CиҜӯиЁҖдёӯзҡ„0й•ҝеәҰж•°з»„жңүд»Җд№Ҳз”ЁйҖ”
жң¬зҜҮеҶ…е®№д»Ӣз»ҚдәҶвҖңCиҜӯиЁҖдёӯзҡ„0й•ҝеәҰж•°з»„жңүд»Җд№Ҳз”ЁйҖ”вҖқзҡ„жңүе…ізҹҘиҜҶпјҢеңЁе®һйҷ…жЎҲдҫӢзҡ„ж“ҚдҪңиҝҮзЁӢдёӯпјҢдёҚе°‘дәәйғҪдјҡйҒҮеҲ°иҝҷж ·зҡ„еӣ°еўғпјҢжҺҘдёӢжқҘе°ұи®©е°Ҹзј–еёҰйўҶеӨ§е®¶еӯҰд№ дёҖдёӢеҰӮдҪ•еӨ„зҗҶиҝҷдәӣжғ…еҶөеҗ§пјҒеёҢжңӣеӨ§е®¶д»”з»Ҷйҳ…иҜ»пјҢиғҪеӨҹеӯҰжңүжүҖжҲҗпјҒ
йӣ¶й•ҝеәҰж•°з»„жҰӮеҝө
дј—жүҖе‘ЁзҹҘ, GNU/GCC еңЁж ҮеҮҶзҡ„ C/C++ еҹәзЎҖдёҠеҒҡдәҶжңүе®һз”ЁжҖ§зҡ„жү©еұ•, йӣ¶й•ҝеәҰж•°з»„пјҲArrays of Length Zeroпјү е°ұжҳҜе…¶дёӯдёҖдёӘзҹҘеҗҚзҡ„жү©еұ•.
еӨҡж•°жғ…еҶөдёӢ, е…¶еә”з”ЁеңЁеҸҳй•ҝж•°з»„дёӯ, е…¶е®ҡд№үеҰӮдёӢпјҡ
struct Packet
{
int state;
int len;
char cData[0]; //иҝҷйҮҢзҡ„0й•ҝз»“жһ„дҪ“е°ұдёәеҸҳй•ҝз»“жһ„дҪ“жҸҗдҫӣдәҶйқһеёёеҘҪзҡ„ж”ҜжҢҒ
};йҰ–е…ҲеҜ№ 0й•ҝеәҰж•°з»„, д№ҹеҸ«жҹ”жҖ§ж•°з»„ еҒҡдёҖдёӘи§ЈйҮҠ пјҡ
з”ЁйҖ” : й•ҝеәҰдёә0зҡ„ж•°з»„зҡ„дё»иҰҒз”ЁйҖ”жҳҜдёәдәҶж»Ўи¶ійңҖиҰҒеҸҳй•ҝеәҰзҡ„з»“жһ„дҪ“
з”Ёжі• : еңЁдёҖдёӘз»“жһ„дҪ“зҡ„жңҖеҗҺ, з”іжҳҺдёҖдёӘй•ҝеәҰдёә0зҡ„ж•°з»„, е°ұеҸҜд»ҘдҪҝеҫ—иҝҷдёӘз»“жһ„дҪ“жҳҜеҸҜеҸҳй•ҝзҡ„. еҜ№дәҺзј–иҜ‘еҷЁжқҘиҜҙ, жӯӨж—¶й•ҝеәҰдёә0зҡ„数组并дёҚеҚ з”Ёз©әй—ҙ, еӣ дёәж•°з»„еҗҚжң¬иә«дёҚеҚ з©әй—ҙ, е®ғеҸӘжҳҜдёҖдёӘеҒҸ移йҮҸ, ж•°з»„еҗҚиҝҷдёӘз¬ҰеҸ·жң¬иә«д»ЈиЎЁдәҶдёҖдёӘдёҚеҸҜдҝ®ж”№зҡ„ең°еқҖеёёйҮҸ
(жіЁж„Ҹ : ж•°з»„еҗҚж°ёиҝңйғҪдёҚдјҡжҳҜжҢҮй’Ҳ!), дҪҶеҜ№дәҺиҝҷдёӘж•°з»„зҡ„еӨ§е°Ҹ, жҲ‘们еҸҜд»ҘиҝӣиЎҢеҠЁжҖҒеҲҶй…Қ
жіЁж„Ҹ пјҡеҰӮжһңз»“жһ„дҪ“жҳҜйҖҡиҝҮcallocгҖҒmallocжҲ– иҖ…newзӯүеҠЁжҖҒеҲҶй…Қж–№ејҸз”ҹжҲҗпјҢеңЁдёҚйңҖиҰҒж—¶иҰҒйҮҠж”ҫзӣёеә”зҡ„з©әй—ҙгҖӮ
дјҳзӮ№ пјҡжҜ”иө·еңЁз»“жһ„дҪ“дёӯеЈ°жҳҺдёҖдёӘжҢҮй’ҲеҸҳйҮҸгҖҒеҶҚиҝӣиЎҢеҠЁжҖҒеҲҶ й…Қзҡ„еҠһжі•пјҢиҝҷз§Қж–№жі•ж•ҲзҺҮиҰҒй«ҳгҖӮеӣ дёәеңЁи®ҝй—®ж•°з»„еҶ…е®№ж—¶пјҢдёҚйңҖиҰҒй—ҙжҺҘи®ҝй—®пјҢйҒҝе…ҚдәҶдёӨж¬Ўи®ҝеӯҳгҖӮ
зјәзӮ№ пјҡеңЁз»“жһ„дҪ“дёӯпјҢж•°з»„дёә0зҡ„ж•°з»„еҝ…йЎ»еңЁжңҖеҗҺеЈ°жҳҺпјҢдҪҝ з”ЁдёҠжңүдёҖе®ҡйҷҗеҲ¶гҖӮ
еҜ№дәҺзј–иҜ‘еҷЁиҖҢиЁҖ, ж•°з»„еҗҚд»…д»…жҳҜдёҖдёӘз¬ҰеҸ·, е®ғдёҚдјҡеҚ з”Ёд»»дҪ•з©әй—ҙ, е®ғеңЁз»“жһ„дҪ“дёӯ, еҸӘжҳҜд»ЈиЎЁдәҶдёҖдёӘеҒҸ移йҮҸ, д»ЈиЎЁдёҖдёӘдёҚеҸҜдҝ®ж”№зҡ„ең°еқҖеёёйҮҸ!
0й•ҝеәҰж•°з»„зҡ„з”ЁйҖ”
жҲ‘们и®ҫжғіиҝҷж ·дёҖдёӘеңәжҷҜ, жҲ‘们еңЁзҪ‘з»ңйҖҡдҝЎиҝҮзЁӢдёӯдҪҝз”Ёзҡ„ж•°жҚ®зј“еҶІеҢә, зј“еҶІеҢәеҢ…жӢ¬дёҖдёӘlenеӯ—ж®өе’Ңdataеӯ—ж®ө, еҲҶеҲ«ж ҮиҜҶж•°жҚ®зҡ„й•ҝеәҰе’Ңдј иҫ“зҡ„ж•°жҚ®, жҲ‘们常и§Ғзҡ„жңүеҮ з§Қи®ҫи®ЎжҖқи·Ҝпјҡ
е®ҡй•ҝж•°жҚ®зј“еҶІеҢә, и®ҫзҪ®дёҖдёӘи¶іеӨҹеӨ§е°Ҹ MAX_LENGTH зҡ„ж•°жҚ®зј“еҶІеҢә
и®ҫзҪ®дёҖдёӘжҢҮеҗ‘е®һйҷ…ж•°жҚ®зҡ„жҢҮй’Ҳ, жҜҸж¬ЎдҪҝз”Ёж—¶, жҢүз…§ж•°жҚ®зҡ„й•ҝеәҰеҠЁжҖҒзҡ„ејҖиҫҹж•°жҚ®зј“еҶІеҢәзҡ„з©әй—ҙ
жҲ‘们д»Һе®һйҷ…еңәжҷҜдёӯеә”з”Ёзҡ„и®ҫи®ЎжқҘиҖғиҷ‘他们зҡ„дјҳеҠЈ. дё»иҰҒиҖғиҷ‘зҡ„жңү, зј“еҶІеҢәз©әй—ҙзҡ„ејҖиҫҹ, йҮҠж”ҫе’Ңи®ҝй—®гҖӮ
1гҖҒе®ҡй•ҝеҢ…(ејҖиҫҹз©әй—ҙ, йҮҠж”ҫ, и®ҝй—®)пјҡ
жҜ”еҰӮжҲ‘иҰҒеҸ‘йҖҒ 1024 еӯ—иҠӮзҡ„ж•°жҚ®, еҰӮжһңз”Ёе®ҡй•ҝеҢ…, еҒҮи®ҫе®ҡй•ҝеҢ…зҡ„й•ҝеәҰ MAX_LENGTH дёә 2048, е°ұдјҡжөӘиҙ№ 1024 дёӘеӯ—иҠӮзҡ„з©әй—ҙ, д№ҹдјҡйҖ жҲҗдёҚеҝ…иҰҒзҡ„жөҒйҮҸжөӘиҙ№пјҡ
ж•°жҚ®з»“жһ„е®ҡд№үпјҡ
// е®ҡй•ҝзј“еҶІеҢә
struct max_buffer
{
int len;
char data[MAX_LENGTH];
};ж•°жҚ®з»“жһ„еӨ§е°ҸпјҡиҖғиҷ‘еҜ№йҪҗ, йӮЈд№Ҳж•°жҚ®з»“жһ„зҡ„еӨ§е°Ҹ >= sizeof(int) + sizeof(char) * MAX_LENGTH
з”ұдәҺиҖғиҷ‘еҲ°ж•°жҚ®зҡ„жәўеҮә, еҸҳй•ҝж•°жҚ®еҢ…дёӯзҡ„ data ж•°з»„й•ҝеәҰдёҖиҲ¬дјҡи®ҫзҪ®еҫ—и¶іеӨҹй•ҝи¶ід»Ҙе®№зәіжңҖеӨ§зҡ„ж•°жҚ®, еӣ жӯӨ max_buffer дёӯзҡ„ data ж•°з»„еҫҲеӨҡжғ…еҶөдёӢйғҪжІЎжңүеЎ«ж»Ўж•°жҚ®, еӣ жӯӨйҖ жҲҗдәҶжөӘиҙ№
ж•°жҚ®еҢ…зҡ„жһ„йҖ пјҡеҒҮеҰӮжҲ‘们иҰҒеҸ‘йҖҒ CURR_LENGTH = 1024 дёӘеӯ—иҠӮ, жҲ‘们еҰӮдҪ•жһ„йҖ иҝҷдёӘж•°жҚ®еҢ…е‘ўпјӣдёҖиҲ¬жқҘиҜҙ, жҲ‘们дјҡиҝ”еӣһдёҖдёӘжҢҮеҗ‘зј“еҶІеҢәж•°жҚ®з»“жһ„ max_buffer зҡ„жҢҮй’Ҳпјҡ
/// ејҖиҫҹ
if ((mbuffer = (struct max_buffer *)malloc(sizeof(struct max_buffer))) != NULL)
{
mbuffer->len = CURR_LENGTH;
memcpy(mbuffer->data, "Hello World", CURR_LENGTH);
printf("%d, %s\n", mbuffer->len, mbuffer->data);
}и®ҝй—®пјҡиҝҷж®өеҶ…еӯҳиҰҒеҲҶдёӨйғЁеҲҶдҪҝз”ЁпјӣеүҚйғЁеҲҶ 4 дёӘеӯ—иҠӮ p->len, дҪңдёәеҢ…еӨҙ(е°ұжҳҜеӨҡеҮәжқҘзҡ„йӮЈйғЁеҲҶ)пјҢиҝҷдёӘеҢ…еӨҙжҳҜз”ЁжқҘжҸҸиҝ°зҙ§жҺҘзқҖеҢ…еӨҙеҗҺйқўзҡ„ж•°жҚ®йғЁеҲҶзҡ„й•ҝеәҰпјҢиҝҷйҮҢжҳҜ 1024, жүҖд»ҘеүҚеӣӣдёӘеӯ—иҠӮиөӢеҖјдёә 1024 (既然жҲ‘们иҰҒжһ„йҖ дёҚе®ҡй•ҝж•°жҚ®еҢ…пјҢйӮЈд№ҲиҝҷдёӘеҢ…еҲ°еә•жңүеӨҡй•ҝе‘ўпјҢеӣ жӯӨпјҢжҲ‘们е°ұеҝ…йЎ»йҖҡиҝҮдёҖдёӘеҸҳйҮҸжқҘиЎЁжҳҺиҝҷдёӘж•°жҚ®еҢ…зҡ„й•ҝеәҰпјҢиҝҷе°ұжҳҜlenзҡ„дҪңз”Ё)пјӣиҖҢзҙ§жҺҘе…¶еҗҺзҡ„еҶ…еӯҳжҳҜзңҹжӯЈзҡ„ж•°жҚ®йғЁеҲҶ, йҖҡиҝҮ p->data, жңҖеҗҺ, иҝӣиЎҢдёҖдёӘ memcpy() еҶ…еӯҳжӢ·иҙқ, жҠҠиҰҒеҸ‘йҖҒзҡ„ж•°жҚ®еЎ«е…ҘеҲ°иҝҷж®өеҶ…еӯҳеҪ“дёӯ
йҮҠж”ҫпјҡйӮЈд№ҲеҪ“дҪҝз”Ёе®ҢжҜ•йҮҠж”ҫж•°жҚ®зҡ„з©әй—ҙзҡ„ж—¶еҖҷ, зӣҙжҺҘйҮҠж”ҫе°ұеҸҜд»ҘдәҶ
/// й”ҖжҜҒ
free(mbuffer);
mbuffer = NULL;
2гҖҒе°Ҹз»“:
дҪҝз”Ёе®ҡй•ҝж•°з»„, дҪңдёәж•°жҚ®зј“еҶІеҢә, дёәдәҶйҒҝе…ҚйҖ жҲҗзј“еҶІеҢәжәўеҮә, ж•°з»„зҡ„еӨ§е°ҸдёҖиҲ¬и®ҫдёәи¶іеӨҹзҡ„з©әй—ҙ MAX_LENGTH, иҖҢе®һйҷ…дҪҝз”ЁиҝҮзЁӢдёӯ, иҫҫеҲ° MAX_LENGTH й•ҝеәҰзҡ„ж•°жҚ®еҫҲе°‘, йӮЈд№ҲеӨҡж•°жғ…еҶөдёӢ, зј“еҶІеҢәзҡ„еӨ§йғЁеҲҶз©әй—ҙйғҪжҳҜжөӘиҙ№жҺүзҡ„
дҪҶжҳҜдҪҝз”ЁиҝҮзЁӢеҫҲз®ҖеҚ•, ж•°жҚ®з©әй—ҙзҡ„ејҖиҫҹе’ҢйҮҠж”ҫз®ҖеҚ•, ж— йңҖзЁӢеәҸе‘ҳиҖғиҷ‘йўқеӨ–зҡ„ж“ҚдҪң
3гҖҒ жҢҮй’Ҳж•°жҚ®еҢ…(ејҖиҫҹз©әй—ҙ, йҮҠж”ҫ, и®ҝй—®):
еҰӮжһңдҪ е°ҶдёҠйқўзҡ„й•ҝеәҰдёә MAX_LENGTH зҡ„е®ҡй•ҝж•°з»„жҚўдёәжҢҮй’Ҳ, жҜҸж¬ЎдҪҝз”Ёж—¶еҠЁжҖҒзҡ„ејҖиҫҹ CURR_LENGTH еӨ§е°Ҹзҡ„з©әй—ҙ, йӮЈд№Ҳе°ұйҒҝе…ҚйҖ жҲҗ MAX_LENGTH - CURR_LENGTH з©әй—ҙзҡ„жөӘиҙ№, еҸӘжөӘиҙ№дәҶдёҖдёӘжҢҮй’Ҳеҹҹзҡ„з©әй—ҙпјҡ
ж•°жҚ®еҢ…е®ҡд№үпјҡ
struct point_buffer
{
int len;
char *data;
};ж•°жҚ®з»“жһ„еӨ§е°ҸпјҡиҖғиҷ‘еҜ№йҪҗ, йӮЈд№Ҳж•°жҚ®з»“жһ„зҡ„еӨ§е°Ҹ >= sizeof(int) + sizeof(char *)
з©әй—ҙеҲҶй…ҚпјҡдҪҶжҳҜд№ҹйҖ жҲҗдәҶдҪҝз”ЁеңЁеҲҶй…ҚеҶ…еӯҳж—¶пјҢйңҖйҮҮз”ЁдёӨжӯҘ
// =====================
// жҢҮй’Ҳж•°з»„ еҚ з”Ё-ејҖиҫҹ-й”ҖжҜҒ
// =====================
/// еҚ з”Ё
printf("the length of struct test3:%d\n",sizeof(struct point_buffer));
/// ејҖиҫҹ
if ((pbuffer = (struct point_buffer *)malloc(sizeof(struct point_buffer))) != NULL)
{
pbuffer->len = CURR_LENGTH;
if ((pbuffer->data = (char *)malloc(sizeof(char) * CURR_LENGTH)) != NULL)
{
memcpy(pbuffer->data, "Hello World", CURR_LENGTH);
printf("%d, %s\n", pbuffer->len, pbuffer->data);
}
}йҰ–е…Ҳ, йңҖдёәз»“жһ„дҪ“еҲҶй…ҚдёҖеқ—еҶ…еӯҳз©әй—ҙпјӣе…¶ж¬ЎеҶҚдёәз»“жһ„дҪ“дёӯзҡ„жҲҗе‘ҳеҸҳйҮҸеҲҶй…ҚеҶ…еӯҳз©әй—ҙгҖӮ
иҝҷж ·дёӨж¬ЎеҲҶй…Қзҡ„еҶ…еӯҳжҳҜдёҚиҝһз»ӯзҡ„, йңҖиҰҒеҲҶеҲ«еҜ№е…¶иҝӣиЎҢз®ЎзҗҶ. еҪ“дҪҝз”Ёй•ҝеәҰдёәзҡ„ж•°з»„ж—¶, еҲҷжҳҜйҮҮз”ЁдёҖж¬ЎеҲҶй…Қзҡ„еҺҹеҲҷ, дёҖж¬ЎжҖ§е°ҶжүҖйңҖзҡ„еҶ…еӯҳе…ЁйғЁеҲҶй…Қз»ҷе®ғгҖӮ
йҮҠж”ҫпјҡзӣёеҸҚ, йҮҠж”ҫж—¶д№ҹжҳҜдёҖж ·зҡ„пјҡ
/// й”ҖжҜҒ
free(pbuffer->data);
free(pbuffer);
pbuffer = NULL;
е°Ҹз»“пјҡ
дҪҝз”ЁжҢҮй’Ҳз»“жһңдҪңдёәзј“еҶІеҢә, еҸӘеӨҡдҪҝз”ЁдәҶдёҖдёӘжҢҮй’ҲеӨ§е°Ҹзҡ„з©әй—ҙ, ж— йңҖдҪҝз”Ё MAX_LENGTH й•ҝеәҰзҡ„ж•°з»„, дёҚдјҡйҖ жҲҗз©әй—ҙзҡ„еӨ§йҮҸжөӘиҙ№
дҪҶйӮЈжҳҜејҖиҫҹз©әй—ҙж—¶, йңҖиҰҒйўқеӨ–ејҖиҫҹж•°жҚ®еҹҹзҡ„з©әй—ҙ, ж–Ҫж”ҫж—¶еҖҷд№ҹйңҖиҰҒжҳҫзӨәйҮҠж”ҫж•°жҚ®еҹҹзҡ„з©әй—ҙ, дҪҶжҳҜе®һйҷ…дҪҝз”ЁиҝҮзЁӢдёӯ, еҫҖеҫҖеңЁеҮҪж•°дёӯејҖиҫҹз©әй—ҙ, 然еҗҺиҝ”еӣһз»ҷдҪҝз”ЁиҖ…жҢҮеҗ‘ struct point_buffer зҡ„жҢҮй’Ҳ, иҝҷж—¶еҖҷжҲ‘们并дёҚиғҪеҒҮе®ҡдҪҝз”ЁиҖ…дәҶи§ЈжҲ‘们ејҖиҫҹзҡ„з»ҶиҠӮ, 并жҢүз…§зәҰе®ҡзҡ„ж“ҚдҪңйҮҠж”ҫз©әй—ҙ, еӣ жӯӨдҪҝз”Ёиө·жқҘеӨҡжңүдёҚдҫҝ, з”ҡиҮійҖ жҲҗеҶ…еӯҳжі„жјҸгҖӮ
4гҖҒеҸҳй•ҝж•°жҚ®зј“еҶІеҢә(ејҖиҫҹз©әй—ҙ, йҮҠж”ҫ, и®ҝй—®)
е®ҡй•ҝж•°з»„дҪҝз”Ёж–№дҫҝ, дҪҶжҳҜеҚҙжөӘиҙ№з©әй—ҙ, жҢҮй’ҲеҪўејҸеҸӘеӨҡдҪҝз”ЁдәҶдёҖдёӘжҢҮй’Ҳзҡ„з©әй—ҙ, дёҚдјҡйҖ жҲҗеӨ§йҮҸз©әй—ҙеҲҶжөӘиҙ№, дҪҶжҳҜдҪҝз”Ёиө·жқҘйңҖиҰҒеӨҡж¬ЎеҲҶй…Қ, еӨҡж¬ЎйҮҠж”ҫ, йӮЈд№ҲжңүжІЎжңүдёҖз§Қе®һзҺ°ж–№ејҸиғҪеӨҹж—ўдёҚжөӘиҙ№з©әй—ҙ, еҸҲдҪҝз”Ёж–№дҫҝзҡ„е‘ў?
GNU C зҡ„0й•ҝеәҰж•°з»„, д№ҹеҸ«еҸҳй•ҝж•°з»„, жҹ”жҖ§ж•°з»„е°ұжҳҜиҝҷж ·дёҖдёӘжү©еұ•. еҜ№дәҺ0й•ҝж•°з»„зҡ„иҝҷдёӘзү№зӮ№пјҢеҫҲе®№жҳ“жһ„йҖ еҮәеҸҳжҲҗз»“жһ„дҪ“пјҢеҰӮзј“еҶІеҢәпјҢж•°жҚ®еҢ…зӯүзӯүпјҡ
ж•°жҚ®з»“жһ„е®ҡд№үпјҡ
// 0й•ҝеәҰж•°з»„
struct zero_buffer
{
int len;
char data[0];
};ж•°жҚ®з»“жһ„еӨ§е°Ҹпјҡиҝҷж ·зҡ„еҸҳй•ҝж•°з»„еёёз”ЁдәҺзҪ‘з»ңйҖҡдҝЎдёӯжһ„йҖ дёҚе®ҡй•ҝж•°жҚ®еҢ…, дёҚдјҡжөӘиҙ№з©әй—ҙжөӘиҙ№зҪ‘з»ңжөҒйҮҸ, еӣ дёәchar data[0]; еҸӘжҳҜдёӘж•°з»„еҗҚ, жҳҜдёҚеҚ з”ЁеӯҳеӮЁз©әй—ҙзҡ„пјҡ
sizeof(struct zero_buffer) = sizeof(int)
ејҖиҫҹз©әй—ҙпјҡйӮЈд№ҲжҲ‘们дҪҝз”Ёзҡ„ж—¶еҖҷ, еҸӘйңҖиҰҒејҖиҫҹдёҖж¬Ўз©әй—ҙеҚіеҸҜ
/// ејҖиҫҹ
if ((zbuffer = (struct zero_buffer *)malloc(sizeof(struct zero_buffer) + sizeof(char) * CURR_LENGTH)) != NULL)
{
zbuffer->len = CURR_LENGTH;
memcpy(zbuffer->data, "Hello World", CURR_LENGTH);
printf("%d, %s\n", zbuffer->len, zbuffer->data);
}йҮҠж”ҫз©әй—ҙпјҡйҮҠж”ҫз©әй—ҙд№ҹжҳҜдёҖж ·зҡ„, дёҖж¬ЎйҮҠж”ҫеҚіеҸҜ
/// й”ҖжҜҒ
free(zbuffer);
zbuffer = NULL;
жҖ»з»“пјҡ
// zero_length_array.c
#include <stdio.h>
#include <stdlib.h>
#define MAX_LENGTH 1024
#define CURR_LENGTH 512
// 0й•ҝеәҰж•°з»„
struct zero_buffer
{
int len;
char data[0];
}__attribute((packed));
// е®ҡй•ҝж•°з»„
struct max_buffer
{
int len;
char data[MAX_LENGTH];
}__attribute((packed));
// жҢҮй’Ҳж•°з»„
struct point_buffer
{
int len;
char *data;
}__attribute((packed));
int main(void)
{
struct zero_buffer *zbuffer = NULL;
struct max_buffer *mbuffer = NULL;
struct point_buffer *pbuffer = NULL;
// =====================
// 0й•ҝеәҰж•°з»„ еҚ з”Ё-ејҖиҫҹ-й”ҖжҜҒ
// =====================
/// еҚ з”Ё
printf("the length of struct test1:%d\n",sizeof(struct zero_buffer));
/// ејҖиҫҹ
if ((zbuffer = (struct zero_buffer *)malloc(sizeof(struct zero_buffer) + sizeof(char) * CURR_LENGTH)) != NULL)
{
zbuffer->len = CURR_LENGTH;
memcpy(zbuffer->data, "Hello World", CURR_LENGTH);
printf("%d, %s\n", zbuffer->len, zbuffer->data);
}
/// й”ҖжҜҒ
free(zbuffer);
zbuffer = NULL;
// =====================
// е®ҡй•ҝж•°з»„ еҚ з”Ё-ејҖиҫҹ-й”ҖжҜҒ
// =====================
/// еҚ з”Ё
printf("the length of struct test2:%d\n",sizeof(struct max_buffer));
/// ејҖиҫҹ
if ((mbuffer = (struct max_buffer *)malloc(sizeof(struct max_buffer))) != NULL)
{
mbuffer->len = CURR_LENGTH;
memcpy(mbuffer->data, "Hello World", CURR_LENGTH);
printf("%d, %s\n", mbuffer->len, mbuffer->data);
}
/// й”ҖжҜҒ
free(mbuffer);
mbuffer = NULL;
// =====================
// жҢҮй’Ҳж•°з»„ еҚ з”Ё-ејҖиҫҹ-й”ҖжҜҒ
// =====================
/// еҚ з”Ё
printf("the length of struct test3:%d\n",sizeof(struct point_buffer));
/// ејҖиҫҹ
if ((pbuffer = (struct point_buffer *)malloc(sizeof(struct point_buffer))) != NULL)
{
pbuffer->len = CURR_LENGTH;
if ((pbuffer->data = (char *)malloc(sizeof(char) * CURR_LENGTH)) != NULL)
{
memcpy(pbuffer->data, "Hello World", CURR_LENGTH);
printf("%d, %s\n", pbuffer->len, pbuffer->data);
}
}
/// й”ҖжҜҒ
free(pbuffer->data);
free(pbuffer);
pbuffer = NULL;
return EXIT_SUCCESS;
}GNU Documentдёӯ еҸҳй•ҝж•°з»„зҡ„ж”ҜжҢҒ
еҸӮиҖғпјҡ
6.17 Arrays of Length Zero
C Struct Hack – Structure with variable length array
еңЁ C90 д№ӢеүҚ, 并дёҚж”ҜжҢҒ0й•ҝеәҰзҡ„ж•°з»„, 0й•ҝеәҰж•°з»„жҳҜ GNU C зҡ„дёҖдёӘжү©еұ•, еӣ жӯӨж—©жңҹзҡ„зј–иҜ‘еҷЁдёӯжҳҜж— жі•йҖҡиҝҮзј–иҜ‘зҡ„пјӣеҜ№дәҺ GNU C еўһеҠ зҡ„жү©еұ•, GCC жҸҗдҫӣдәҶзј–иҜ‘йҖүйЎ№жқҘжҳҺзЎ®зҡ„ж ҮиҜҶеҮә他们:
-pedantic йҖүйЎ№пјҢйӮЈд№ҲдҪҝз”ЁдәҶжү©еұ•иҜӯжі•зҡ„ең°ж–№е°Ҷдә§з”ҹзӣёеә”зҡ„иӯҰе‘ҠдҝЎжҒҜ
-Wall дҪҝз”Ёе®ғиғҪеӨҹдҪҝGCCдә§з”ҹе°ҪеҸҜиғҪеӨҡзҡ„иӯҰе‘ҠдҝЎжҒҜ
-Werror, е®ғиҰҒжұӮGCCе°ҶжүҖжңүзҡ„иӯҰе‘ҠеҪ“жҲҗй”ҷиҜҜиҝӣиЎҢеӨ„зҗҶ
// 1.c
#include <stdio.h>
#include <stdlib.h>
int main(void)
{
char a[0];
printf("%ld", sizeof(a));
return EXIT_SUCCESS;
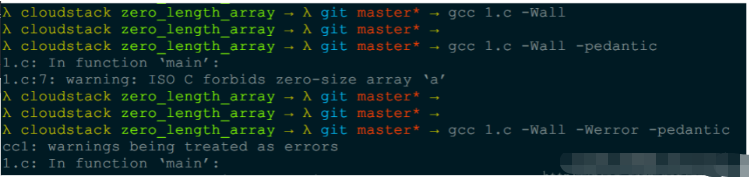
}жҲ‘们жқҘзј–иҜ‘пјҡ
gcc 1.c -Wall # жҳҫзӨәжүҖжңүиӯҰе‘Ҡ
#none warning and error
gcc 1.c -Wall -pedantic # еҜ№GNU Cзҡ„жү©еұ•жҳҫзӨәиӯҰе‘Ҡ
1.c: In function ‘main’:
1.c:7: warning: ISO C forbids zero-size array ‘a’
gcc 1.c -Werror -Wall -pedantic # жҳҫзӨәжүҖжңүиӯҰе‘ҠеҗҢж—¶GNU Cзҡ„жү©еұ•жҳҫзӨәиӯҰе‘Ҡ, е°ҶиӯҰе‘Ҡз”ЁerrorжҳҫзӨә
cc1: warnings being treated as errors
1.c: In function ‘main’:
1.c:7: error: ISO C forbids zero-size array ‘a’
0й•ҝеәҰж•°з»„е…¶е®һе°ұжҳҜзҒөжҙ»зҡ„иҝҗз”Ёзҡ„ж•°з»„жҢҮеҗ‘зҡ„жҳҜе…¶еҗҺйқўзҡ„иҝһз»ӯзҡ„еҶ…еӯҳз©әй—ҙпјҡ
struct buffer
{
int len;
char data[0];
};еңЁж—©жңҹжІЎеј•е…Ҙ0й•ҝеәҰж•°з»„зҡ„ж—¶еҖҷ, еӨ§е®¶жҳҜйҖҡиҝҮе®ҡй•ҝж•°з»„е’ҢжҢҮй’Ҳзҡ„ж–№ејҸжқҘи§ЈеҶізҡ„, дҪҶжҳҜпјҡ
е®ҡй•ҝж•°з»„е®ҡд№үдәҶдёҖдёӘи¶іеӨҹеӨ§зҡ„зј“еҶІеҢә, иҝҷж ·дҪҝз”Ёж–№дҫҝ, дҪҶжҳҜжҜҸж¬ЎйғҪйҖ жҲҗз©әй—ҙзҡ„жөӘиҙ№
жҢҮй’Ҳзҡ„ж–№ејҸ, иҰҒжұӮзЁӢеәҸе‘ҳеңЁйҮҠж”ҫз©әй—ҙжҳҜеҝ…йЎ»иҝӣиЎҢеӨҡж¬Ўзҡ„freeж“ҚдҪң, иҖҢжҲ‘们еңЁдҪҝз”Ёзҡ„иҝҮзЁӢдёӯеҫҖеҫҖеңЁеҮҪж•°дёӯиҝ”еӣһдәҶжҢҮеҗ‘зј“еҶІеҢәзҡ„жҢҮй’Ҳ, жҲ‘们并дёҚиғҪдҝқиҜҒжҜҸдёӘдәәйғҪзҗҶ解并йҒөд»ҺжҲ‘们зҡ„йҮҠж”ҫж–№ејҸ
жүҖд»Ҙ GNU е°ұеҜ№е…¶иҝӣиЎҢдәҶ0й•ҝеәҰж•°з»„зҡ„жү©еұ•. еҪ“дҪҝз”Ёdata[0]зҡ„ж—¶еҖҷ, д№ҹе°ұжҳҜ0й•ҝеәҰж•°з»„зҡ„ж—¶еҖҷпјҢ0й•ҝеәҰж•°з»„дҪңдёәж•°з»„еҗҚ, 并дёҚеҚ з”ЁеӯҳеӮЁз©әй—ҙ.
еңЁC99д№ӢеҗҺпјҢд№ҹеҠ дәҶзұ»дјјзҡ„жү©еұ•пјҢеҸӘдёҚиҝҮз”Ёзҡ„жҳҜ char payload[]иҝҷз§ҚеҪўејҸпјҲжүҖд»ҘеҰӮжһңдҪ еңЁзј–иҜ‘зҡ„ж—¶еҖҷзЎ®е®һйңҖиҰҒз”ЁеҲ°-pedanticеҸӮж•°пјҢйӮЈд№ҲдҪ еҸҜд»Ҙе°Ҷchar payload[0]зұ»еһӢж”№жҲҗchar payload[], иҝҷж ·е°ұеҸҜд»Ҙзј–иҜ‘йҖҡиҝҮдәҶпјҢеҪ“然дҪ зҡ„зј–иҜ‘еҷЁеҝ…йЎ»ж”ҜжҢҒC99ж ҮеҮҶзҡ„пјҢеҰӮжһңеӨӘеҸӨиҖҒзҡ„зј–иҜ‘еҷЁпјҢйӮЈеҸҜиғҪдёҚж”ҜжҢҒдәҶ)
// 2.c payload
#include <stdio.h>
#include <stdlib.h>
struct payload
{
int len;
char data[];
};
int main(void)
{
struct payload pay;
printf("%ld", sizeof(pay));
return EXIT_SUCCESS;
}дҪҝз”Ё -pedantic зј–иҜ‘еҗҺ, дёҚеҮәзҺ°иӯҰе‘Ҡ, иҜҙжҳҺиҝҷз§ҚиҜӯжі•жҳҜ C ж ҮеҮҶзҡ„
gcc 2.c -pedantic -std=c99

жүҖд»Ҙз»“жһ„дҪ“зҡ„жң«е°ҫ, е°ұжҳҜжҢҮеҗ‘дәҶе…¶еҗҺйқўзҡ„еҶ…еӯҳж•°жҚ®гҖӮеӣ жӯӨжҲ‘们еҸҜд»ҘеҫҲеҘҪзҡ„е°ҶиҜҘзұ»еһӢзҡ„з»“жһ„дҪ“дҪңдёәж•°жҚ®жҠҘж–Үзҡ„еӨҙж јејҸпјҢ并且жңҖеҗҺдёҖдёӘжҲҗе‘ҳеҸҳйҮҸпјҢд№ҹе°ұеҲҡеҘҪжҳҜж•°жҚ®еҶ…е®№дәҶ.
GNUжүӢеҶҢиҝҳжҸҗдҫӣдәҶеҸҰеӨ–дёӨдёӘз»“жһ„дҪ“жқҘиҜҙжҳҺпјҢжӣҙе®№жҳ“зңӢжҮӮж„ҸжҖқпјҡ
struct f1 {
int x;
int y[];
} f1 = { 1, { 2, 3, 4 } };
struct f2 {
struct f1 f1;
int data[3];
} f2 = { { 1 }, { 5, 6, 7 } };жҲ‘жҠҠf2йҮҢйқўзҡ„2,3,4ж”№жҲҗдәҶ5,6,7д»ҘзӨәеҢәеҲҶгҖӮеҰӮжһңдҪ жҠҠж•°жҚ®жү“еҮәжқҘгҖӮеҚіеҰӮдёӢзҡ„дҝЎжҒҜпјҡ
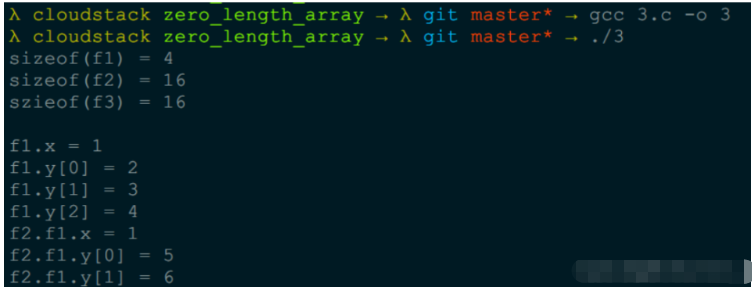
f1.x = 1
f1.y[0] = 2
f1.y[1] = 3
f1.y[2] = 4
д№ҹе°ұжҳҜf1.yжҢҮеҗ‘зҡ„жҳҜ{2,3,4}иҝҷеқ—еҶ…еӯҳдёӯзҡ„ж•°жҚ®гҖӮжүҖд»ҘжҲ‘们е°ұеҸҜд»ҘиҪ»жҳ“зҡ„еҫ—еҲ°пјҢf2.f1.yжҢҮеҗ‘зҡ„ж•°жҚ®д№ҹе°ұжҳҜжӯЈеҘҪf2.dataзҡ„еҶ…е®№дәҶгҖӮжү“еҚ°еҮәжқҘзҡ„ж•°жҚ®пјҡ
f2.f1.x = 1
f2.f1.y[0] = 5
f2.f1.y[1] = 6
f2.f1.y[2] = 7
еҰӮжһңдҪ дёҚжҳҜеҫҲзЎ®и®Өе…¶жҳҜеҗҰеҚ з”Ёз©әй—ҙ. дҪ еҸҜд»Ҙз”ЁsizeofжқҘи®Ўз®—дёҖдёӢгҖӮе°ұеҸҜд»ҘзҹҘйҒ“sizeof(struct f1)=4,д№ҹе°ұжҳҜint y[]е…¶е®һжҳҜдёҚеҚ з”Ёз©әй—ҙзҡ„гҖӮдҪҶжҳҜиҝҷдёӘ0й•ҝеәҰзҡ„ж•°з»„пјҢеҝ…йЎ»ж”ҫеңЁз»“жһ„дҪ“зҡ„жң«е°ҫгҖӮеҰӮжһңдҪ жІЎжңүжҠҠе®ғж”ҫеңЁжң«е°ҫзҡ„иҜқгҖӮзј–иҜ‘зҡ„ж—¶еҖҷпјҢдјҡжңүеҰӮдёӢзҡ„й”ҷиҜҜпјҡ
main.c:37:9: error: flexible array member not at end of struct
int y[];
^
еҲ°иҝҷиҫ№пјҢдҪ еҸҜиғҪдјҡжңүз–‘й—®пјҢеҰӮжһңе°Ҷstruct f1дёӯзҡ„int y[]жӣҝжҚўжҲҗint *yпјҢеҸҲдјҡжҳҜеҰӮдҪ•пјҹиҝҷе°ұж¶үеҸҠеҲ°ж•°з»„е’ҢжҢҮй’Ҳзҡ„й—®йўҳдәҶ. жңүж—¶еҖҷеҗ§пјҢиҝҷдёӨдёӘжҳҜдёҖж ·зҡ„пјҢжңүж—¶еҖҷеҸҲжңүеҢәеҲ«гҖӮ
йҰ–е…ҲиҰҒиҜҙжҳҺзҡ„жҳҜпјҢж”ҜжҢҒ0й•ҝеәҰж•°з»„зҡ„жү©еұ•пјҢйҮҚзӮ№еңЁж•°з»„пјҢд№ҹе°ұжҳҜдёҚиғҪз”Ёint *yжҢҮй’ҲжқҘжӣҝжҚўгҖӮsizeofзҡ„й•ҝеәҰе°ұдёҚдёҖж ·дәҶгҖӮжҠҠstruct f1ж”№жҲҗиҝҷж ·пјҡ
struct f3 {
int x;
int *y;
};еңЁ32/64дҪҚдёӢ, intеқҮжҳҜ4дёӘеӯ—иҠӮ, sizeof(struct f1)=4пјҢиҖҢsizeof(struct f3)=16
еӣ дёә int *y жҳҜжҢҮй’Ҳ, жҢҮй’ҲеңЁ64дҪҚдёӢ, жҳҜ64дҪҚзҡ„пјҢ sizeof(struct f3) = 16, еҰӮжһңеңЁ32дҪҚзҺҜеўғзҡ„иҜқ, sizeof(struct f3) еҲҷжҳҜ 8 дәҶ, sizeof(struct f1) дёҚеҸҳ. жүҖд»Ҙ int *y жҳҜдёҚиғҪжӣҝд»Ј int y[] зҡ„;
д»Јз ҒеҰӮдёӢ:
// 3.c
#include <stdio.h>
#include <stdlib.h>
struct f1 {
int x;
int y[];
} f1 = { 1, { 2, 3, 4 } };
struct f2 {
struct f1 f1;
int data[3];
} f2 = { { 1 }, { 5, 6, 7 } };
struct f3
{
int x;
int *y;
};
int main(void)
{
printf("sizeof(f1) = %d\n", sizeof(struct f1));
printf("sizeof(f2) = %d\n", sizeof(struct f2));
printf("szieof(f3) = %d\n\n", sizeof(struct f3));
printf("f1.x = %d\n", f1.x);
printf("f1.y[0] = %d\n", f1.y[0]);
printf("f1.y[1] = %d\n", f1.y[1]);
printf("f1.y[2] = %d\n", f1.y[2]);
printf("f2.f1.x = %d\n", f1.x);
printf("f2.f1.y[0] = %d\n", f2.f1.y[0]);
printf("f2.f1.y[1] = %d\n", f2.f1.y[1]);
printf("f2.f1.y[2] = %d\n", f2.f1.y[2]);
return EXIT_SUCCESS;
}
0й•ҝеәҰж•°з»„зҡ„е…¶д»–зү№еҫҒ
1гҖҒдёәд»Җд№Ҳ0й•ҝеәҰж•°з»„дёҚеҚ з”ЁеӯҳеӮЁз©әй—ҙ:
0й•ҝеәҰж•°з»„дёҺжҢҮй’Ҳе®һзҺ°жңүд»Җд№ҲеҢәеҲ«е‘ў, дёәд»Җд№Ҳ0й•ҝеәҰж•°з»„дёҚеҚ з”ЁеӯҳеӮЁз©әй—ҙе‘ў?
е…¶е®һжң¬иҙЁдёҠж¶үеҸҠеҲ°зҡ„жҳҜдёҖдёӘCиҜӯиЁҖйҮҢйқўзҡ„ж•°з»„е’ҢжҢҮй’Ҳзҡ„еҢәеҲ«й—®йўҳ. char a[1]йҮҢйқўзҡ„aе’Ңchar *bзҡ„bзӣёеҗҢеҗ—пјҹ
гҖҠ Programming Abstractions in CгҖӢпјҲRoberts, E. S.пјҢжңәжў°е·ҘдёҡеҮәзүҲзӨҫпјҢ2004.6пјү82йЎөйҮҢйқўиҜҙпјҡ
вҖңarr is defined to be identical to &arr[0]вҖқ.
д№ҹе°ұжҳҜиҜҙпјҢchar a[1]йҮҢйқўзҡ„aе®һйҷ…жҳҜдёҖдёӘеёёйҮҸпјҢзӯүдәҺ&a[0]гҖӮиҖҢchar *bжҳҜжңүдёҖдёӘе®һе®һеңЁеңЁзҡ„жҢҮй’ҲеҸҳйҮҸbеӯҳеңЁгҖӮжүҖд»ҘпјҢa=bжҳҜдёҚе…Ғи®ёзҡ„пјҢиҖҢb=aжҳҜе…Ғи®ёзҡ„гҖӮдёӨз§ҚеҸҳйҮҸйғҪж”ҜжҢҒдёӢж ҮејҸзҡ„и®ҝй—®пјҢйӮЈд№ҲеҜ№дәҺa[0]е’Ңb[0]жң¬иҙЁдёҠжҳҜеҗҰжңүеҢәеҲ«пјҹжҲ‘们еҸҜд»ҘйҖҡиҝҮдёҖдёӘдҫӢеӯҗжқҘиҜҙжҳҺгҖӮ
еҸӮи§ҒеҰӮдёӢдёӨдёӘзЁӢеәҸ gdb_zero_length_array.c е’Ң gdb_zero_length_array.cпјҡ
// gdb_zero_length_array.c
#include <stdio.h>
#include <stdlib.h>
struct str
{
int len;
char s[0];
};
struct foo
{
struct str *a;
};
int main(void)
{
struct foo f = { NULL };
printf("sizeof(struct str) = %d\n", sizeof(struct str));
printf("before f.a->s.\n");
if(f.a->s)
{
printf("before printf f.a->s.\n");
printf(f.a->s);
printf("before printf f.a->s.\n");
}
return EXIT_SUCCESS;
}
// gdb_pzero_length_array.c
#include <stdio.h>
#include <stdlib.h>
struct str
{
int len;
char *s;
};
struct foo
{
struct str *a;
};
int main(void)
{
struct foo f = { NULL };
printf("sizeof(struct str) = %d\n", sizeof(struct str));
printf("before f.a->s.\n");
if (f.a->s)
{
printf("before printf f.a->s.\n");
printf(f.a->s);
printf("before printf f.a->s.\n");
}
return EXIT_SUCCESS;
}
еҸҜд»ҘзңӢеҲ°иҝҷдёӨдёӘзЁӢеәҸиҷҪ然йғҪеӯҳеңЁи®ҝй—®ејӮеёё, дҪҶжҳҜж®өй”ҷиҜҜзҡ„дҪҚзҪ®еҚҙдёҚеҗҢ
жҲ‘们е°ҶдёӨдёӘзЁӢеәҸзј–иҜ‘жҲҗжұҮзј–, 然жҲ· diff жҹҘзңӢ他们зҡ„жұҮзј–д»Јз ҒжңүдҪ•дёҚеҗҢ
gcc -S gdb_zero_length_array.c -o gdb_test.s
gcc -S gdb_pzero_length_array.c -o gdb_ptest
diff gdb_test.s gdb_ptest.s
1c1
< .file "gdb_zero_length_array.c"
---
> .file "gdb_pzero_length_array.c"
23c23
< movl $4, %esi
---
> movl $16, %esi
30c30
< addq $4, %rax
---
> movq 8(%rax), %rax
36c36
< addq $4, %rax
---
> movq 8(%rax), %rax
# printf("sizeof(struct str) = %d\n", sizeof(struct str));
23c23
< movl $4, %esi #printf("sizeof(struct str) = %d\n", sizeof(struct str));
---
> movl $16, %esi #printf("sizeof(struct str) = %d\n", sizeof(struct str));
д»Һ64дҪҚзі»з»ҹдёӯ, жұҮзј–жҲ‘们зңӢеҮә, еҸҳй•ҝж•°з»„з»“жһ„зҡ„еӨ§е°Ҹдёә4, иҖҢжҢҮй’ҲеҪўејҸзҡ„з»“жһ„еӨ§е°Ҹдёә16пјҡ
f.a->s
30c30/36c36
< addq $4, %rax
---
> movq 8(%rax), %rax
еҸҜд»ҘзңӢеҲ°жңүпјҡ
еҜ№дәҺ char s[0] жқҘиҜҙ, жұҮзј–д»Јз Ғз”ЁдәҶ addq жҢҮд»Ө, addq $4, %rax
еҜ№дәҺ char*s жқҘиҜҙпјҢжұҮзј–д»Јз Ғз”ЁдәҶ movq жҢҮд»Ө, movq 8(%rax), %rax
addq еҜ№ %rax + sizeof(struct str), еҚіstrз»“жһ„зҡ„жң«е°ҫеҚіжҳҜchar s[0]зҡ„ең°еқҖ, иҝҷдёҖжӯҘеҸӘжҳҜжӢҝеҲ°дәҶе…¶ең°еқҖ, иҖҢ movq еҲҷжҳҜжҠҠең°еқҖйҮҢзҡ„еҶ…е®№ж”ҫиҝӣеҺ», еӣ жӯӨжңүж—¶д№ҹиў«зҝ»иҜ‘дёәleapжҢҮд»Ө, еҸӮи§ҒдёӢдёҖеҲ—еӯҗ
д»ҺиҝҷйҮҢеҸҜд»ҘзңӢеҲ°, и®ҝй—®жҲҗе‘ҳж•°з»„еҗҚе…¶е®һеҫ—еҲ°зҡ„жҳҜж•°з»„зҡ„зӣёеҜ№ең°еқҖ, иҖҢи®ҝй—®жҲҗе‘ҳжҢҮй’Ҳе…¶е®һжҳҜзӣёеҜ№ең°еқҖйҮҢзҡ„еҶ…е®№(иҝҷе’Ңи®ҝй—®е…¶е®ғйқһжҢҮй’ҲжҲ–ж•°з»„зҡ„еҸҳйҮҸжҳҜдёҖж ·зҡ„)пјҡ
и®ҝй—®зӣёеҜ№ең°еқҖпјҢзЁӢеәҸдёҚдјҡcrashпјҢдҪҶжҳҜпјҢи®ҝй—®дёҖдёӘйқһжі•зҡ„ең°еқҖдёӯзҡ„еҶ…е®№пјҢзЁӢеәҸе°ұдјҡcrashгҖӮ
// 4-1.c
#include <stdio.h>
#include <stdlib.h>
int main(void)
{
char *a;
printf("%p\n", a);
return EXIT_SUCCESS;
}//4-2.c
#include <stdio.h>
#include <stdlib.h>
int main(void)
{
char a[0];
printf("%p\n", a);
return EXIT_SUCCESS;
}еҜ№дәҺ char a[0] жқҘиҜҙ, жұҮзј–д»Јз Ғз”ЁдәҶ leal жҢҮд»Ө, leal 16(%esp), %eaxпјҡ
еҜ№дәҺ char *a жқҘиҜҙпјҢжұҮзј–д»Јз Ғз”ЁдәҶ movl жҢҮд»Ө, movl 28(%esp), %eax
2гҖҒең°еқҖдјҳеҢ–:
// 5-1.c
#include <stdio.h>
#include <stdlib.h>
int main(void)
{
char a[0];
printf("%p\n", a);
char b[0];
printf("%p\n", b);
return EXIT_SUCCESS;
}
з”ұдәҺ0й•ҝеәҰж•°з»„жҳҜ GNU C зҡ„жү©еұ•, дёҚиў«ж ҮеҮҶеә“д»»еҸҜ, йӮЈд№ҲдёҖдәӣе·§еҰҷзј–еҶҷзҡ„иҜЎејӮд»Јз Ғ, е…¶жү§иЎҢз»“жһңе°ұжҳҜдҫқиө–дәҺзј–иҜ‘еҷЁе’ҢдјҳеҢ–зӯ–з•Ҙзҡ„е®һзҺ°зҡ„.
жҜ”еҰӮдёҠйқўзҡ„д»Јз Ғ, aе’Ңbзҡ„ең°еқҖе°ұдјҡиў«зј–иҜ‘еҷЁдјҳеҢ–еҲ°дёҖеӨ„, еӣ дёәa[0] е’Ң b[0] еҜ№дәҺзЁӢеәҸжқҘиҜҙжҳҜж— жі•дҪҝз”Ёзҡ„, иҝҷи®©жҲ‘们жғіеҲ°дәҶд»Җд№Ҳ?
зј–иҜ‘еҷЁеҜ№дәҺзӣёеҗҢеӯ—з¬ҰдёІеёёйҮҸ, еҫҖеҫҖең°еқҖд№ҹжҳҜдјҳеҢ–еҲ°дёҖеӨ„, еҮҸе°‘з©әй—ҙеҚ з”Ёпјҡ
// 5-2.c
#include <stdio.h>
#include <stdlib.h>
int main(void)
{
const char *a = "Hello";
printf("%p\n", a);
const char *b = "Hello";
printf("%p\n", b);
const char c[] = "Hello";
printf("%p\n", c);
return EXIT_SUCCESS;
}
вҖңCиҜӯиЁҖдёӯзҡ„0й•ҝеәҰж•°з»„жңүд»Җд№Ҳз”ЁйҖ”вҖқзҡ„еҶ…е®№е°ұд»Ӣз»ҚеҲ°иҝҷйҮҢдәҶпјҢж„ҹи°ўеӨ§е®¶зҡ„йҳ…иҜ»гҖӮеҰӮжһңжғідәҶи§ЈжӣҙеӨҡиЎҢдёҡзӣёе…ізҡ„зҹҘиҜҶеҸҜд»Ҙе…іжіЁдәҝйҖҹдә‘зҪ‘з«ҷпјҢе°Ҹзј–е°ҶдёәеӨ§е®¶иҫ“еҮәжӣҙеӨҡй«ҳиҙЁйҮҸзҡ„е®һз”Ёж–Үз« пјҒ





