дёҖж¬ЎSQLжҖҺд№ҲжҹҘйҮҚеҸҠеҺ»йҮҚ
иҝҷзҜҮж–Үз« дё»иҰҒдёәеӨ§е®¶еұ•зӨәдәҶвҖңдёҖж¬ЎSQLжҖҺд№ҲжҹҘйҮҚеҸҠеҺ»йҮҚвҖқпјҢеҶ…е®№з®ҖиҖҢжҳ“жҮӮпјҢжқЎзҗҶжё…жҷ°пјҢеёҢжңӣиғҪеӨҹеё®еҠ©еӨ§е®¶и§ЈеҶіз–‘жғ‘пјҢдёӢйқўи®©е°Ҹзј–еёҰйўҶеӨ§е®¶дёҖиө·з ”究并еӯҰд№ дёҖдёӢвҖңдёҖж¬ЎSQLжҖҺд№ҲжҹҘйҮҚеҸҠеҺ»йҮҚвҖқиҝҷзҜҮж–Үз« еҗ§гҖӮ
еүҚиЁҖ
еңЁдҪҝз”ЁSQLжҸҗж•°зҡ„ж—¶еҖҷпјҢеёёдјҡйҒҮеҲ°иЎЁеҶ…жңүйҮҚеӨҚеҖјзҡ„ж—¶еҖҷпјҢе°ұйңҖиҰҒеҒҡеҺ»йҮҚпјҢжң¬ж–ҮеҪ’зұ»дәҶеёёз”Ёж–№жі•гҖӮ
вӣіпёҸ 1.distinct
йўҳзӣ®пјҡзҺ°еңЁиҝҗиҗҘйңҖиҰҒжҹҘзңӢз”ЁжҲ·жқҘиҮӘдәҺе“ӘдәӣеӯҰж ЎпјҢиҜ·д»Һз”ЁжҲ·дҝЎжҒҜиЎЁдёӯеҸ–еҮәеӯҰж Ўзҡ„еҺ»йҮҚж•°жҚ®
зӨәдҫӢ:user_profile
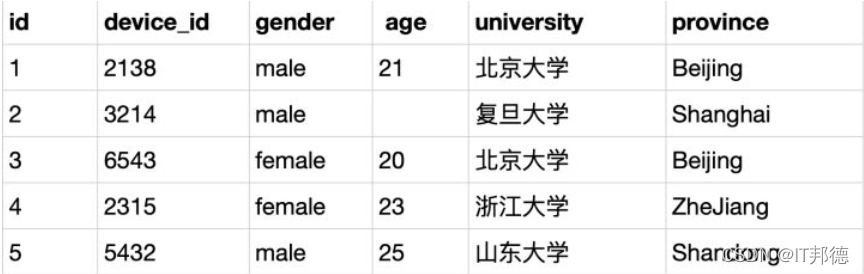
mysql>SELECT DISTINCT university FROM user_profile;
????????ж №жҚ®зӨәдҫӢпјҢжҹҘиҜўиҝ”еӣһд»ҘдёӢз»“жһң

????????е°ҸиҙҙеЈ«пјҡ
SQLдёӯе…ій”®иҜҚdistinctеҺ»йҮҚпјҡ
иӢұиҜӯдёӯdistinct д»ЈиЎЁзӢ¬дёҖж— дәҢзҡ„ж„ҸжҖқпјҢ
д»–еңЁSQLиЎЁзӨәеҺ»йҮҚзҡ„ж„ҸжҖқпјҡжҜ”еҰӮжң¬йўҳдёӯuniversityиҝҷдёҖеҲ—еҮәзҺ°дәҶдёӨж¬ЎеҢ—дә¬еӨ§еӯҰпјҢ
дҪҝз”ЁdistinctиҝӣиЎҢеҺ»йҮҚжҹҘиҜўеҗҺпјҢеҲҷеҢ—дә¬еӨ§еӯҰеҸӘеҮәзҺ°дёҖж¬ЎгҖӮ
distinct йҖҡеёёж•ҲзҺҮиҫғдҪҺ
distinct дҪҝз”ЁдёӯпјҢж”ҫеңЁ select еҗҺиҫ№пјҢеҜ№еҗҺйқўжүҖжңүзҡ„еӯ—ж®өзҡ„еҖјз»ҹдёҖиҝӣиЎҢеҺ»йҮҚ
???????? жӢ“еұ•пјҡ
йўҳзӣ®пјҡзҺ°еңЁиҝҗиҗҘйңҖиҰҒжҹҘзңӢз”ЁжҲ·зҡ„жҖ»ж•°
select count(distinct university) from user_profile;
вӣіпёҸ 2.group by
???????? дёҫдёӘж —еӯҗпјҢзҺ°жңүиҝҷж ·дёҖеј иЎЁ task
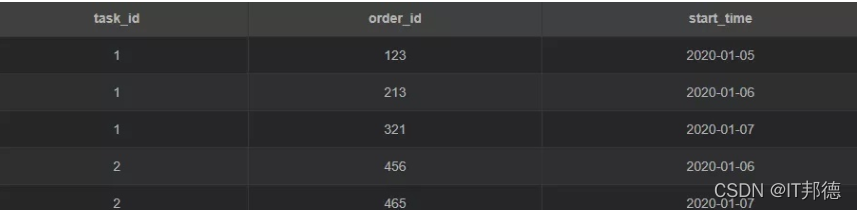
еӨҮжіЁпјҡ
task_id: д»»еҠЎid;
order_id: и®ўеҚ•id;
start_time: ејҖе§Ӣж—¶й—ҙ
жіЁж„ҸпјҡдёҖдёӘд»»еҠЎеҜ№еә”еӨҡжқЎи®ўеҚ•
йўҳзӣ®пјҡеҲ—еҮәд»»еҠЎжҖ»ж•°
????????????????ж №жҚ®зӨәдҫӢпјҢжҹҘиҜўж–№жі•еҰӮдёӢпјҡ
第1жӯҘпјҡеҲ—еҮә task_id зҡ„жүҖжңүе”ҜдёҖеҖјпјҲеҺ»йҮҚеҗҺзҡ„и®°еҪ•,nullд№ҹжҳҜеҖјпјү
select task_id
from Task
group by task_id;
第дәҢжӯҘпјҡ д»»еҠЎжҖ»ж•°
select count(task_id) task_num
from (select task_id
from Task
group by task_id) tmp;
вӣіпёҸ 3.row_number зӘ—еҸЈеҮҪж•°
???????? дёҫдёӘж —еӯҗпјҢзҺ°жңүиҝҷж ·дёҖеј иЎЁ task
еӨҮжіЁпјҡ
task_id: д»»еҠЎid;
order_id: и®ўеҚ•id;
start_time: ејҖе§Ӣж—¶й—ҙ
жіЁж„ҸпјҡдёҖдёӘд»»еҠЎеҜ№еә”еӨҡжқЎи®ўеҚ•
йўҳзӣ®пјҡжҹҘиҜўж•ҙдёӘиЎЁйҮҚеӨҚзҡ„ж•°жҚ®
????????ж №жҚ®зӨәдҫӢпјҢжҹҘиҜўж–№жі•еҰӮдёӢпјҡ
– еңЁж”ҜжҢҒзӘ—еҸЈеҮҪж•°зҡ„ sql дёӯдҪҝз”Ё
select count(case when rn=1 then task_id else null end) task_num
from (select task_id
, row_number() over (partition by task_id order by start_time) rn
from Task) tmp;
????????е°ҸиҙҙеЈ«пјҡ
MySQL8.0 дёӯеҸҜд»ҘеҲ©з”Ё ROW_NUMBER()пјҢDENSE_RANK()пјҢRANK() дёүдёӘзӘ—еҸЈеҮҪж•°жқҘе®һзҺ°жҺ’еәҸ
йңҖиҰҒжіЁж„Ҹзҡ„дёҖзӮ№жҳҜ as еҗҺзҡ„еҲ«еҗҚпјҢеҚғдёҮдёҚиҰҒдёҺеүҚйқўзҡ„еҮҪж•°еҗҚйҮҚеҗҚпјҢеҗҰеҲҷдјҡжҠҘй”ҷ
дёӢйқўз»ҷеҮәиҝҷдёүз§ҚеҮҪж•°е®һзҺ°жҺ’еҗҚзҡ„жЎҲдҫӢпјҡ
–дёүжқЎиҜӯеҸҘеҜ№дәҺдёҠйқўдёүз§ҚжҺ’еҗҚ
select xuehao,score, ROW_NUMBER() OVER(order by score desc) as row_r from scores_tb;
select xuehao,score, DENSE_RANK() OVER(order by score desc) as dense_r from scores_tb;
select xuehao,score, RANK() over(order by score desc) as r from scores_tb;
– дёҖжқЎиҜӯеҸҘд№ҹеҸҜд»ҘжҹҘиҜўеҮәдёҚеҗҢжҺ’еҗҚ
SELECT xuehao,score,
ROW_NUMBER() OVER w AS вҖҳrow_r',
DENSE_RANK() OVER w AS вҖҳdense_r',
RANK() OVER w AS вҖҳr'
FROM scores_tb
WINDOW w AS (ORDER BY score desc);
вӣіпёҸ 4.еҲ йҷӨйҮҚеӨҚж•°жҚ®
еҲӣе»әжөӢиҜ•ж•°жҚ®
жҲ‘们еҲӣе»әдёҖдёӘдәәе‘ҳдҝЎжҒҜ表并еңЁйҮҢйқўжҸ’е…ҘдёҖдәӣйҮҚеӨҚзҡ„ж•°жҚ®
CREATE TABLE Person(
id int auto_increment primary key comment вҖҳдё»й”®',
Name VARCHAR(20) NULL,
Age INT NULL,
Address VARCHAR(20) NULL,
Sex CHAR(2) NULL
);
INSERT INTO Person(ID,Name,Age,Address,Sex)
VALUES
( 1, вҖҳеј дёү', 18, вҖҳеҢ—дә¬и·Ҝ18еҸ·', вҖҳз”·' ),
( 2, вҖҳжқҺеӣӣ', 19, вҖҳеҢ—дә¬и·Ҝ29еҸ·', вҖҳз”·' ),
( 3, вҖҳзҺӢдә”', 19, вҖҳеҚ—дә¬и·Ҝ11еҸ·', вҖҳеҘі' ),
( 4, вҖҳеј дёү', 18, вҖҳеҢ—дә¬и·Ҝ18еҸ·', вҖҳз”·' ),
( 5, вҖҳжқҺеӣӣ', 19, вҖҳеҢ—дә¬и·Ҝ29еҸ·', вҖҳз”·' ),
( 6, вҖҳеј дёү', 18, вҖҳеҢ—дә¬и·Ҝ18еҸ·', вҖҳз”·' ),
( 7, вҖҳзҺӢдә”', 19, вҖҳеҚ—дә¬и·Ҝ11еҸ·', вҖҳеҘі' ),
( 8, вҖҳ马е…ӯ', 18, вҖҳеҚ—дә¬и·Ҝ19еҸ·', вҖҳеҘі' );
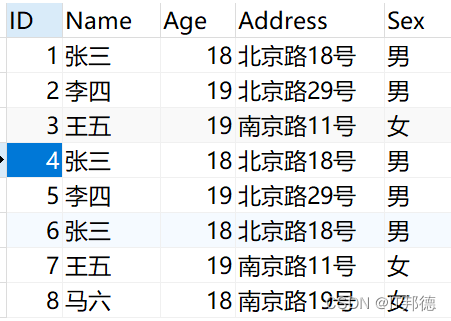
йўҳзӣ®пјҡж•°жҚ®еә“дёӯеӯҳеңЁйҮҚеӨҚи®°еҪ•пјҢеҲ йҷӨдҝқз•ҷе…¶дёӯдёҖжқЎ
жҲ‘们еҸ‘зҺ°йҷӨдәҶиҮӘеўһй•ҝIDдёҚеҗҢд»ҘдёәпјҢжңүеҮ жқЎе…¶д»–еӯ—ж®өйғҪйҮҚеӨҚзҡ„ж•°жҚ®еҮәзҺ°
???? 第дёҖжӯҘпјҡжүҫеҮәйҮҚеӨҚзҡ„ж•°жҚ®
mysql>SELECT MAX(ID) ID,
Name,Age,Address,Sex
FROM Person
GROUP BY Name,Age,Address,Sex
HAVING COUNT(1)>1
????????е°ҸиҙҙеЈ«пјҡ
HAVINGе°ҶеҲҶз»„еҗҺз»ҹи®ЎеҮәжқҘзҡ„ж•°йҮҸеӨ§дәҺ1зҡ„ж•°жҚ®иЎҢпјҢе°ұжҳҜжҲ‘们иҰҒжүҫзҡ„йҮҚеӨҚж•°жҚ®
дёҠйқўз”ЁMaxеҮҪж•°жҲ–иҖ…MinеҮҪж•°еқҮеҸҜпјҢеҸӘжҳҜдёәдәҶдҝқиҜҒеҸ–еҮәжқҘзҡ„ж•°жҚ®зҡ„е”ҜдёҖжҖ§гҖӮ
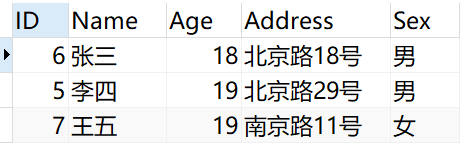
???? 第дәҢжӯҘпјҡеҲ йҷӨйҮҚеӨҚзҡ„ж•°жҚ®
е…¶е®һжҲ‘们数жҚ®еә“дёӯжңҖеҗҺиҰҒдҝқз•ҷзҡ„з»“жһңе°ұжҳҜ第дәҢжӯҘдёӯжҹҘиҜўеҮәжқҘзҡ„ж•°жҚ®пјҢ
жҲ‘们жҠҠе…¶д»–зҡ„ж•°жҚ®еҲ йҷӨеҚіеҸҜгҖӮ
жҖҺд№ҲеҲ йҷӨе‘ўпјҹжҲ‘们дҪҝз”ЁIDжқҘжҺ’йҷӨгҖӮ
DELETE FROM Person
WHERE EXISTS
(
SELECT * FROM (
SELECT
MAX(ID) ID,
Name,Age,Address,Sex
FROM Person
GROUP BY Name,Age,Address,Sex
HAVING COUNT(1)>1) T
WHERE Person.Name=T.Name
AND Person.Age=T.Age
AND Person.Address=T.Address
AND Person.Sex=T.Sex
AND Person.ID<T.ID
)
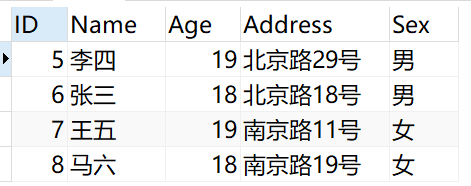
жү§иЎҢе®ҢеҗҺйҮҚж–°жҹҘиҜўPersonиЎЁз»“жһңеҰӮдёӢ
马е…ӯеӣ дёәеҸӘжңүдёҖжқЎи®°еҪ•пјҢжүҖд»ҘжІЎжңүеҸӮдёҺеҺ»йҮҚпјҢзӣҙжҺҘжҳҫзӨәгҖӮ
д»ҘдёҠжҳҜвҖңдёҖж¬ЎSQLжҖҺд№ҲжҹҘйҮҚеҸҠеҺ»йҮҚвҖқиҝҷзҜҮж–Үз« зҡ„жүҖжңүеҶ…е®№пјҢж„ҹи°ўеҗ„дҪҚзҡ„йҳ…иҜ»пјҒзӣёдҝЎеӨ§е®¶йғҪжңүдәҶдёҖе®ҡзҡ„дәҶи§ЈпјҢеёҢжңӣеҲҶдә«зҡ„еҶ…е®№еҜ№еӨ§е®¶жңүжүҖеё®еҠ©пјҢеҰӮжһңиҝҳжғіеӯҰд№ жӣҙеӨҡзҹҘиҜҶпјҢж¬ўиҝҺе…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“пјҒ





