这篇文章给大家介绍分布式计算Hadoop指的是什么,内容非常详细,感兴趣的小伙伴们可以参考借鉴,希望对大家能有所帮助。
Hadoop是什么:Hadoop是一个开发和运行处理大规模数据的软件平台,是Appach的一个用java语言实现开源软件框架,实现在大量计算机组成的集群中对海量数据进行分布式计算。
Hadoop框架中最核心设计就是:HDFS和MapReduce。HDFS提供了海量数据的存储,MapReduce提供了对数据的计算。
数据在Hadoop中处理的流程可以简单的按照下图来理解:数据通过Haddop的集群处理后得到结果。
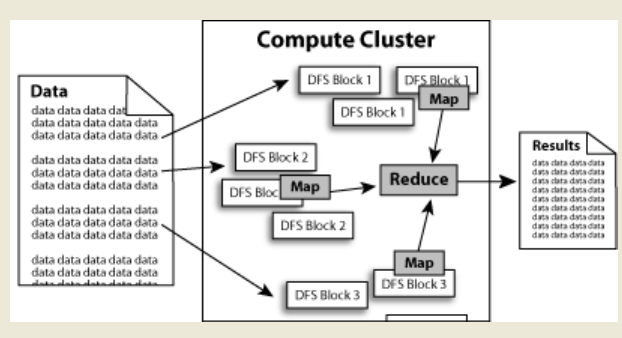
HDFS:Hadoop Distributed File System,Hadoop的分布式文件系统。
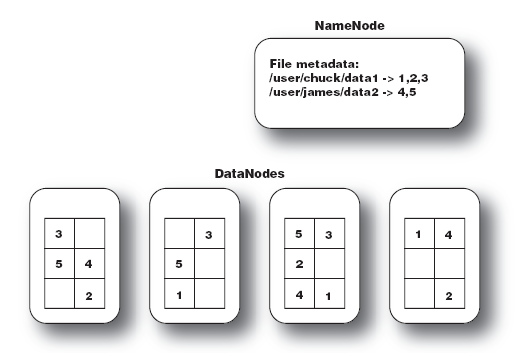
大文件被分成默认64M一块的数据块分布存储在集群机器中。
如下图中的文件 data1被分成3块,这3块以冗余镜像的方式分布在不同的机器中。
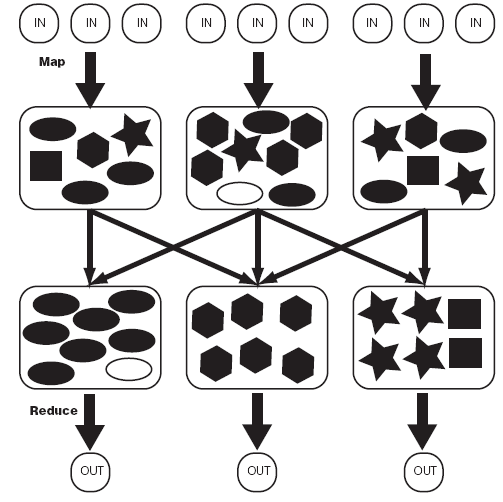
MapReduce:Hadoop为每一个input split创建一个task调用Map计算,在此task中依次处理此split中的一个个记录(record),map会将结果以key--value的形式输出,hadoop负责按key值将map的输出整理后作为Reduce的输入,Reduce Task的输出为整个job的输出,保存在HDFS上。
Hadoop的集群主要由 NameNode,DataNode,Secondary NameNode,JobTracker,TaskTracker组成。
如下图所示:
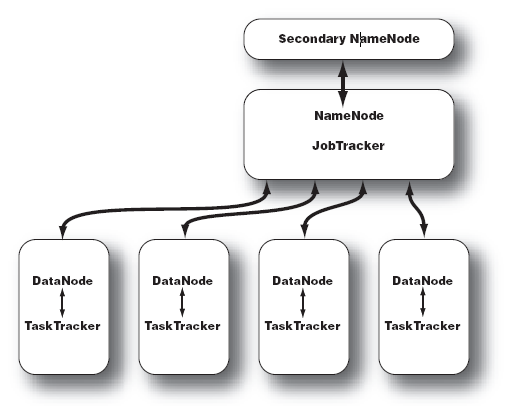
NameNode中记录了文件是如何被拆分成block以及这些block都存储到了那些DateNode节点。
NameNode同时保存了文件系统运行的状态信息。
DataNode中存储的是被拆分的blocks。
Secondary NameNode帮助NameNode收集文件系统运行的状态信息。
JobTracker当有任务提交到Hadoop集群的时候负责Job的运行,负责调度多个TaskTracker。
TaskTracker负责某一个map或者reduce任务。
关于分布式计算Hadoop指的是什么就分享到这里了,希望以上内容可以对大家有一定的帮助,可以学到更多知识。如果觉得文章不错,可以把它分享出去让更多的人看到。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





