1http简单介绍
http超文本传输协议:host主机地址:port端口/url
host会被DNS服务器 解析成IP地址,所以有时候可以直接用域名,
http默认访问80端口,https默认访问443端口
大致流程就是:浏览器输入地址后,首先和web服务器建立tcp连接,
然后浏览器发送http请求报文, web服务器响应处理这个报文,
然后给他回复一个响应,然后服务器主动断开连接。
2http请求报文格式
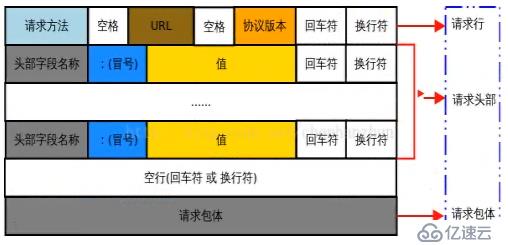
首先第一个就是请求的方法,方法有一下这些:
GET,POST,HEAD,PUT,DELETE,OPTIONS,TRACE,CONNECT;
1GET
在浏览器输入的网址,浏览器就会发送GET的http报文请求。
如果不写url 默认就是 "/" 服务器 可根据这个响应对应的页面.
头部信息就包含一些重要的请求信息,如主机地址.
浏览器版本 , 手机的页面就是根据这个去做的.
GET 携带参数是在url里面的, POST是携带在包体里面的.
包体成为body,请求头部叫做head。
GET传递参数,格式 /url?username=xxx&passwd=bbb 通过问号解析参数部分
url的传递参数是有限制的,每个浏览器限制都不一样。url不允许有回车换行
2POST
POST也是一个请求操作,他的数据参数携带在http请求的body里面。
所有的参数都不允许有回车换行的存在, 很多时候如果必须要携带
回车换行的话,必须先把数据转换成base64编码,因为它没有回车换成.他是解决网络传输的常用方法。
3http响应报文格式

1状态码:请求是否成功,状态码描述:成功或失败的原因
有时候访问一网页 会出现404,这个404就是这个状态码.
4http数据传输模式
1传输中两个重要的参数: 写在头里面
transfer-encoding:identity,chunked表示当前这个body是什么协议发过来的
content-length:length:数据包的长度
2identity 直接发送模式,length在后面表示数据长度
3chunked 模式,后面跟的是每一个chunk包 [包头,包数据]
包头:第一个字节表示一个ASSIC数据,第二个字节也是ASSIC数据
两个字节加起来,组成一个16进制数据。
后面两个字节,固定的0d0a(回车换行符)两个字节这4个字节就是一个chunk的包头,
后面的数据包 根据前面的两个字节来决定。数据包的结束标志是
30 0d 0a 30ascll码代表的是0
也就是说chunk包的结束:是遇到一个为等于0的chunk结束。
然后把这个包整合一下,形成完整的数据。
5http状态码和表
/*
{
[100] = "Continue",
[101] = "Switching Protocols",
[200] = "OK",
[201] = "Created",
[202] = "Accepted",
[203] = "Non-Authoritative Information",
[204] = "No Content",
[205] = "Reset Content",
[206] = "Partial Content",
[300] = "Multiple Choices",
[301] = "Moved Permanently",
[302] = "Found",
[303] = "See Other",
[304] = "Not Modified",
[305] = "Use Proxy",
[307] = "Temporary Redirect",
[400] = "Bad Request",
[401] = "Unauthorized",
[402] = "Payment Required",
[403] = "Forbidden",
[404] = "Not Found",
[405] = "Method Not Allowed",
[406] = "Not Acceptable",
[407] = "Proxy Authentication Required",
[408] = "Request Time-out",
[409] = "Conflict",
[410] = "Gone",
[411] = "Length Required",
[412] = "Precondition Failed",
[413] = "Request Entity Too Large",
[414] = "Request-URI Too Large",
[415] = "Unsupported Media Type",
[416] = "Requested range not satisfiable",
[417] = "Expectation Failed",
[500] = "Internal Server Error",
[501] = "Not Implemented",
[502] = "Bad Gateway",
[503] = "Service Unavailable",
[504] = "Gateway Time-out",
[505] = "HTTP Version not supported",
}
*/
6使用http_parmer解析 URL读取 然后返回给客户端
//解析我们的http报文
http_parser p;
http_parser_init(&p,HTTP_REQUEST);
http_parser_settings s;
http_parser_settings_init(&s);
//解析到了url 回调
s.on_url = ws_on_url;
//重置解析信息
init_ws_params();
// 解析器执行。返回解析的字节数
http_parser_execute(&p,&s,http_req,len);
//设置回调函数
switch (p.method) //报文响应的方式
{
case HTTP_GET:
{
int len_URL = filter_url(WS_HTTP.url);
//访问的网页
if (strncmp("/", WS_HTTP.url, len_URL) == 0){ //访问test这个html
strncpy(WS_HTTP.url, "www_root/index.html", strlen("www_root/index.html"));
}
else if (strncmp("/test", WS_HTTP.url, len_URL) == 0){ //访问默认的url 根目录
strncpy(WS_HTTP.url, "www_root/test.html", strlen("www_root/test.html"));
}
char* file_data = open_files(WS_HTTP.url);
//发送报文 也就是响应客户端
//释放内存
free(file_data);
}
break;
case HTTP_POST:
break;
}
//end
printf("\n");
读取文件
static char*
open_files(char* filename)
{
//读取这个文件
FILE* f = fopen(filename,"rb");
//文件大小
int file_size = 0;
fseek(f,0,SEEK_END);
file_size = ftell(f);
//指针又到文件头
fseek(f, 0, 0);
char* file_data = malloc(file_size + 1);
fread(file_data, file_size,1, f);
file_data[file_size] = 0;
fclose(f);
return file_data;
}7响应请求报文
//使用identity来发送响应报文
static void
write_ok_identity(int sock, char* body)
{
int len = strlen(body);
//使用直接模式 transfer-encoding:identity
char* send_line = malloc(len + 8096);
memset(send_line, 0, sizeof(send_line));
//回应http的头
sprintf(send_line, "HTTP/1.1 %d %s\r\n", 200, "OK");
//设置头部的一些信息 比如传送模式 body的长度
char* walk = send_line;
//跳过这个头部
walk = walk + strlen(walk);
sprintf(walk,"transfer-encoding:%s\r\n","identity");
//body的长度
walk = walk + strlen(walk); //头结束
sprintf(walk, "content-length: %d\r\n\r\n0", len);
//写入数据部分
walk = walk + strlen(walk);
sprintf(walk, "%s", body);
//发送报文 响应 给客户端
send(sock, send_line, strlen(send_line), 0);
free(send_line);
walk = NULL;
}免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





