Flume和Sqoop是Hadoop数据集成和收集系统,两者的定位不一样,下面根据个人的经验与理解和大家做一个介绍:
Flume由cloudera开发出来,有两大产品:Flume-og和Flume-ng,Flume-og的架构过于复杂,在寻问当中会有数据丢失,所以放弃了。现在我们使用的是Flume-ng,主要是日志采集,这个日志可以是TCP的系统的日志数据,可以是文件数据(就是通常我们在Intel服务器,通过其中的机构传过来的接口,或者通过防火墙采集过来的日志),在HDFS上去存储,可以和kafka进行集成,这就是Flume的功能。
Flume架构是分布式,可以根据需要进行扩展Flume的节点和数量。它的扩展有两个含义:一个是横向的,根据原数据源的个数、种类不同进行扩展;第二个就是纵向的,可以增加更多的汇聚层,去做更多的过程的数据处理,而不是数据加载进来之后再进行转换。
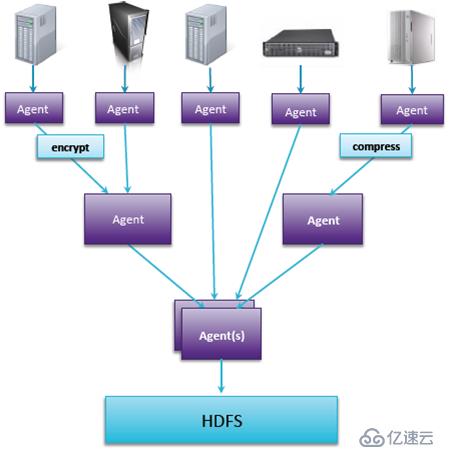
Flume的性能高可靠并且高可用的,可靠性主要体现在两个方面:一方面就是有一份数据比较重要,为了保证数据传输的可靠性,可以两个agent指向这份数据,而且两个agent可以进行示范切换,如果其中一个失败,另一个还可以进行传输。另一方面就是在agent的内部可以做缓存通透区,接收到数据可以存到磁盘,放到数据库,纵使agent出问题,数据依然存在。
Flume是做日志采集的,但是更多的数据是从结构化数据库过来的,这时我们就需要Sqoop。Sqoop是关系型数据库和HDFS之间的一个桥梁,可以实现数据在关系型数据库与HDFS之间的一个传送。那么我们什么时候将数据传递到HDFS呢?主要是把新增交易,新增账户加载过来,写的时候除了hdfs,还可以写hive,甚至可以直接去建表。而且可以在源数据库设立是导整个数据库,还是导某一个表,或者导特定的列,这都是常见的在数据仓库中进行的ETL.
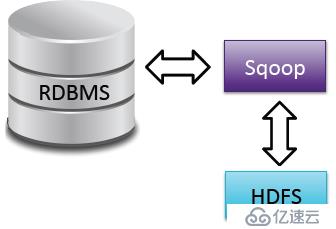
sqoop允许增量导入,增量有两种,一种是直接追加(比如新增订单、交易可以追加);另一种是状态的改变,比如一个客户之前是白名单客户,还款很好,但是如果某个月逾期,加入黑名单,后期还款了又回到白名单,状态在不停改变,那么就不能再和交易等一样做追加,这个时候需要做的就是拉链。需要一个修改的日期,那么这个状态有没有修改,如果修改了,那么之前加载的怎么办?可以通过sqoop进行配置,加载的时候让它们在Hadoop里面进行更新。我们知道HDFS文件不能更新,这个时候进行文件合并,通过合并的方式把文本的数据清除。
数据什么时候导出呢?导出数据就在于Hadoop里面分析好的数据,我们可能需要下载一个数据集市,基于这个集市把数据导出来,所以sqoop也可以把数据导出。sqoop导出的机制是:默认的是mysql,mysql 效率较低,那么选择第二种方式---直接模式,利用数据库本身提供的一些导出工具。但是这些导出工具的效率还不够高,更高的就是专业的定制的连接器,目前定制的连接器有MySQL、Postgres、Netezza、Teradata、Oracle。
以上就是根据自己的一些学习和工作经验总结的关于Flume和Sqoop的相关知识,有些具体的知识这里没有多涉及,如果想了解的可以自己去学习。我自己平常也会去关注“大数据cn”和“大数据时代学习中心”这些微信公众号,里面分享的一些资讯和知识点对我有很大的帮助,推荐大家去看看,期望共同进步!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



