本文小编为大家详细介绍“C++二叉搜索树的操作有哪些”,内容详细,步骤清晰,细节处理妥当,希望这篇“C++二叉搜索树的操作有哪些”文章能帮助大家解决疑惑,下面跟着小编的思路慢慢深入,一起来学习新知识吧。
二叉搜索树又称二叉排序树,若它的左子树不为空,则左子树上所有节点的值都小于根节点的值;若它的右子树不为空,则右子树上所有节点的值都大于根节点的值,它的左右子树也分别未二叉搜索树。也可以是一颗空树。
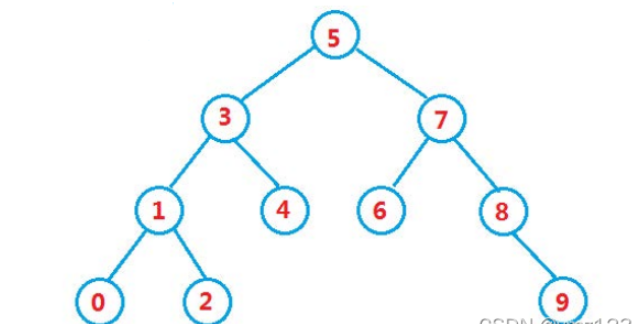
int a[] = { 5, 3, 4, 1, 7, 8, 2, 6, 0, 9 };
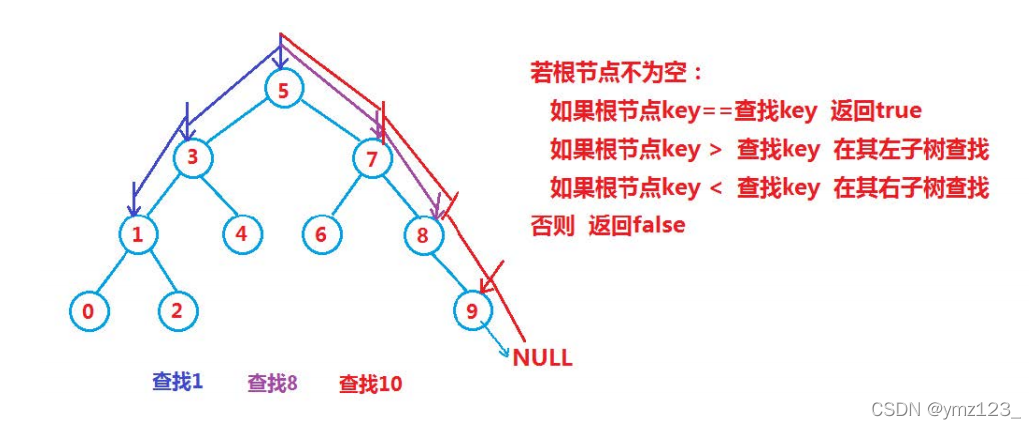
迭代:
Node* Find(const K& key)
{
Node* cur = _root;
while (cur)
{
if (cur->_key < key)
{
cur = cur->_right;
}
else if (cur->_key > key)
{
cur = cur->_left;
}
else
{
return cur;
}
}
return nullptr;
}递归:
Node* _FindR(Node* root, const K& key)
{
if (root == nullptr)
return nullptr;
if (root->_key < key)
return _FindR(root->_right, key);
else if (root->_key > key)
return _FindR(root->_left, key);
else
return root;
}树为空,则直接插入

树不为空,按二叉搜索树性质查找插入位置,插入新节点
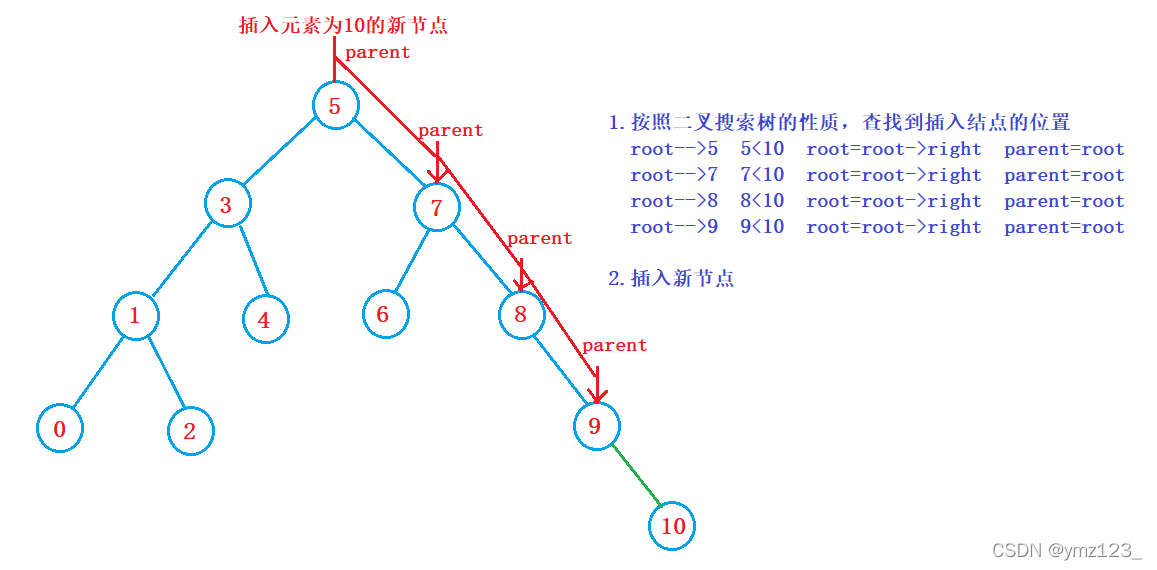
迭代:
bool Insert(const K& key)
{
if (_root == nullptr)
{
_root = new Node(key);
return true;
}
//查找要插入的位置
Node* parent = nullptr;
Node* cur = _root;
while (cur)
{
if (cur->_key < key)
{
parent = cur;
cur = cur->_right;
}
else if (cur->_key > key)
{
parent = cur;
cur = cur->_left;
}
else
{
return false;
}
}
cur = new Node(key);
if (parent->_key < cur->_key)
{
parent->_right = cur;
}
else
{
parent->_left = cur;
}
return true;
}递归:
bool _InsertR(Node*& root, const K& key)
{
if (root == nullptr)
{
root = new Node(key);
return true;
}
else
{
if (root->_key < key)
{
return _InsertR(root->_left, key);
}
else if (root->_key > key)
{
return _InsertR(root->_left, key);
}
else
{
return false;
}
}
}首先查找元素是否在二叉搜索树中,如果不存在,则返回,否则要删除的结点可能分下面四种情况:
要删除的结点无孩子结点
要删除的结点只有左孩子结点
要删除的结点只有右孩子结点
要删除的结点只有左、右结点
实际情况中1和2或3可以合并,因此真正的删除过程如下:
删除该结点且使被删除结点的双亲结点指向被删除结点的左孩子结点
删除该结点且使被删除结点的双亲结点指向被删除结点的右孩子结点
替代法。在它的右子树中寻找中序下的第一个结点(关键码最小),用它的值填补到被删除结点中,再来处理该结点的删除问题。
迭代:
bool Erase(const K& key)
{
Node* parent = nullptr;
Node* cur = _root;
while (cur)
{
if (cur->_key < key)
{
parent = cur;
cur = cur->_right;
}
else if (cur->_key > key)
{
parent = cur;
cur = cur->_left;
}
else
{
//删除
if (cur->_left == nullptr)
{
if (cur == _root)
{
_root = cur->_right;
}
else
{
if (cur == parent->_left)
{
parent->_left = cur->_right;
}
else
{
parent->_right = cur->_right;
}
}
delete cur;
}
else if (cur->_right == nullptr)
{
if (cur == _root)
{
_root = cur->_left;
}
else
{
if (cur == parent->_left)
{
parent->_left = cur->_left;
}
else
{
parent->_right = cur->_left;
}
}
}
else
{
//找到右树最小节点去替代删除
Node* minRightParent = cur;
Node* minRight = cur->_right;
while (minRight->_left)
{
minRightParent = minRight;
minRight = minRight->_left;
}
cur->_key = minRight->_key;
if (minRight == minRightParent->_left)
minRightParent->_left = minRight->_right;
else
minRightParent->_right = minRight->_right;
delete minRight;
}
return true;
}
}
return false;
}递归:
bool _EraseR(Node*& root, const K& key)
{
if (root == nullptr)
return false;
if (root->_key < key)
{
return _EraseR(root->_right, key);
}
else if (root->_key > key)
{
return _EraseR(root->_left, key);
}
else
{
//删除
Node* del = root;
if (root->_left == nullptr)
{
root = root->_right;
}
else if (root->_right == nullptr)
{
root = root->_left;
}
else
{
//替代法删除
Node* minRight = root->_right;
while (minRight->_left)
{
minRight = minRight->_left;
}
root->_key = minRight->_key;
//转换成递归在右子树中删除最小节点
return _EraseR(root->_right, minRight->_key);
}
delete del;
return true;
}
}1.K模型:K模型即只有key作为关键码,结构中只需要存储key即可,关键码即为需要搜索到的值。比如:给一个单词word,判断该单词是否拼写正确。具体方法如下:1.以单词集合中的每个单词作为key,构建一棵二叉搜索树。2.在二叉搜索树中检索该单词是否存在,存在则拼写正确,不存在则拼写错误。
2.KV模型:每一个关键码key,都有与之对应的值Value,即<Key, Value>的键值对。该种方式在现实生活中非常常见:比如英汉词典就是英语与中文的对应关系,通过英文可以快速找到与其对应的中文,英文单词与其对应的中文<word, chinese>就构成一种键值对;再比如统计单词次数,统计成功后,给定单词就可快速找到其出现的次数,单词与其出现次数就是<word, count>就构成一种键值对。
比如:实现一个简单的英汉词典dict,可以通过英文找到与其对应的中文,具体实现方式如下:1.<单词,中文含义>为键值对构造二叉搜索树,注意:二叉搜索树需要比较,键值对比较时只比较Key。2.查询英文单词时,只需要给出英文单词,就可快速找到与其对应的Key。
namespace KEY_VALUE {
template<class K, class V>
struct BSTreeNode
{
BSTreeNode<K, V>* _left;
BSTreeNode<K, V>* _right;
K _key;
V _value;
BSTreeNode(const K& key, const V& value)
:_left(nullptr)
,_right(nullptr)
,_key(key)
,_value(value)
{}
};
template<class K, class V>
class BSTree {
typedef BSTreeNode<K, V> Node;
public:
V& operator[](const K& key)
{
pair<Node*, bool> ret = Insert(key, V());
return ret.first->_value;
}
pair<Node*, bool> Insert(const K& key, const V& value)
{
if (_root == nullptr)
{
_root = new Node(key, value);
return make_pair(_root, true);
}
//查找要插入的位置
Node* parent = nullptr;
Node* cur = _root;
while (cur)
{
if (cur->_key < key)
{
parent = cur;
cur = cur->_right;
}
else if (cur->_key > key)
{
parent = cur;
cur = cur->_left;
}
else
{
return make_pair(cur, false);
}
}
cur = new Node(key, value);
if (parent->_key < cur->_key)
{
parent->_right = cur;
}
else
{
parent->_left = cur;
}
return make_pair(cur, true);
}
Node* Find(const K& key)
{
Node* cur = _root;
while (cur)
{
if (cur->_key < key)
{
cur = cur->_right;
}
else if (cur->_key > key)
{
cur = cur->_left;
}
else
{
return cur;
}
}
return nullptr;
}
bool Erase(const K& key)
{
Node* cur = _root;
Node* parent = nullptr;
while (cur)
{
if (cur->_key < key)
{
parent = cur;
cur = cur->_right;
}
else if (cur->_key > key)
{
parent = cur;
cur = cur->_left;
}
else
{
//删除
if (cur->_left == nullptr)
{
if (cur == _root)
{
_root = cur->_right;
}
else
{
if (cur == parent->_left)
{
parent->_left = cur->_left;
}
else
{
parent->_right = cur->_right;
}
}
delete cur;
}
else if (cur->_right == nullptr)
{
if (cur == _root)
{
_root = cur->_left;
}
else
{
if (cur == parent->_left)
{
parent->_left = cur->_left;
}
else
{
parent->_right = cur->_right;
}
}
delete cur;
}
else
{
//找到右树最小结点去替代删除
Node* minRightParent = cur;
Node* minRight = cur->_left;
while (minRight->_left)
{
minRightParent = minRight;
minRight = minRight->_left;
}
cur->_key = minRight->_key;
if (minRight = minRightParent->_left)
minRightParent->_left = minRight->right;
else
minRightParent->_right = minRight->_right;
delete minRight;
}
return true;
}
}
return false;
}
void InOrder()
{
_InOrder(_root);
cout << endl;
}
private:
void _InOrder(Node* root)
{
if (root == nullptr)
{
return;
}
_InOrder(root->_left);
cout << root->_key << ":" << root->_value << endl;
_InOrder(root->_right);
}
private:
Node* _root = nullptr;
};
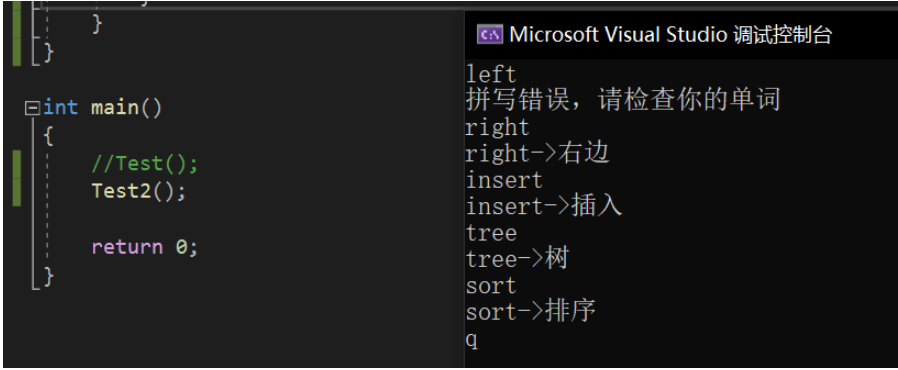
}void Test2()
{
KEY_VALUE::BSTree<string, string> dict;
dict.Insert("sort", "排序");
dict.Insert("insert", "插入");
dict.Insert("tree", "树");
dict.Insert("right", "右边");
string str;
while (cin >> str)
{
if (str == "q")
{
break;
}
else
{
auto ret = dict.Find(str);
if (ret == nullptr)
{
cout << "拼写错误,请检查你的单词" << endl;
}
else
{
cout << ret->_key <<"->"<< ret->_value << endl;
}
}
}
}
void Test3()
{
//统计字符串出现次数,也是经典key/value
string str[] = { "sort", "sort", "tree", "insert", "sort", "tree", "sort", "test", "sort" };
KEY_VALUE::BSTree<string, int> countTree;
//for (auto& e : str)
//{
// auto ret = countTree.Find(e);
// if (ret == nullptr)
// {
// countTree.Insert(e, 1);
// }
// else
// {
// ret->_value++;
// }
//}
for (auto& e : str)
{
countTree[e]++;
}
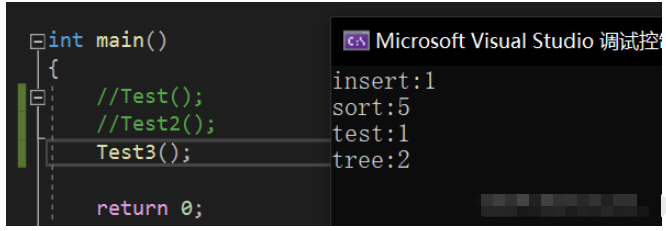
countTree.InOrder();
}
插入和删除操作都必须先查找,查找效率代表了二叉搜索树中各个操作的性能。
对有n个结点的二叉搜索树,若每个元素查找的概率相等,则二叉搜索树平均查找长度是结点在二叉搜索树的深度的函数,即结点越深,比较的次数越多。
但对于同一个关键码集合,如果关键码插入的次序不同,可能得到不同结构的二叉搜索树
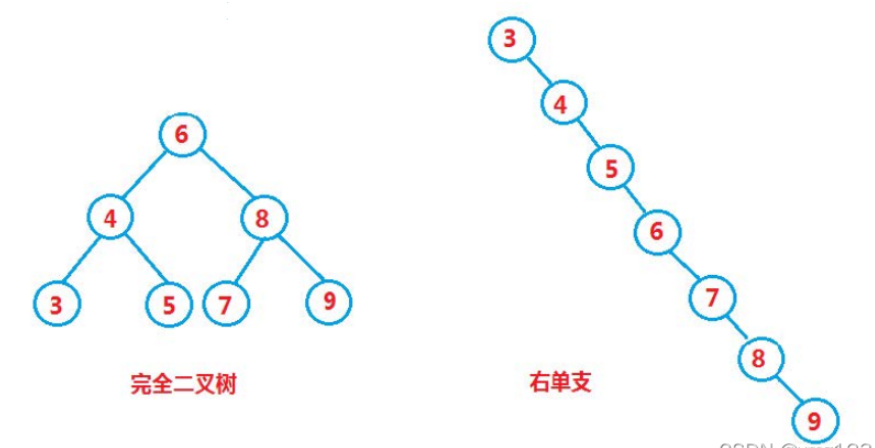
最优情况下,二叉搜索树为完全二叉树,其平均比较次数为:logN
最差情况下,二叉搜索树退化为单支树,其平均比较次数为:N/2
读到这里,这篇“C++二叉搜索树的操作有哪些”文章已经介绍完毕,想要掌握这篇文章的知识点还需要大家自己动手实践使用过才能领会,如果想了解更多相关内容的文章,欢迎关注亿速云行业资讯频道。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





