PythonиҮӘеҠЁеҢ–и„ҡжң¬жҖҺд№ҲеҶҷ
иҝҷзҜҮж–Үз« дё»иҰҒд»Ӣз»ҚдәҶPythonиҮӘеҠЁеҢ–и„ҡжң¬жҖҺд№ҲеҶҷзҡ„зӣёе…ізҹҘиҜҶпјҢеҶ…е®№иҜҰз»Ҷжҳ“жҮӮпјҢж“ҚдҪңз®ҖеҚ•еҝ«жҚ·пјҢе…·жңүдёҖе®ҡеҖҹйүҙд»·еҖјпјҢзӣёдҝЎеӨ§е®¶йҳ…иҜ»е®ҢиҝҷзҜҮPythonиҮӘеҠЁеҢ–и„ҡжң¬жҖҺд№ҲеҶҷж–Үз« йғҪдјҡжңүжүҖ收иҺ·пјҢдёӢйқўжҲ‘们дёҖиө·жқҘзңӢзңӢеҗ§гҖӮ

1гҖҒиҮӘеҠЁеҢ–йҳ…иҜ»зҪ‘йЎөж–°й—»
иҝҷдёӘи„ҡжң¬иғҪеӨҹе®һзҺ°д»ҺзҪ‘йЎөдёӯжҠ“еҸ–ж–Үжң¬пјҢ然еҗҺиҮӘеҠЁеҢ–иҜӯйҹіжң—иҜ»пјҢеҪ“дҪ жғіеҗ¬ж–°й—»зҡ„ж—¶еҖҷпјҢиҝҷжҳҜдёӘдёҚй”ҷзҡ„йҖүжӢ©гҖӮ
д»Јз ҒеҲҶдёәдёӨеӨ§йғЁеҲҶпјҢ第дёҖйҖҡиҝҮзҲ¬иҷ«жҠ“еҸ–зҪ‘йЎөж–Үжң¬е‘ўпјҢ第дәҢйҖҡиҝҮйҳ…иҜ»е·Ҙе…·жқҘжң—иҜ»ж–Үжң¬гҖӮ
йңҖиҰҒзҡ„第дёүж–№еә“пјҡ
Beautiful Soup - з»Ҹе…ёзҡ„HTML/XMLж–Үжң¬и§ЈжһҗеҷЁпјҢз”ЁжқҘжҸҗеҸ–зҲ¬дёӢжқҘзҡ„зҪ‘йЎөдҝЎжҒҜ
requests - еҘҪз”ЁеҲ°йҖҶеӨ©зҡ„HTTPе·Ҙе…·пјҢз”ЁжқҘеҗ‘зҪ‘йЎөеҸ‘йҖҒиҜ·жұӮиҺ·еҸ–ж•°жҚ®
Pyttsx3 - е°Ҷж–Үжң¬иҪ¬жҚўдёәиҜӯйҹіпјҢ并жҺ§еҲ¶йҖҹзҺҮгҖҒйў‘зҺҮе’ҢиҜӯйҹі
import pyttsx3
import requests
from bs4 import BeautifulSoup
engine = pyttsx3.init('sapi5')
voices = engine.getProperty('voices')
newVoiceRate = 130 ## Reduce The Speech Rate
engine.setProperty('rate',newVoiceRate)
engine.setProperty('voice', voices[1].id)
def speak(audio):
engine.say(audio)
engine.runAndWait()
text = str(input("Paste article\n"))
res = requests.get(text)
soup = BeautifulSoup(res.text,'html.parser')
articles = []
for i in range(len(soup.select('.p'))):
article = soup.select('.p')[i].getText().strip()
articles.append(article)
text = " ".join(articles)
speak(text)
# engine.save_to_file(text, 'test.mp3') ## If you want to save the speech as a audio file
engine.runAndWait()2гҖҒиҮӘеҠЁеҢ–ж•°жҚ®жҺўзҙў
ж•°жҚ®жҺўзҙўжҳҜж•°жҚ®з§‘еӯҰйЎ№зӣ®зҡ„第дёҖжӯҘпјҢдҪ йңҖиҰҒдәҶи§Јж•°жҚ®зҡ„еҹәжң¬дҝЎжҒҜжүҚиғҪиҝӣдёҖжӯҘеҲҶжһҗжӣҙж·ұзҡ„д»·еҖјгҖӮ
дёҖиҲ¬жҲ‘们дјҡз”ЁpandasгҖҒmatplotlibзӯүе·Ҙе…·жқҘжҺўзҙўж•°жҚ®пјҢдҪҶйңҖиҰҒиҮӘе·ұзј–еҶҷеӨ§йҮҸд»Јз ҒпјҢеҰӮжһңжғіжҸҗй«ҳж•ҲзҺҮпјҢDtaleжҳҜдёӘдёҚй”ҷзҡ„йҖүжӢ©гҖӮ
Dtaleзү№зӮ№жҳҜз”ЁдёҖиЎҢд»Јз Ғз”ҹжҲҗиҮӘеҠЁеҢ–еҲҶжһҗжҠҘе‘ҠпјҢе®ғз»“еҗҲдәҶFlaskеҗҺз«Ҝе’ҢReactеүҚз«ҜпјҢдёәжҲ‘们жҸҗдҫӣдәҶдёҖз§ҚжҹҘзңӢе’ҢеҲҶжһҗPandasж•°жҚ®з»“жһ„зҡ„з®Җдҫҝж–№жі•гҖӮ
жҲ‘们еҸҜд»ҘеңЁJupyterдёҠе®һз”ЁDtaleгҖӮ
йңҖиҰҒзҡ„第дёүж–№еә“пјҡ
Dtale - иҮӘеҠЁз”ҹжҲҗеҲҶжһҗжҠҘе‘Ҡ
### Importing Seaborn Library For Some Datasets
import seaborn as sns
### Printing Inbuilt Datasets of Seaborn Library
print(sns.get_dataset_names())
### Loading Titanic Dataset
df=sns.load_dataset('titanic')
### Importing The Library
import dtale
#### Generating Quick Summary
dtale.show(df)
3гҖҒиҮӘеҠЁеҸ‘йҖҒеӨҡе°ҒйӮ®д»¶
иҝҷдёӘи„ҡжң¬еҸҜд»Ҙеё®еҠ©жҲ‘们жү№йҮҸе®ҡж—¶еҸ‘йҖҒйӮ®д»¶пјҢйӮ®д»¶еҶ…е®№гҖҒйҷ„件д№ҹеҸҜд»ҘиҮӘе®ҡд№үи°ғж•ҙпјҢйқһеёёзҡ„е®һз”ЁгҖӮ
зӣёжҜ”иҫғйӮ®д»¶е®ўжҲ·з«ҜпјҢPythonи„ҡжң¬зҡ„дјҳзӮ№еңЁдәҺеҸҜд»ҘжҷәиғҪгҖҒжү№йҮҸгҖҒй«ҳе®ҡеҲ¶еҢ–ең°йғЁзҪІйӮ®д»¶жңҚеҠЎгҖӮ
йңҖиҰҒзҡ„第дёүж–№еә“пјҡ
Email - з”ЁдәҺз®ЎзҗҶз”өеӯҗйӮ®д»¶ж¶ҲжҒҜ
Smtlib - еҗ‘SMTPжңҚеҠЎеҷЁеҸ‘йҖҒз”өеӯҗйӮ®д»¶пјҢе®ғе®ҡд№үдәҶдёҖдёӘ SMTP е®ўжҲ·з«ҜдјҡиҜқеҜ№иұЎпјҢиҜҘеҜ№иұЎеҸҜе°ҶйӮ®д»¶еҸ‘йҖҒеҲ°дә’иҒ”зҪ‘дёҠд»»дҪ•еёҰжңү SMTP жҲ– ESMTP зӣ‘еҗ¬зЁӢеәҸзҡ„и®Ўз®—жңә
Pandas - з”ЁдәҺж•°жҚ®еҲҶжһҗжё…жҙ—ең°е·Ҙе…·
import smtplib
from email.message import EmailMessage
import pandas as pd
def send_email(remail, rsubject, rcontent):
email = EmailMessage() ## Creating a object for EmailMessage
email['from'] = 'The Pythoneer Here' ## Person who is sending
email['to'] = remail ## Whom we are sending
email['subject'] = rsubject ## Subject of email
email.set_content(rcontent) ## content of email
with smtplib.SMTP(host='smtp.gmail.com',port=587)as smtp:
smtp.ehlo() ## server object
smtp.starttls() ## used to send data between server and client
smtp.login("deltadelta371@gmail.com","delta@371") ## login id and password of gmail
smtp.send_message(email) ## Sending email
print("email send to ",remail) ## Printing success message
if __name__ == '__main__':
df = pd.read_excel('list.xlsx')
length = len(df)+1
for index, item in df.iterrows():
email = item[0]
subject = item[1]
content = item[2]
send_email(email,subject,content)4гҖҒе°Ҷ PDF иҪ¬жҚўдёәйҹійў‘ж–Ү件
и„ҡжң¬еҸҜд»Ҙе°Ҷ pdf иҪ¬жҚўдёәйҹійў‘ж–Ү件пјҢеҺҹзҗҶд№ҹеҫҲз®ҖеҚ•пјҢйҰ–е…Ҳз”Ё PyPDF жҸҗеҸ– pdf дёӯзҡ„ж–Үжң¬пјҢ然еҗҺз”Ё Pyttsx3 е°Ҷж–Үжң¬иҪ¬иҜӯйҹігҖӮ
import pyttsx3,PyPDF2
pdfreader = PyPDF2.PdfFileReader(open('story.pdf','rb'))
speaker = pyttsx3.init()
for page_num in range(pdfreader.numPages):
text = pdfreader.getPage(page_num).extractText() ## extracting text from the PDF
cleaned_text = text.strip().replace('\n',' ') ## Removes unnecessary spaces and break lines
print(cleaned_text) ## Print the text from PDF
#speaker.say(cleaned_text) ## Let The Speaker Speak The Text
speaker.save_to_file(cleaned_text,'story.mp3') ## Saving Text In a audio file 'story.mp3'
speaker.runAndWait()
speaker.stop()5гҖҒд»ҺеҲ—иЎЁдёӯж’ӯж”ҫйҡҸжңәйҹід№җ
иҝҷдёӘи„ҡжң¬дјҡд»ҺжӯҢжӣІж–Ү件еӨ№дёӯйҡҸжңәйҖүжӢ©дёҖйҰ–жӯҢиҝӣиЎҢж’ӯж”ҫпјҢйңҖиҰҒжіЁж„Ҹзҡ„жҳҜ os.startfile д»…ж”ҜжҢҒ Windows зі»з»ҹгҖӮ
import random, os
music_dir = 'G:\\new english songs'
songs = os.listdir(music_dir)
song = random.randint(0,len(songs))
print(songs[song]) ## Prints The Song Name
os.startfile(os.path.join(music_dir, songs[0]))
6гҖҒжҷәиғҪеӨ©ж°”дҝЎжҒҜ
еӣҪ家气иұЎеұҖзҪ‘з«ҷжҸҗдҫӣиҺ·еҸ–еӨ©ж°”йў„жҠҘзҡ„ APIпјҢзӣҙжҺҘиҝ”еӣһ json ж јејҸзҡ„еӨ©ж°”ж•°жҚ®гҖӮжүҖд»ҘеҸӘйңҖиҰҒд»Һ json йҮҢеҸ–еҮәеҜ№еә”зҡ„еӯ—ж®өе°ұеҸҜд»ҘдәҶгҖӮ
дёӢйқўжҳҜжҢҮе®ҡеҹҺеёӮ(еҺҝгҖҒеҢә)еӨ©ж°”зҡ„зҪ‘еқҖпјҢзӣҙжҺҘжү“ејҖзҪ‘еқҖпјҢе°ұдјҡиҝ”еӣһеҜ№еә”еҹҺеёӮзҡ„еӨ©ж°”ж•°жҚ®гҖӮжҜ”еҰӮпјҡ
http://www.weather.com.cn/data/cityinfo/101021200.html дёҠжө·еҫҗжұҮеҢәеҜ№еә”зҡ„еӨ©ж°”зҪ‘еқҖгҖӮ
е…·дҪ“д»Јз ҒеҰӮдёӢпјҡ
mport requests
import json
import logging as log
def get_weather_wind(url):
r = requests.get(url)
if r.status_code != 200:
log.error("Can't get weather data!")
info = json.loads(r.content.decode())
# get wind data
data = info['weatherinfo']
WD = data['WD']
WS = data['WS']
return "{}({})".format(WD, WS)
def get_weather_city(url):
# open url and get return data
r = requests.get(url)
if r.status_code != 200:
log.error("Can't get weather data!")
# convert string to json
info = json.loads(r.content.decode())
# get useful data
data = info['weatherinfo']
city = data['city']
temp1 = data['temp1']
temp2 = data['temp2']
weather = data['weather']
return "{} {} {}~{}".format(city, weather, temp1, temp2)
if __name__ == '__main__':
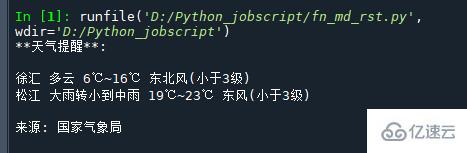
msg = """**еӨ©ж°”жҸҗйҶ’**:
{} {}
{} {}
жқҘжәҗ: еӣҪ家气иұЎеұҖ
""".format(
get_weather_city('http://www.weather.com.cn/data/cityinfo/101021200.html'),
get_weather_wind('http://www.weather.com.cn/data/sk/101021200.html'),
get_weather_city('http://www.weather.com.cn/data/cityinfo/101020900.html'),
get_weather_wind('http://www.weather.com.cn/data/sk/101020900.html') )
print(msg)иҝҗиЎҢз»“жһңеҰӮдёӢжүҖзӨәпјҡ
7гҖҒй•ҝзҪ‘еқҖеҸҳзҹӯзҪ‘еқҖ
жңүж—¶пјҢйӮЈдәӣеӨ§URLеҸҳеҫ—йқһеёёжҒјзҒ«пјҢеҫҲйҡҫйҳ…иҜ»е’Ңе…ұдә«пјҢжӯӨи„ҡеҸҜд»Ҙе°Ҷй•ҝзҪ‘еқҖеҸҳдёәзҹӯзҪ‘еқҖгҖӮ
import contextlib
from urllib.parse import urlencode
from urllib.request import urlopen
import sys
def make_tiny(url):
request_url = ('http://tinyurl.com/api-create.php?' +
urlencode({'url':url}))
with contextlib.closing(urlopen(request_url)) as response:
return response.read().decode('utf-8')
def main():
for tinyurl in map(make_tiny, sys.argv[1:]):
print(tinyurl)
if __name__ == '__main__':
main()иҝҷдёӘи„ҡжң¬йқһеёёе®һз”ЁпјҢжҜ”еҰӮиҜҙжңүеҶ…е®№е№іеҸ°жҳҜеұҸи”Ҫе…¬дј—еҸ·ж–Үз« зҡ„пјҢйӮЈд№Ҳе°ұеҸҜд»ҘжҠҠе…¬дј—еҸ·ж–Үз« зҡ„й“ҫжҺҘеҸҳдёәзҹӯй“ҫжҺҘпјҢ然еҗҺжҸ’е…Ҙе…¶дёӯпјҢе°ұеҸҜд»Ҙе®һзҺ°з»•иҝҮ
8гҖҒжё…зҗҶдёӢиҪҪж–Ү件еӨ№
дё–з•ҢдёҠжңҖж··д№ұзҡ„дәӢжғ…д№ӢдёҖжҳҜејҖеҸ‘дәәе‘ҳзҡ„дёӢиҪҪж–Ү件еӨ№пјҢйҮҢйқўеӯҳж”ҫдәҶеҫҲеӨҡжқӮд№ұж— з« зҡ„ж–Ү件пјҢжӯӨи„ҡжң¬е°Ҷж №жҚ®еӨ§е°ҸйҷҗеҲ¶жқҘжё…зҗҶжӮЁзҡ„дёӢиҪҪж–Ү件еӨ№пјҢжңүйҷҗжё…зҗҶжҜ”иҫғж—§зҡ„ж–Ү件пјҡ
import os
import threading
import time
def get_file_list(file_path): #ж–Ү件жҢүжңҖеҗҺдҝ®ж”№ж—¶й—ҙжҺ’еәҸ
dir_list = os.listdir(file_path)
if not dir_list:
return
else:
dir_list = sorted(dir_list, key=lambda x: os.path.getmtime(os.path.join(file_path, x)))
return dir_list
def get_size(file_path):
"""[summary]
Args:
file_path ([type]): [зӣ®еҪ•]
Returns:
[type]: иҝ”еӣһзӣ®еҪ•еӨ§е°ҸпјҢMB
"""
totalsize=0
for filename in os.listdir(file_path):
totalsize=totalsize+os.path.getsize(os.path.join(file_path, filename))
#print(totalsize / 1024 / 1024)
return totalsize / 1024 / 1024
def detect_file_size(file_path, size_Max, size_Del):
"""[summary]
Args:
file_path ([type]): [ж–Ү件зӣ®еҪ•]
size_Max ([type]): [ж–Ү件еӨ№жңҖеӨ§еӨ§е°Ҹ]
size_Del ([type]): [и¶…иҝҮsize_Maxж—¶иҰҒеҲ йҷӨзҡ„еӨ§е°Ҹ]
"""
print(get_size(file_path))
if get_size(file_path) > size_Max:
fileList = get_file_list(file_path)
for i in range(len(fileList)):
if get_size(file_path) > (size_Max - size_Del):
print ("del :%d %s" % (i + 1, fileList[i]))
#os.remove(file_path + fileList[i])е…ідәҺвҖңPythonиҮӘеҠЁеҢ–и„ҡжң¬жҖҺд№ҲеҶҷвҖқиҝҷзҜҮж–Үз« зҡ„еҶ…е®№е°ұд»Ӣз»ҚеҲ°иҝҷйҮҢпјҢж„ҹи°ўеҗ„дҪҚзҡ„йҳ…иҜ»пјҒзӣёдҝЎеӨ§е®¶еҜ№вҖңPythonиҮӘеҠЁеҢ–и„ҡжң¬жҖҺд№ҲеҶҷвҖқзҹҘиҜҶйғҪжңүдёҖе®ҡзҡ„дәҶи§ЈпјҢеӨ§е®¶еҰӮжһңиҝҳжғіеӯҰд№ жӣҙеӨҡзҹҘиҜҶпјҢж¬ўиҝҺе…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“гҖӮ





