
'savename': resource['savename'],
})
# --下载富文本
elif resource['type'] == 'rich_text':
download_url = 'http://www.icourse163.org/mob/course/attachment.htm?' + urlencode(resource['jsonContent'])
self.defaultdownload({
'download_url': download_url,
'savedir': resource['savedir'],
'savename': resource['savename'],
})到此,关于“如何用Python制作一个MOOC公开课下载器”的学习就结束了,希望能够解决大家的疑惑。理论与实践的搭配能更好的帮助大家学习,快去试试吧!若想继续学习更多相关知识,请继续关注亿速云网站,小编会继续努力为大家带来更多实用的文章!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





