今天小编给大家分享一下hashmap的扩容机制怎么理解的相关知识点,内容详细,逻辑清晰,相信大部分人都还太了解这方面的知识,所以分享这篇文章给大家参考一下,希望大家阅读完这篇文章后有所收获,下面我们一起来了解一下吧。
hashmap的扩容机制是:重新计算容量,用一个新的数组替换原来的数组。重新计算原数组的所有数据并插入一个新数组,然后指向新数组;如果数组在容量扩展前已达到最大值,则直接将阈值设置为最大整数返回。
什么是扩容(resize)?
扩容(resize):就是重新计算容量,向HashMap对象里不停的添加元素,而HashMap对象内部的数组无法装载更多的元素时,对象就需要扩大数组的长度,以便能装入更多的元素。当然Java里的数组是无法自动扩容的,方法是使用一个新的数组代替已有的容量小的数组,就像我们用一个小桶装水,如果想装更多的水,就得换大水桶。
什么时候扩容?
当向容器添加元素的时候,会判断当前容器的元素个数,如果大于等于阈值(threshold),即当前容器内的元素个数大于当前数组的长度乘以加载因子的值的时候,就要自动扩容了。
hashmap扩容原理
hashMap扩容就是重新计算容量,向hashMap不停的添加元素,当hashMap无法装载新的元素,对象将需要扩大数组容量,以便装入更多的元素。
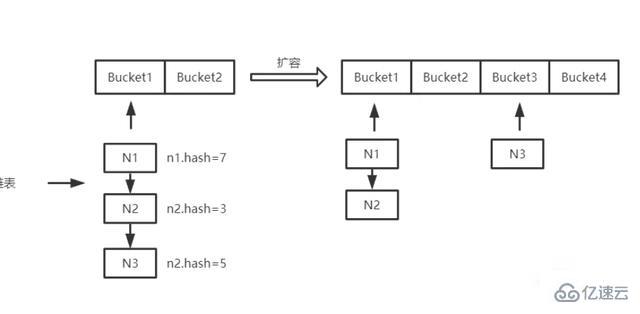
HashMap容量扩展的特性,加载因子越大,空间利用率越高,扩容前需要填充的元素越多,put操作越快,但链表容易过长,hash碰撞概率大,get操作慢。加载因子越小,get操作越快,链表越短,hash碰撞概率低。但是,空间利用率低。put元素太多会导致频繁扩容,影响性能。
HashMap的容量扩展原理:Hashmap的方法是用新数组替换原数组,重新计算原数组中的所有数据,插入新数组,然后指向新数组;如果数组在扩容前已经达到最大,则直接将阈值设置为最大整数返回。
扩容的过程
下面采用源代码+图片+文字描述的方式介绍HashMap的扩容过程。
/**
* HashMap 添加节点
*
* @param hash 当前key生成的hashcode
* @param key 要添加到 HashMap 的key
* @param value 要添加到 HashMap 的value
* @param bucketIndex 桶,也就是这个要添加 HashMap 里的这个数据对应到数组的位置下标
*/
void addEntry(int hash, K key, V value, int bucketIndex) {
//数组扩容条件:1.已经存在的key-value mappings的个数大于等于阈值
// 2.底层数组的bucketIndex坐标处不等于null
if ((size >= threshold) && (null != table[bucketIndex])) {
resize(2 * table.length);//扩容之后,数组长度变了
hash = (null != key) ? hash(key) : 0;//为什么要再次计算一下hash值呢?
bucketIndex = indexFor(hash, table.length);//扩容之后,数组长度变了,在数组的下标跟数组长度有关,得重算。
}
createEntry(hash, key, value, bucketIndex);
}
/**
* 这地方就是链表出现的地方,有2种情况
* 1,原来的桶bucketIndex处是没值的,那么就不会有链表出来啦
* 2,原来这地方有值,那么根据Entry的构造函数,把新传进来的key-value mapping放在数组上,原来的就挂在这个新来的next属性上了
*/
void createEntry(int hash, K key, V value, int bucketIndex) {
HashMap.Entry<K, V> e = table[bucketIndex];
table[bucketIndex] = new HashMap.Entry<>(hash, key, value, e);
size++;
}
上述addEntry方法中,如果size(当前容器内的元素个数)大于等于threshold(数组长度乘以负载因子),并且底层数组的bucketIndex坐标处不等于null,那么将会进行扩容(resize)。否则,不会进行扩容。
下面将着重介绍一下扩容的过程:
void resize(int newCapacity) { //传入新的容量
Entry[] oldTable = table; //引用扩容前的Entry数组
int oldCapacity = oldTable.length;
if (oldCapacity == MAXIMUM_CAPACITY) { //扩容前的数组大小如果已经达到最大(2^30)了
threshold = Integer.MAX_VALUE; //修改阈值为int的最大值(2^31-1),这样以后就不会扩容了
return;
}
Entry[] newTable = new Entry[newCapacity]; //初始化一个新的Entry数组
transfer(newTable); 此行有遗漏,勘误见下面引用 //!!将数据转移到新的Entry数组里
table = newTable; //HashMap的table属性引用新的Entry数组
threshold = (int) (newCapacity * loadFactor);此行有遗漏,勘误见下面引用//修改阈值
}
由wenni328博友修正:transfer(newTable); ==> transfer(newTable, initHashSeedAsNeeded(newCapacity));
threshold = (int) (newCapacity * loadFactor); ==> threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);
扩容前首先获取扩容前数组的引用地址存进oldTable变量中,然后判断扩容前数组长度是否达到了int类型存储的最大值,如果是则放弃此次扩容,因为数组容量已经达到最大,无法再扩容了。
下图为程序执行完Entry[] newTable = new Entry[newCapacity];代码之后的状态:
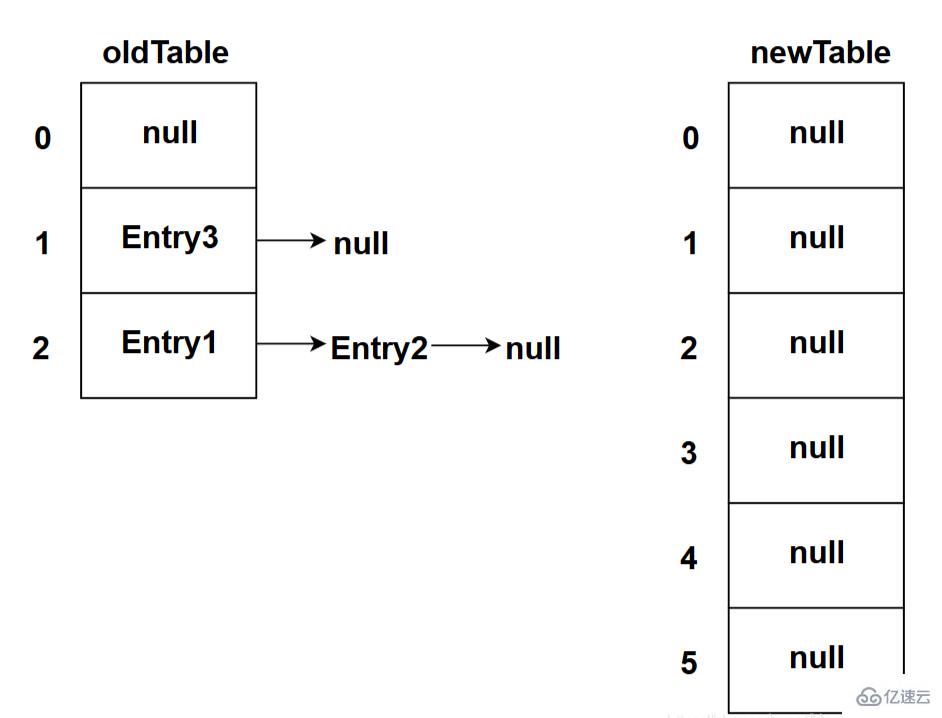
这里就是使用一个容量更大的数组来代替已有的容量小的数组,transfer()方法将原有Entry数组的元素拷贝到新的Entry数组里。
void transfer(Entry[] newTable) {
Entry[] src = table; //src引用了旧的Entry数组
int newCapacity = newTable.length;
for (int j = 0; j < src.length; j++) { //遍历旧的Entry数组
Entry<K, V> e = src[j]; //取得旧Entry数组的每个元素
if (e != null) {
src[j] = null;//释放旧Entry数组的对象引用(for循环后,旧的Entry数组不再引用任何对象)
do {
Entry<K, V> next = e.next;
int i = indexFor(e.hash, newCapacity); //!!重新计算每个元素在数组中的位置
e.next = newTable[i]; //标记[1]
newTable[i] = e; //将元素放在数组上
e = next; //访问下一个Entry链上的元素
} while (e != null);
}
}
}
static int indexFor(int h, int length) {
return h & (length - 1);
}
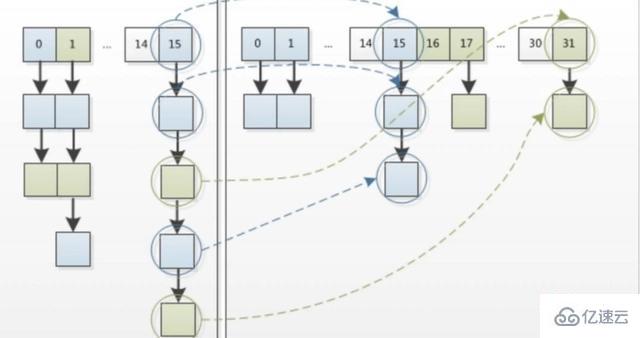
newTable[i]的引用赋给了e.next,也就是使用了单链表的头插入方式,同一位置上新元素总会被放在链表的头部位置;这样先放在一个索引上的元素终会被放到Entry链的尾部(如果发生了hash冲突的话)。在旧数组中同一条Entry链上的元素,通过重新计算索引位置后,有可能被放到了新数组的不同位置上。
下面会以图片的形式演示一下transfer的过程(下面图片的红色字体表示与上图有区别的地方,后面图片都是这样,后面红色字体说明不再赘述)
下图为程序执行完src[j] = null;代码之后的状态(这是第一次循环时的状态):
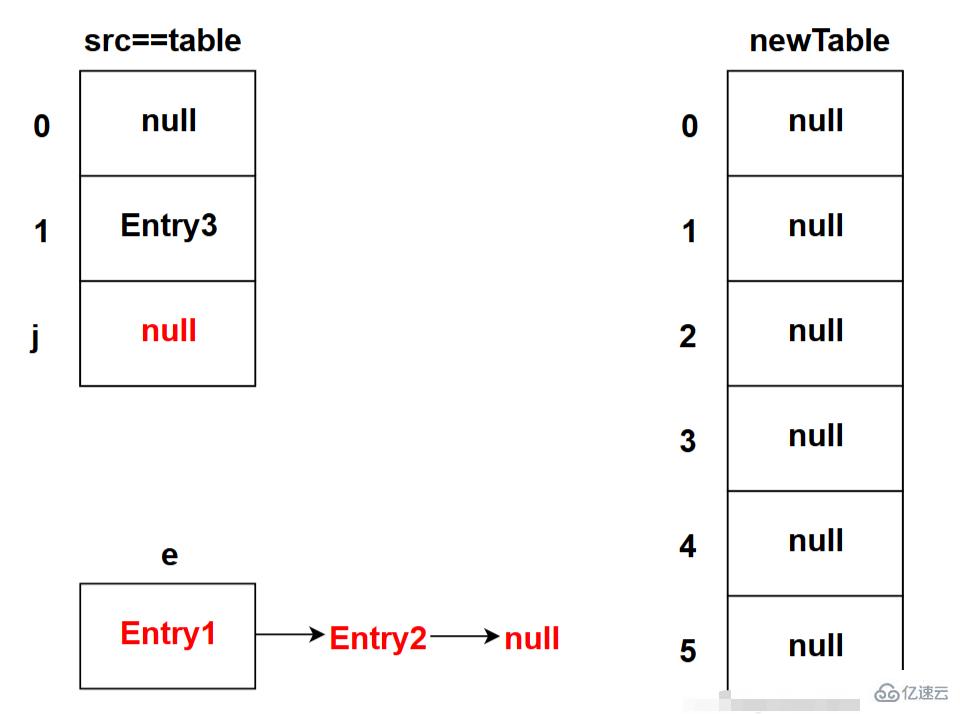
首先,将table[]数组的引用地址赋值给src[]数组。
然后,Entry<K, V> e = src[j];是将src[j]位置的链表交给e变量存储。由于src[j]位置的链表已经交给e存储了,所以可以大胆的将src[j]=null;然后等待垃圾回收。
下图为程序执行完Entry<K, V> next = e.next;代码之后的状态(这是第一次循环时的状态):
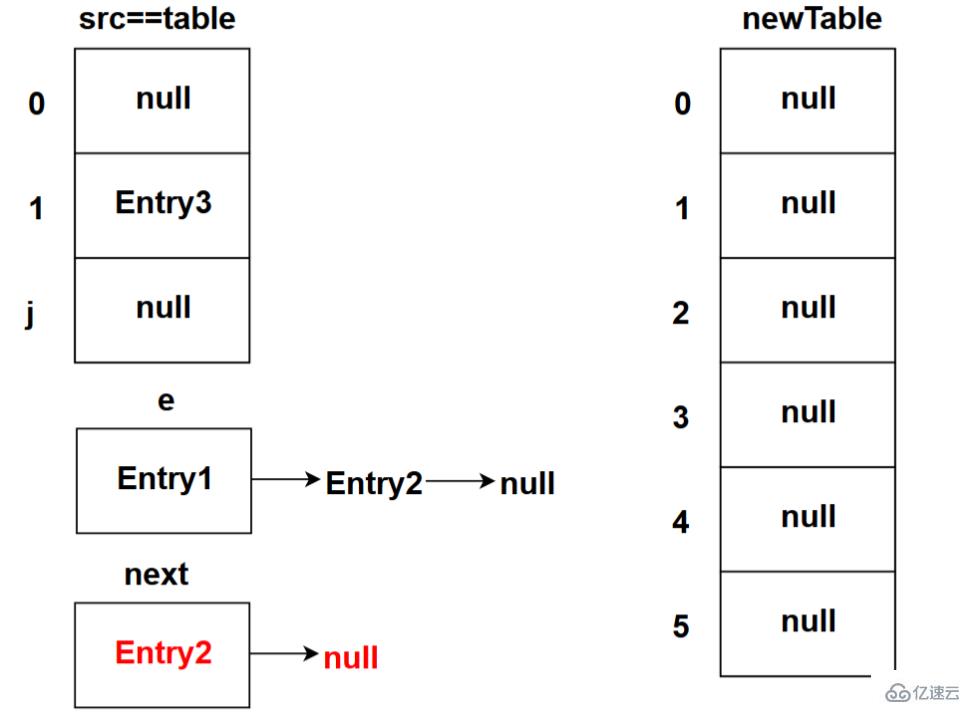
这里先将e.next的值备份至next变量中,后续代码会将e.next的指向更改,所以在这里将e.next的值备份。
下图为程序执行完e.next = newTable[i];代码之后的状态(这是第一次循环时的状态):
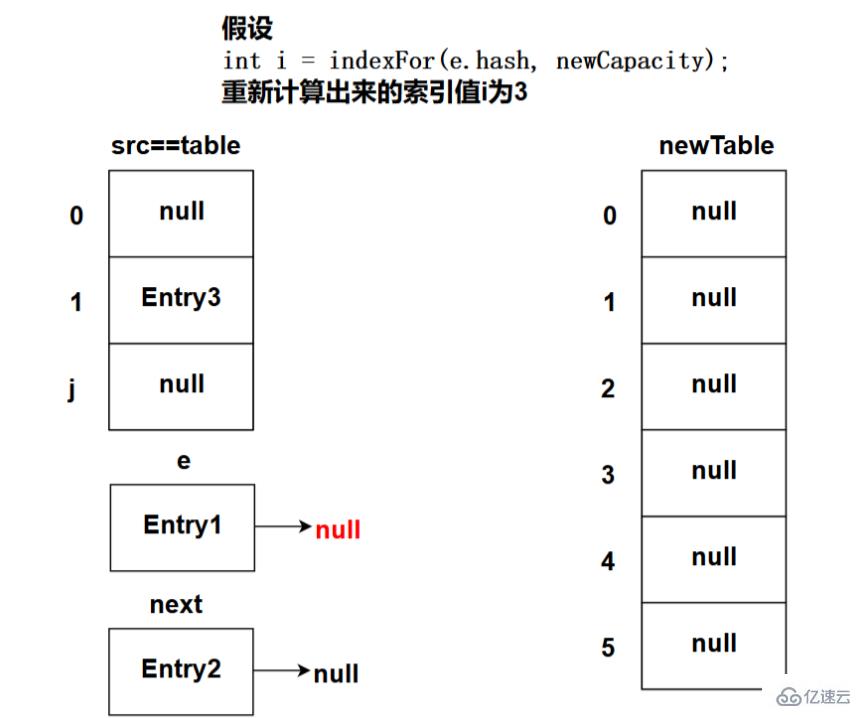
由于newTable[3]的值为null,所以e.next为null,如上图所示。
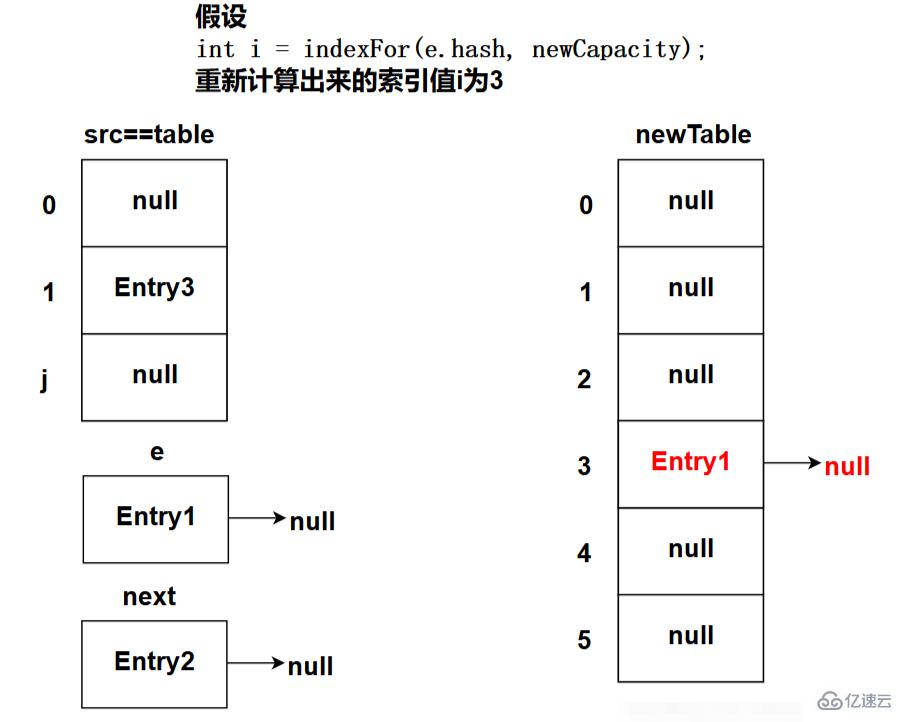
下图为程序执行完newTable[i] = e;代码之后的状态(这是第一次循环时的状态):
下图为程序执行完e = next;代码之后的状态(这是第一次循环时的状态):
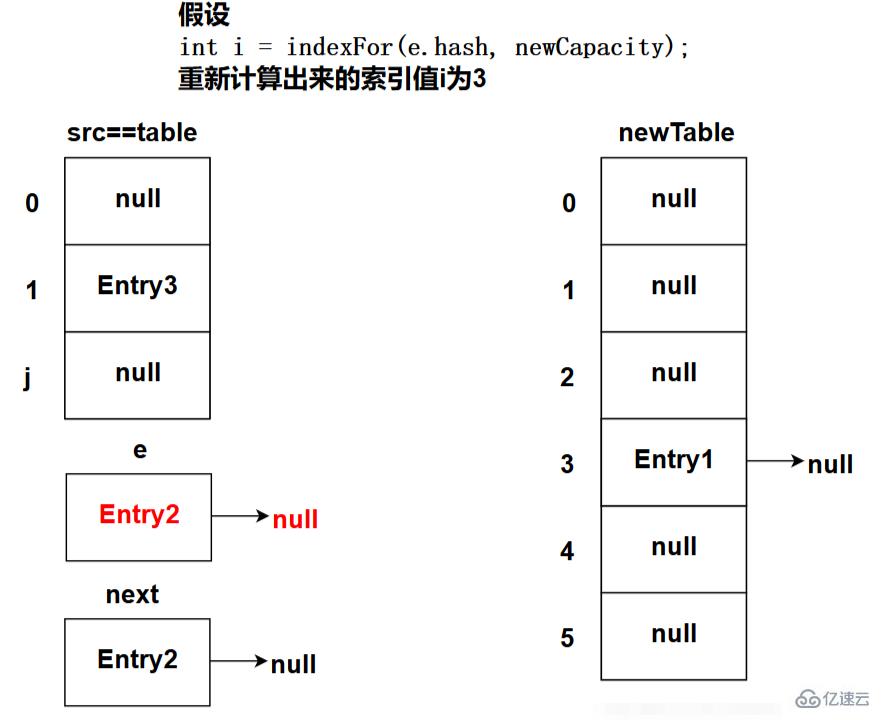
如上述所示,Entry1这个节点成功插入到了newTable中,一轮循环结束时,因为判断e!=null,所以会再重复上述过程,直至所有节点移动到newTable中。
扩容是一个特别耗性能的操作,所以当程序员在使用HashMap的时候,估算map的大小,初始化的时候给一个大致的数值,避免map进行频繁的扩容。
负载因子是可以修改的,也可以大于1,但是建议不要轻易修改,除非情况非常特殊。
HashMap是线程不安全的,不要在并发的环境中同时操作HashMap,建议使用ConcurrentHashMap。
JDK1.8引入红黑树大程度优化了HashMap的性能。
以上就是“hashmap的扩容机制怎么理解”这篇文章的所有内容,感谢各位的阅读!相信大家阅读完这篇文章都有很大的收获,小编每天都会为大家更新不同的知识,如果还想学习更多的知识,请关注亿速云行业资讯频道。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





