这篇文章主要讲解了“如何提高大数据量分页的效率”,文中的讲解内容简单清晰,易于学习与理解,下面请大家跟着小编的思路慢慢深入,一起来研究和学习“如何提高大数据量分页的效率”吧!
如我们在之前的教程里讨论的那样,分页可以通过两种方法来实现:
默认分页– 你仅仅只用选中data Web control的 智能标签的Enable Paging ; 然而,当你浏览页面的时候,虽然你看到的只是一小部分数据,ObjectDataSource 还是会每次都读取所有数据
自定义分页– 通过只从数据库读取用户需要浏览的那部分数据,提高了性能. 显然这种方法需要你做更多的工作.
默认的分页功能非常吸引人,因为你只需要选中一个checkbox就可以完成了.但是它每次都读取所有的数据,这种方式在大数据量或者并发用户多的情况下就不合适.在这样的情况下,我们必须通过自定义分页来使系统达到更好的性能.
自定义分页的一个重点是要写一个返回仅仅需要的数据的查询语句.幸运的,Microsoft SQL Server 2005 提供了一个新的keyword,通过它我们可以写出读取需要的数据的查询.在本教程里,我们将学习在GridView里如何使用Microsoft SQL Server 2005 的这个新的keyword来实现自定义分页.自定义分页和默认分页的界面看起来一样,但是当你从一页转到另一页时,在效率上差了几个数量级.
注意:自定义分页带来的性能提升程序取决于数据的总量和数据库的负载.在本教程的最后我们会用数据来说明自定义分页带来的性能方面的好处.
给数据分页的时候,页面显示的数据取决于请求的是哪一页和每页显示多少条.比如,想象以下我们给81个product分页,每页显示10条.当我们浏览第一页时,我们需要的是product 1 到 product 10.当浏览第二页时,我们需要的是product 11 到 product 20,以次类推.
对于需要读取什么数据和分页的页面怎么显示,有三个相关的变量:
Start Row Index – 页面里显示数据的第一行的索引; 这个值可以通过页的索引乘每页显示的记录的条数加1得到. 例如, 如果一页显示10条数据, 那么对第一页来说(第一页的索引为0), 第一行的索引为0 * 10 + 1, or 1; 对第二页来说(索引为1), 第一行的索引为1 * 10 + 1, 即 11.
Maximum Rows – 每页显示的最多记录的条数. 之所以称为“maximum” rows 是由于最后一页显示的数据可能会比page size要小. 比如, 当以每页10条记录来显示81条时, 最后一页也就是第九页只包含一条记录. 没有页面显示的记录条数会大于Maximum Rows 的值.
Total Record Count – 显示数据的总条数. 不需要知道页面显示什么数据,但是记录总数会影响到分页. 比如, 如果对81条product记录分页,每页10条,那么总页数为9.
对默认分页来说,Start Row Index是由页索引和每页的记录数加1得到,Maximum Rows 就是每页的记录数.使用默认分页时,不管是呈现哪页的数据,都是要读取全部的数据,所有每行的索引都是已知的,这样获取Start Row Index变的没有价值.而且,记录的总条数是可以通过DataTable的总条数来获取的.
自定义分页只返回从Start Row Index 开始的Maximum Rows条记录.在这里有两个要注意的地方:
我们必须把整个要分页的数据和一个row index关联起来,这样才能从指定的Start Row Index 开始返回需要的数据.
我们需要提供用来分页的数据的总条数.
在后面的两步里我们将写出和上面两点相关的SQL.除此之外,我们还将在DAL和BLL里完成相应的方法.
在我们学习如何返回显示页面需要的数据之前,我们先来看看怎么获取数据的总条数.因为在配置界面的时候需要用到这个信息.我们使用SQL的COUNT aggregate function来实现这个.比如,返回Products表的总记录条数,我们可以用如下的语句:
| SQL | |
1 2 | SELECT COUNT(*)
FROM Products |
我们在DAL里添加一个方法来返回这个信息.这个方法名为TotalNumberOfProducts() ,它会执行上面的SQL语句.
打开App_Code/DAL 文件夹里的 Northwind.xsd .然后在设计器里右键点ProductsTableAdapter ,选择Add Query.和我们在以前的教程里学习的那样,这样会允许我们添加一个新的DAL方法,这个方法被调用时会执行指定的SQL或存储过程.和前面的 TableAdapter 方法一样,为这个添加一个SQL statement.
图 1: 使用 SQL Statement
在下一个窗体我们可以指定创建哪种SQL .由于查询只返回一个值–Products表的总记录条数–我们选择“SELECT which returns a singe value”.
图 2: 使用 SELECT Statement that Returns a Single Value来配置SQL
下一步是写SQL语句.
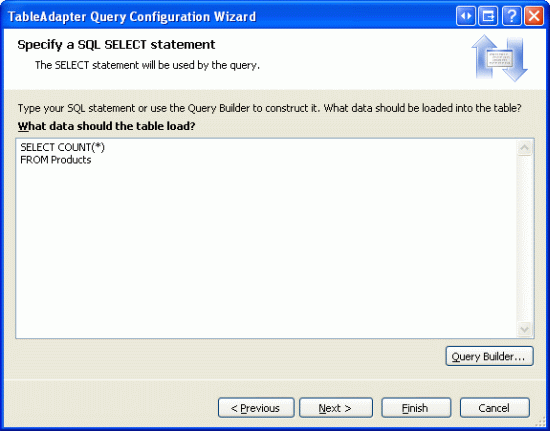
图 3: 使用SELECT COUNT(*) FROM Products 语句
最后给这个方法命名为TotalNumberOfProducts.
图 4: 将方法命名为 TotalNumberOfProducts
点击结束后,DAL里添加了一个TotalNumberOfProducts方法.这个方法返回的值可为空,而Count语句总是返回一个非空的值.
我们还需要在BLL中加一个方法.打开ProductsBLL类文件,添加一个TotalNumberOfProducts方法,这个方法要做的只是调用DAL的TotalNumberOfProducts方法.
| C# | |
1 2 3 4 | public int TotalNumberOfProducts()
{
return Adapter.TotalNumberOfProducts().GetValueOrDefault();
} |
DAL的TotalNumberOfProducts方法返回一个可空的整型,而需要ProductsBLL类的TotalNumberOfProducts方法返回一个标准的整型.调用GetValueOrDefault方法,如果可为空的整型为空,则返回默认值,0.
下一步我们要在DAL和BLL里创建接受Start Row Index 和Maximum Rows 的方法,然后返回合适的记录.我们首先看看需要的SQL语句.我们面临的挑战是需要为整个分页的记录分配索引,用来返回从Start Row Index 开始的Maximum Records number of records条记录.
如果在数据库表里已经有一个列作为索引,那么一切会变的很简单.我们首先会想到Products表的ProductID字段可以满足这个条件,第一个 Product的ProductID为1,第二个为2,以此类推.然而当一个product被删除后,这个序列会留下间隔来,所以这个方法不行.
有两种可以把整个要分页的数据和一个row index关联起来的方法.
使用SQL Server 2005的ROW_NUMBER() Keyword – SQL Server 2005的新特性,它可以将记录根据一定的顺序排列,每条记录和一个等级相关 这个等级可以用来作为每条记录的row index.
使用SET ROWCOUNT – SQL Server的 SET ROWCOUNT statement 可以用来指定有多少记录需要处理; table variables 是可以存放表格式的T-SQL 变量, 和temporary tables类似. 这个方法在Microsoft SQL Server 2005 和SQL Server 2000都可以用 (ROW_NUMBER() 方法只能在SQL Server 2005里用).
这个思路是,为要分页的数据创建一个table变量,这个table变量里有一个作为主健的IDENTITY列.这样需要分页的每条记录在table变量里就和一个row index(通过IDENTITY列)关联起来了.一旦table变量产生,连接数据库表的SELECT语句就被执行,获取需要的记录.SET ROWCOUNT用来限制放到table变量里的记录的数量.
当SET ROWCOUNT的值指定为Start Row Index 加上Maximum Rows时,这个方法的效率取决于被请求的页数.对于比较前面的页来说– 比如开始几页的数据– 这种方法非常有效. 但是对接近尾部的页来说,这种方法的效率和默认分页时差不多.
本教程用ROW_NUMBER()来实现自定义分页.如果需要知道更多的关于table变量和SET ROWCOUNT的技术,请看 A More Efficient Method for Paging Through Large Result Sets.
以下语句用来使用ROW_NUMBER()将一个等级和返回的每条记录关联:
| SQL | |
1 2 3 | SELECT columnList,
ROW_NUMBER() OVER(orderByClause)
FROM TableName |
ROW_NUMBER()返回一个根据指定排序的表示每条记录的等级的值.比如,我们可以用以下居于查看根据价格来排序(降序)的每个product的等级:
| SQL | |
1 2 3 | SELECT ProductName, UnitPrice,
ROW_NUMBER() OVER(ORDER BY UnitPrice DESC) AS PriceRank
FROM Products |
图5 是在Visual Studio里运行以上代码的结果. 注意product根据价格排序,每行有一个等级.
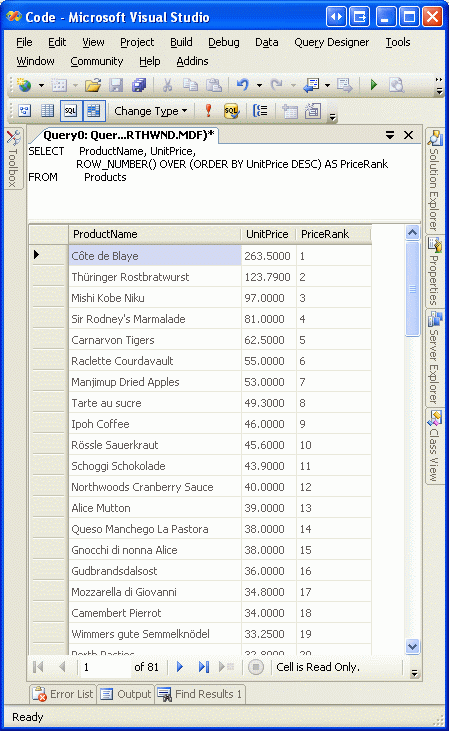
图 5: 返回的记录里每行有一个Price Rank
注意: ROW_NUMBER() 只是 SQL Server 2005里很多排级的功能中的一种. 想了解更多的ROW_NUMBER()的讨论,包括其它的排级功能,请看 Returning Ranked Results with Microsoft SQL Server 2005.
当使用OVER从句里的ORDER BY 列名(UnitPrice)来排级时,SQL Server会对结果排序.为了提升大数据量查询时的性能,可以为用来排序的列加上非聚集索引.更多的性能考虑参考Ranking Functions and Performance in SQL Server 2005.
ROW_NUMBER()返回的等级信息无法直接在WHERE从句中使用.而在From后面的Select里可以返回ROW_NUMBER(),并在 WHERE从句里使用.比如,下面的语句使用一个From后的Select返回ProductName,UnitPrice,和ROW_NUMBER() 的结果,然后使用一个WHERE从句来返回price rank在11到20之间的product.
| SQL | |
1 2 3 4 5 6 7 | SELECT PriceRank, ProductName, UnitPrice
FROM
(SELECT ProductName, UnitPrice,
ROW_NUMBER() OVER(ORDER BY UnitPrice DESC) AS PriceRank
FROM Products
) AS ProductsWithRowNumber
WHERE PriceRank BETWEEN 11 AND 20 |
更进一步,我们可以根据这个方法返回给定Start Row Index 和Maximum Rows 的页的数据.
| SQL | |
1 2 3 4 5 6 7 | SELECT PriceRank, ProductName, UnitPrice
FROM
(SELECT ProductName, UnitPrice,
ROW_NUMBER() OVER(ORDER BY UnitPrice DESC) AS PriceRank
FROM Products
) AS ProductsWithRowNumber
WHERE PriceRank > <i>StartRowIndex</i> AND PriceRank <= (<i>StartRowIndex</i> + <i>MaximumRows</i>) |
注意:我们在本教程的后面会看到, ObjectDataSource 提供的StartRowIndex是从0开始的,而ROW_NUMBER()的值从1开始.因此,WHERE从句返回会严格返回PriceRank大于 StartRowIndex而小于StartRowIndex+MaximumRows的那些记录.
我们已经知道如何根据给定的Start Row Index 和Maximum Rows 用ROW_NUMBER()返回特定页的数据.现在我们需要在DAL和BLL里实现它.
我们首先要决定根据什么排序来分级.我们这里用product名字的字母顺序.这意味着我们还不能同时实现排序的功能.在后面的教程里,我们将学习如何实现这样的功能.
在前面我们使用SQL statement创建DAL方法.但是TableAdapter wizard 使用的Visual Stuido里的T-SQL 解析器不能识别带OVER语法的ROW_NUMBER()方法.因此我们要以存储过程来创建这个DAL方法.从view menu里选择server explorer(Ctrl+Alt+S),展开NORTHWND.MDF 的节点.右键点击存储过程,选择增加一个新的存储过程(见图6).
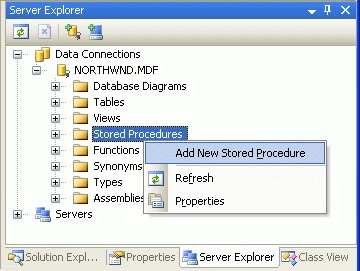
图 6: 为Products分页增加一个存储过程
这个存储过程带两个整型的输入参数- @startRowIndex和@maximumRows- 并用ROW_NUMBER()以ProductName字段排序,返回那些大于@startRowIndex并小于等于 @startRowIndex+@maximumRows的记录.将以下代码加到存储过程里,然后保存.
| SQL | |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | CREATE PROCEDURE dbo.GetProductsPaged
(
@startRowIndex int,
@maximumRows int
)
AS
SELECT ProductID, ProductName, SupplierID, CategoryID, QuantityPerUnit, UnitPrice, UnitsInStock, UnitsOnOrder, ReorderLevel, Discontinued, CategoryName, SupplierName
FROM
(
SELECT ProductID, ProductName, SupplierID, CategoryID, QuantityPerUnit, UnitPrice, UnitsInStock, UnitsOnOrder, ReorderLevel, Discontinued,
(SELECT CategoryName
FROM Categories
WHERE Categories.CategoryID = Products.CategoryID) AS CategoryName,
(SELECT CompanyName
FROM Suppliers
WHERE Suppliers.SupplierID = Products.SupplierID) AS SupplierName,
ROW_NUMBER() OVER (ORDER BY ProductName) AS RowRank
FROM Products
) AS ProductsWithRowNumbers
WHERE RowRank > @startRowIndex AND RowRank <= (@startRowIndex + @maximumRows) |
创建完存储过程后,花点时间测试一下.右键在Server Explorer 点名为GetProductsPaged的存储过程,选择执行.Visual Studio 会让你输入参数, @startRowIndex和@maximumRows(见图7).输入不同的值查看一下结果是什么.
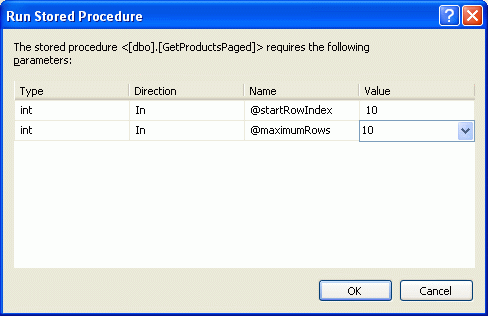
图 7: 为 @startRowIndex 和@maximumRows Parameters输入值
输入参数的值后,你会看到结果.图8的结果为两个参数的值都为10的结果.
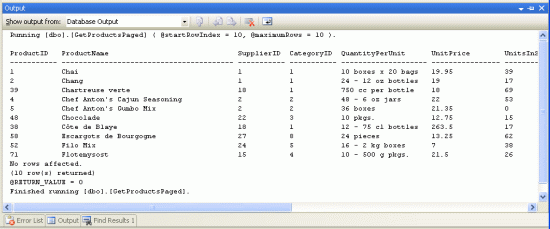
图 8: 将在第二页里显示的数据
完成存储过程后,我们可以创建ProductsTableAdapter 方法了.打开Northwind.xsd ,右键点ProductsTableAdapter,选择Add Query.选择使用已经存在的存储过程.
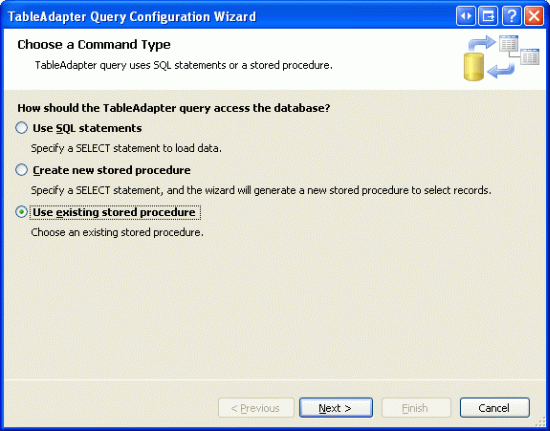
图 9: 使用已经存在的存储过程创建DAL Method
下一步会要我们选择要调用的存储过程.从下拉列表里选择GetProductsPaged .
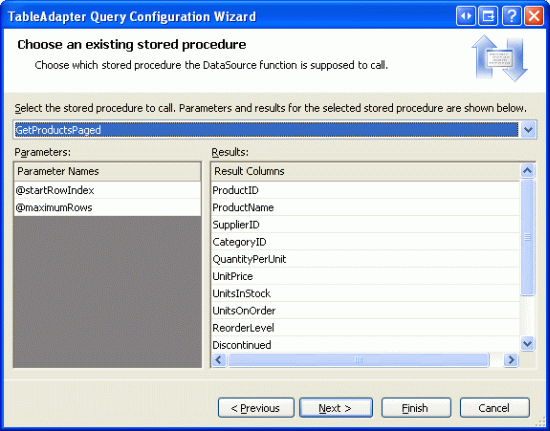
图10: 选择GetProductsPaged
下一步要选择存储过程返回的数据类型:表值,单一值,无值.由于GetProductsPaged 返回多条记录,所以选择表值.
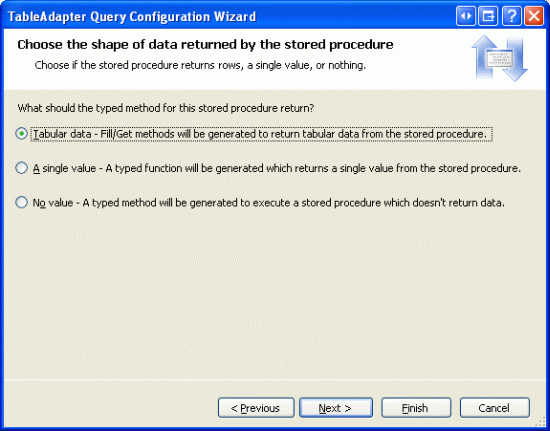
图 11: 为存储过程指定返回表值
最后给方法命名.象前面的方法一样,选择Fill a DataTable 和Return a DataTable,为第一个命名为FillPaged ,第二个为GetProductsPaged.
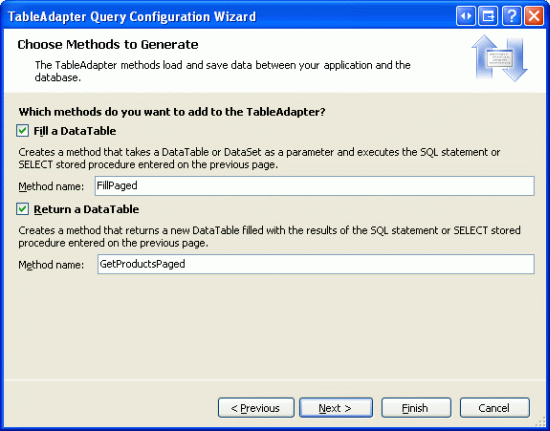
图 12: 命名方法为FillPaged 和GetProductsPaged
除了创建一个DAL方法返回特定页的products外,我们需要在BLL里也这样做.和DAL方法一样,BLL的GetProductsPaged 方法带两个整型的输入参数,分别为Start Row Index 和Maximum Rows,并返回在指定范围内的记录.在ProductsBLL 创建这个方法,仅仅调用DAL的GetProductsPaged 就可以了.
| C# | |
1 2 3 4 5 | [System.ComponentModel.DataObjectMethodAttribute(System.ComponentModel.DataObjectMethodType.Select, false)]
public Northwind.ProductsDataTable GetProductsPaged(int startRowIndex, int maximumRows)
{
return Adapter.GetProductsPaged(startRowIndex, maximumRows);
} |
你可以为BLL方法的参数取任何名字.但是我们马上会看到,选择用startRowIndex 和maximumRows 会让我们在配置ObjectDataSource 时方便很多.
感谢各位的阅读,以上就是“如何提高大数据量分页的效率”的内容了,经过本文的学习后,相信大家对如何提高大数据量分页的效率这一问题有了更深刻的体会,具体使用情况还需要大家实践验证。这里是亿速云,小编将为大家推送更多相关知识点的文章,欢迎关注!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://www.jb51.net/article/17378.htm



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



