这篇文章主要讲解了“如何实现微服务前端数据加载”,文中的讲解内容简单清晰,易于学习与理解,下面请大家跟着小编的思路慢慢深入,一起来研究和学习“如何实现微服务前端数据加载”吧!
目前在不少团队里已经逐步实践落地了微服务架构,比如前端圈很流行的 BFF(Backend For Frontend)其实就是微服务架构的一种变种,即让前端团队维护一套“胶水层/接入层/API层”的服务,调用后台团队提供的若干个微服务,将微服务的结果进行逻辑组装,从而包装出对外的 API。
在这种架构下,服务在大体上可以分为两种角色:
前端服务(Frontend),包装底层的微服务,对外直接暴露可调用的 API。例如在 BFF 架构里,很可能就是一个 Node.js 写成的 HTTP Server。
后台微服务(Microservices),通常由后端团队提供的单体服务,承载不同模块的功能,提供一系列的内部调用接口。
我们先考虑一种最简单的情形,也就是每当有外部请求进来,那么前端服务都会向若干个后台微服务请求数据,然后进行逻辑处理,返回响应:
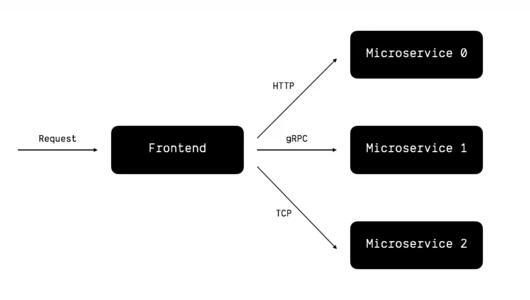
这种朴素的模型明显存在一个问题:每个外部请求都会触发多次内部服务调用,这样的做法非常浪费资源,因为对于大多数内部微服务而言,请求的结果在一定的时间内都是 可缓存 的。
比如用户的头像可能几天几周甚至几个月才更新一次,这种情况下前端服务完全可以缓存用户的头像一段时间,这段时间内,读取用户头像可以从直接从缓存内读取,而不需要请求后台,很大程度上节省了后台服务的负担。
于是我们在前端服务中加入了本地内存缓存(Local Cache),让大多数请求都命中本地缓存,从而减少了后台服务的负担:
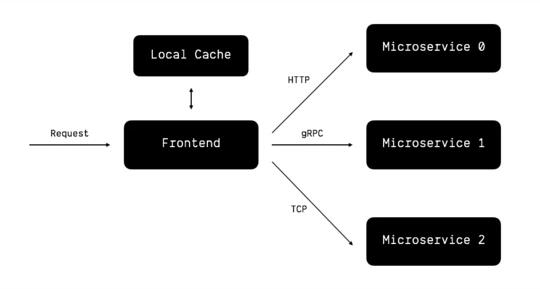
本地缓存通常是放置在内存里的,而内存空间比较有限,所以我们需要引入 缓存淘汰 的机制,限制内存最大容量。具体的缓存淘汰算法就有很多了,比如 FIFO、LFU、LRU、MRU、ARC 等等,可以根据业务的实际情况来选择合适的算法。
引入本地缓存之后,依然会有一个问题:缓存只能在单个服务实例(服务实例可以理解为服务器、K8S Pod之类的概念)上生效,而大多数前端服务为了能够横向扩容,一般都是无状态的,所以会有大量并存的实例。
也就是说,本地缓存可能只会在某台服务器上生效,而其他平行的服务器上没有缓存,如果请求打到了没有缓存的服务器上,那么依然无法命中缓存。
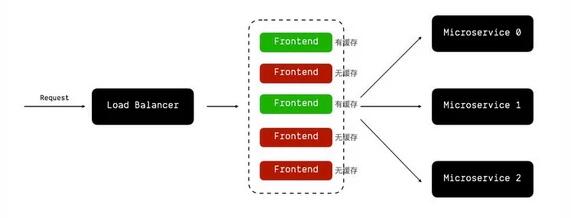
另外一个问题就是,缓存逻辑和应用逻辑是耦合的,每一个接口的代码里可能都会存在类似这样的逻辑:
var cachedData = cache.get(key) if (cachedData !== undefined) { return cachedData } else { return fetch('...') }Don't Repeat Yourself! 我们显然需要把这段缓存逻辑抽象出来,避免重复代码。
为了解决上面两个问题,我们继续改进我们的架构:
加入 中心化的远程缓存 (比如 Redis、Memcache),让远程缓存可以作用到所有实例上面;
将缓存、RPC 等非应用层的逻辑 抽象为单独的组件(Cache Layer) ,用来封装后台微服务的读写、本地缓存、远程缓存相关的逻辑。
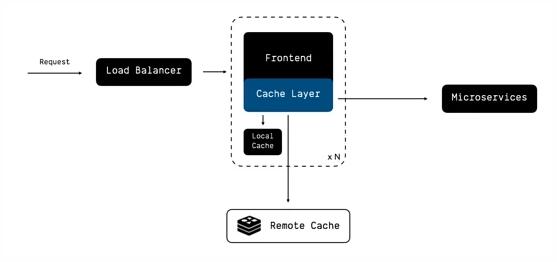
抽象出这样一层 Cache Layer 之后,我们便可以进一步演进我们的服务。
虽然我们有了中心化的缓存,但缓存毕竟只是短期内有效的。一旦缓存失效,那就还是得向后台服务请求数据,在这种临界条件下,请求耗时就会增加,出现耗时的毛刺现象(每隔一段时间,有小部分请求耗时变大)。
那么 有没有办法可以让缓存一直保持“新鲜”呢 ?这就需要缓存刷新的机制了,大体上讲,缓存刷新分为主动刷新和被动刷新两种:
主动刷新
主动刷新即每当数据有更新的时候,刷新缓存,下游服务永远只读取缓存内的数据。
读多写少的后台服务非常适合这种模式,因为读请求永远不会打到数据库里,而是被分流到性能、扩展性高几个档次的缓存组件上面,从而很大程度上减轻数据库的压力。
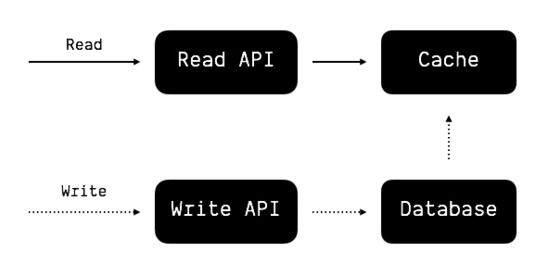
当然主动刷新也并不是完美无缺的,它意味着 前后端服务必须要在缓存组件上产生耦合 (比如需要约定缓存 key 的命名、数据结构等),这就带来了一定的隐患,一旦后端微服务错误地写入了缓存,或者缓存组件出现可用性问题,结果很可能是灾难性的。所以这种模式更适合单个服务内部,而不是多个服务之间。
被动刷新
被动刷新即读取缓存数据的时候,根据缓存的剩余有效期或者类似指标,决定要不要异步刷新缓存(类似 HTTP 协议的 stale-while-revalidate )。
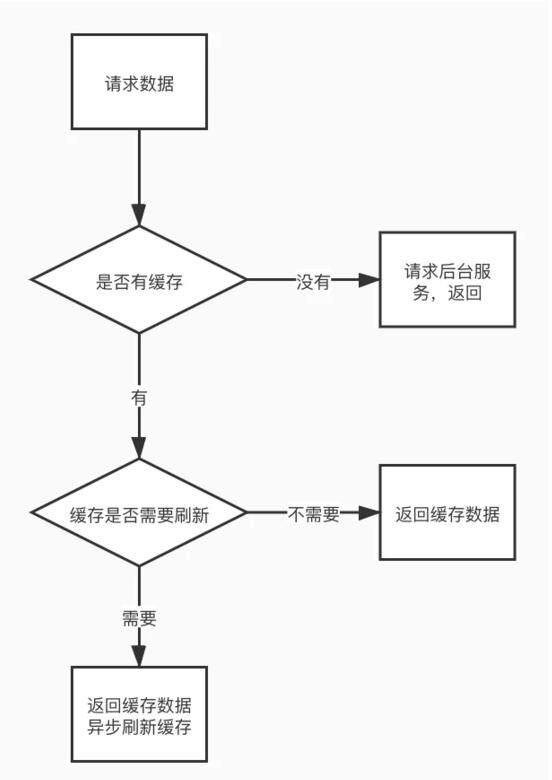
这种模式相比于主动刷新,优点是服务间的耦合更少一些,但缺点在于 1. 只能根据访问热点进行缓存,无法全量缓存;2. 只能根据相关指标被动刷新,降低了数据的即时性。
如果团队的前端服务(如 BFF)和后台服务是由两套人员开发维护,比较适合使用这样的缓存模式。当然具体选择哪种模式,得根据实际情况来决定。
缓存是一个非常灵活并且万金油的组件,这里篇幅有限就不再深入,更多关于缓存的设计模式,可以参考这里:
donnemartin/system-design-primer github.com
对于大流量的业务而言,可能同时会有成百上千的请求打到同一个前端服务实例上,这些请求会触发大量的对缓存、后台服务的读请求,大多数情况下,这些并发的读请求是可以 收归为少数几个请求 的。
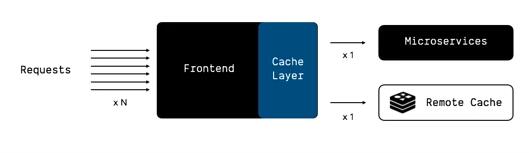
这种思路和 Facebook 开源的dataloader 非常相似,将并行的、参数相同的请求收归到一起,从而降低后端服务的压力(在 GraphQL 的使用场景下很容易出现这种问题)。
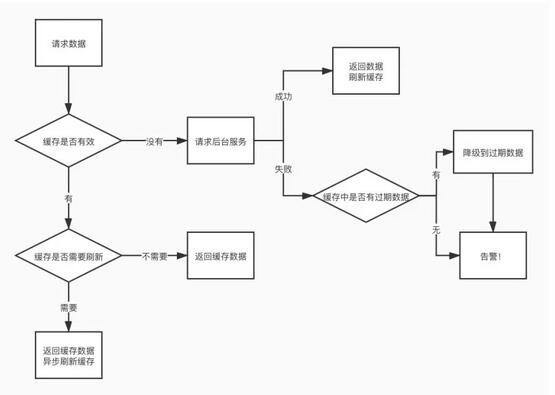
我们不妨考虑一种极端的情况:如果后台服务全挂了,前端服务能不能使用缓存里的来“撑住”一段时间?这就是容灾缓存的概念,即 在服务异常的时候,降级到使用缓存中的数据来响应外部请求,保证一定的可用性 。容灾缓存的逻辑,同样可以抽象到 Cache Layer 中。
感谢各位的阅读,以上就是“如何实现微服务前端数据加载”的内容了,经过本文的学习后,相信大家对如何实现微服务前端数据加载这一问题有了更深刻的体会,具体使用情况还需要大家实践验证。这里是亿速云,小编将为大家推送更多相关知识点的文章,欢迎关注!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://zhuanlan.zhihu.com/p/351044054?utm_source=tuicool&utm_medium=referral



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



