这篇文章主要讲解了“python爬虫实例代码分析”,文中的讲解内容简单清晰,易于学习与理解,下面请大家跟着小编的思路慢慢深入,一起来研究和学习“python爬虫实例代码分析”吧!
虎扑体育-NBA球员得分数据排行 第1页
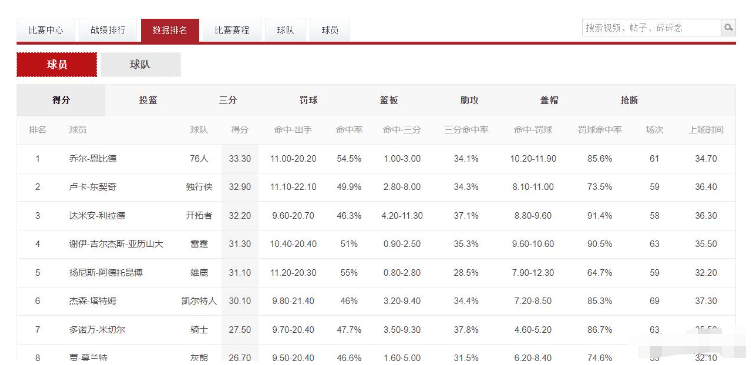
示例代码:
import requests
from lxml import etree
url = 'https://nba.hupu.com/stats/players'
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36"
}
res = requests.get(url=url, headers=headers)
print(res)
# 处理请求结果
e = etree.HTML(res.text)
# 解析响应的数据
player = e.xpath('//*[@id="data_js"]/div[4]/div/table/tbody/tr/td[2]/a/text()')
team = e.xpath('//*[@id="data_js"]/div[4]/div/table/tbody/tr/td[3]/a/text()')
hit_rate = e.xpath('//*[@id="data_js"]/div[4]/div/table/tbody/tr/td[6]/text()')[1:]
score = e.xpath('//*[@id="data_js"]/div[4]/div/table/tbody/tr/td[4]/text()')[1:]
for p, t, h, s in zip(player, team, hit_rate, score):
print(f"队员:{p},球队:{t},命中率:{h},得分:{s}")运行结果:
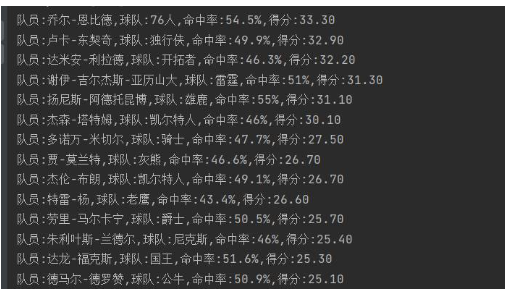
感谢各位的阅读,以上就是“python爬虫实例代码分析”的内容了,经过本文的学习后,相信大家对python爬虫实例代码分析这一问题有了更深刻的体会,具体使用情况还需要大家实践验证。这里是亿速云,小编将为大家推送更多相关知识点的文章,欢迎关注!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





