本文小编为大家详细介绍“pytorch中的transforms.ToTensor和transforms.Normalize怎么实现”,内容详细,步骤清晰,细节处理妥当,希望这篇“pytorch中的transforms.ToTensor和transforms.Normalize怎么实现”文章能帮助大家解决疑惑,下面跟着小编的思路慢慢深入,一起来学习新知识吧。
最近看pytorch时,遇到了对图像数据的归一化,如下图所示:

该怎么理解这串代码呢?我们一句一句的来看,先看transforms.ToTensor(),我们可以先转到官方给的定义,如下图所示:

大概的意思就是说,transforms.ToTensor()可以将PIL和numpy格式的数据从[0,255]范围转换到[0,1] ,具体做法其实就是将原始数据除以255。另外原始数据的shape是(H x W x C),通过transforms.ToTensor()后shape会变为(C x H x W)。这样说我觉得大家应该也是能理解的,这部分并不难,但想着还是用一些例子来加深大家的映像
先导入一些包
import cv2 import numpy as np import torch from torchvision import transforms
定义一个数组模型图片,注意数组数据类型需要时np.uint8【官方图示中给出】
data = np.array([ [[1,1,1],[1,1,1],[1,1,1],[1,1,1],[1,1,1]], [[2,2,2],[2,2,2],[2,2,2],[2,2,2],[2,2,2]], [[3,3,3],[3,3,3],[3,3,3],[3,3,3],[3,3,3]], [[4,4,4],[4,4,4],[4,4,4],[4,4,4],[4,4,4]], [[5,5,5],[5,5,5],[5,5,5],[5,5,5],[5,5,5]] ],dtype='uint8')
这是可以看看data的shape,注意现在为(W H C)。
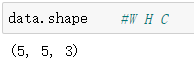
使用transforms.ToTensor()将data进行转换
data = transforms.ToTensor()(data)
这时候我们来看看data中的数据及shape。
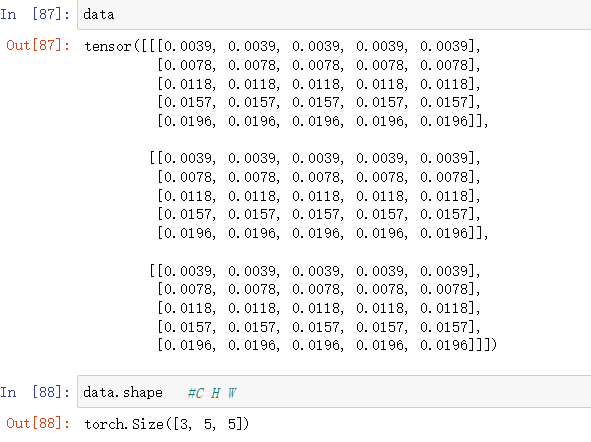
很明显,数据现在都映射到了[0, 1]之间,并且data的shape发生了变换。
**注意:不知道大家是如何理解三维数组的,这里提供我的一个方法。
原始的data的shape为(5,5,3),则其表示有5个(5 , 3)的二维数组,即我们把最外层的[]去掉就得到了5个五行三列的数据。同样的,变换后data的shape为(3,5,5),则其表示有3个(5 , 5)的二维数组,即我们把最外层的[]去掉就得到了3个五行五列的数据。
相信通过前面的叙述大家应该对transforms.ToTensor有了一定的了解,下面将来说说这个transforms.Normalize????????????同样的,我们先给出官方的定义,如下图所示:
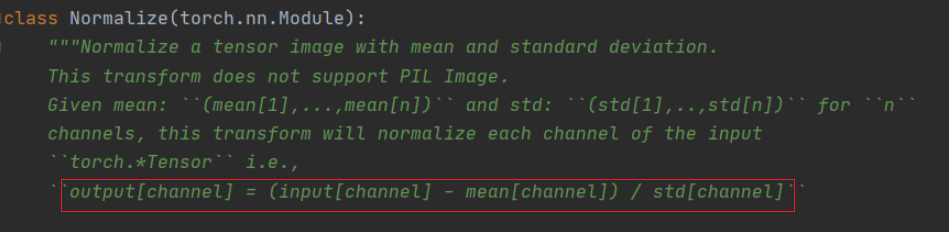
可以看到这个函数的输出output[channel] = (input[channel] - mean[channel]) / std[channel]。这里[channel]的意思是指对特征图的每个通道都进行这样的操作。【mean为均值,std为标准差】接下来我们看第一张图片中的代码,即

这里的第一个参数(0.5,0.5,0.5)表示每个通道的均值都是0.5,第二个参数(0.5,0.5,0.5)表示每个通道的方差都为0.5。【因为图像一般是三个通道,所以这里的向量都是1x3的】有了这两个参数后,当我们传入一个图像时,就会按照上面的公式对图像进行变换。【注意:这里说图像其实也不够准确,因为这个函数传入的格式不能为PIL Image,我们应该先将其转换为Tensor格式】
说了这么多,那么这个函数到底有什么用呢?我们通过前面的ToTensor已经将数据归一化到了0-1之间,现在又接上了一个Normalize函数有什么用呢?其实Normalize函数做的是将数据变换到了[-1,1]之间。之前的数据为0-1,当取0时,output =(0 - 0.5)/ 0.5 = -1;当取1时,output =(1 - 0.5)/ 0.5 = 1。这样就把数据统一到了[-1,1]之间了那么问题又来了,数据统一到[-1,1]有什么好处呢?数据如果分布在(0,1)之间,可能实际的bias,就是神经网络的输入b会比较大,而模型初始化时b=0的,这样会导致神经网络收敛比较慢,经过Normalize后,可以加快模型的收敛速度。【这句话是再网络上找到最多的解释,自己也不确定其正确性】
读到这里大家是不是以为就完了呢?这里还想和大家唠上一唠上面的两个参数(0.5,0.5,0.5)是怎么得来的呢?这是根据数据集中的数据计算出的均值和标准差,所以往往不同的数据集这两个值是不同的?这里再举一个例子帮助大家理解其计算过程。同样采用上文例子中提到的数据。
上文已经得到了经ToTensor转换后的数据,现需要求出该数据每个通道的mean和std。
# 需要对数据进行扩维,增加batch维度 data = torch.unsqueeze(data,0) #在pytorch中一般都是(batch,C,H,W) nb_samples = 0. #创建3维的空列表 channel_mean = torch.zeros(3) channel_std = torch.zeros(3) N, C, H, W = data.shape[:4] data = data.view(N, C, -1) #将数据的H,W合并 #展平后,w,h属于第2维度,对他们求平均,sum(0)为将同一纬度的数据累加 channel_mean += data.mean(2).sum(0) #展平后,w,h属于第2维度,对他们求标准差,sum(0)为将同一纬度的数据累加 channel_std += data.std(2).sum(0) #获取所有batch的数据,这里为1 nb_samples += N #获取同一batch的均值和标准差 channel_mean /= nb_samples channel_std /= nb_samples print(channel_mean, channel_std) #结果为tensor([0.0118, 0.0118, 0.0118]) tensor([0.0057, 0.0057, 0.0057])
将上述得到的mean和std带入公式,计算输出。
for i in range(3): data[i] = (data[i] - channel_mean[i]) / channel_std[i] print(data)
输出结果:

从结果可以看出,我们计算的mean和std并不是0.5,且最后的结果也没有在[-1,1]之间。
读到这里,这篇“pytorch中的transforms.ToTensor和transforms.Normalize怎么实现”文章已经介绍完毕,想要掌握这篇文章的知识点还需要大家自己动手实践使用过才能领会,如果想了解更多相关内容的文章,欢迎关注亿速云行业资讯频道。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





