这篇文章主要介绍“什么是hashCode”,在日常操作中,相信很多人在什么是hashCode问题上存在疑惑,小编查阅了各式资料,整理出简单好用的操作方法,希望对大家解答”什么是hashCode”的疑惑有所帮助!接下来,请跟着小编一起来学习吧!
什么是 hashCode?
我们通常说的 hashCode 其实就是一个经过哈希运算之后的整型值。而这个哈希运算的算法,在 Object 类中就是通过一个本地方法 hashCode() 来实现的(HashMap 中还会有一些其它的运算)。
public native int hashCode();可以看到它是一个本地方法。那么,想要了解这个方法到底是用来干嘛的,最直接有效的方法就是,去看它的源码注释。
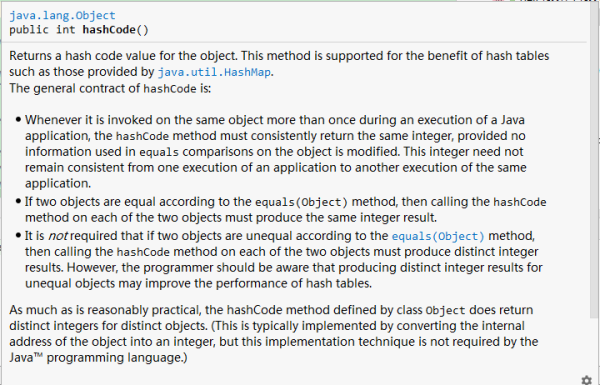
下边我就用我蹩脚的英文翻译一下它的意思。。。
返回当前对象的一个哈希值。这个方法用于支持一些哈希表,例如 HashMap 。
通常来讲,它有如下一些约定:
若对象的信息没有被修改,那么,在一个程序的执行期间,对于相同的对象,不管调用多少次 hashCode 方法,都应该返回相同的值。当然,在相同程序的不同执行期间,不需要保持结果一致。
若两个对象的 equals 方法返回值相同,那么,调用它们各自的 hashCode 方法时,也必须返回相同的结果。(ps: 这句话解答了上边的一些问题,后面会用例子来证明这一点)
当两个对象的 equals 方法返回值不同时,那么它们的 hashCode 方法不用保证必须返回不同的值。但是,我们应该知道,在这种情况下,我们最好也设计成 hashCode 返回不同的值。因为,这样做有助于提高哈希表的性能。
在实际情况下,Object 类的 hashCode 方法在不同的对象中确实返回了不同的哈希值。这通常是通过把对象的内部地址转换为一个整数来实现的。
ps: 这里说的内部地址就是指物理地址,也就是内存地址。需要注意的是,虽然 hashCode 值是依据它的内存地址而得来的。但是,不能说 hashCode 就代表对象的内存地址,实际上,hashCode 地址是存放在哈希表中的。
上边的源码注释真可谓是句句珠玑,把 hashCode 方法解释的淋漓尽致。一会儿我通过一个案例说明,就能明白我为什么这样说了。
什么是哈希表?
上文中提到了哈希表。什么是哈希表呢?我们直接看百度百科的解释。

用一张图来表示它们的关系。
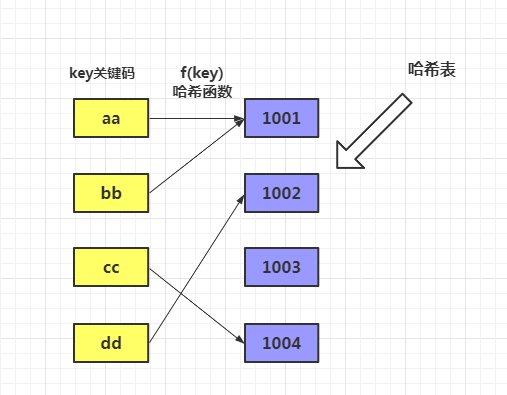
左边一列就是一些关键码(key),通过哈希函数,它们都会得到一个固定的值,分别对应右边一列的某个值。右边的这一列就可以认为是一张哈希表。
而且,我们会发现,有可能有些 key 不同,但是它们对应的哈希值却是一样的,例如 aa,bb 都指向 1001 。但是,一定不会出现同一个 key 指向不同的值。
这也非常好理解,因为哈希表就是用来查找 key 的哈希地址的。在 key 确定的情况下,通过哈希函数计算出来的 哈希地址,一定也是确定的。如图中的 cc 已经确定在 1002 位置了,那么就不可能再占据 1003 位置。
思考一下,如果有另外一个元素 ee 来了,它的哈希地址也落在 1002 位置,怎么办呢?
hashCode 有什么用?
其实,上图就已经可以说明一些问题了。我们通过一个 key 计算出它的 hashCode 值,就可以唯一确定它在哈希表中的位置。这样,在查询时,就可以直接定位到当前元素,提高查询效率。
现在我们假设有这样一个场景。我们需要在内存中的一块儿区域存放 10000 个不同的元素(以aa,bb,cc,dd 等为例)。那怎么实现不同的元素插入,相同的元素覆盖呢?
我们最容易想到的方法就是,每当存一个新元素时,就遍历一遍已经存在的元素,看有没有相同的。这样虽然也是可以实现的,但是,如果已经存在了 9000 个元素,你就需要去遍历一下这 9000 个元素。很明显,这样的效率是非常低下的。
我们转换一种思路,还是以上图为例。若来了一个新元素 ff,首先去计算它的 hashCode 值,得出为 1003 。发现此处还没有元素,则直接把这个新元素 ff 放到此位置。
然后,ee 来了,通过计算哈希值得到 1002 。此时,发现 1002 位置已经存在一个元素了。那么,通过 equals 方法比较它们是否相等,发现只有一个 dd 元素,很明显和 ee 不相等。那么,就把 ee 元素放到 dd 元素的后边(可以用链表形式存放)。
我们会发现,当有新元素来的时候,先去计算它们的哈希值,再去确定存放的位置,这样就可以减少比较的次数。如 ff 不需要比较, ee 只需要和 dd 比较一次。
当元素越来越多的时候,新元素也只需要和当前哈希值相同的位置上,已经存在的元素进行比较。而不需要和其他哈希值不同的位置上的元素进行比较。这样就大大减少了元素的比较次数。
图中为了方便,画的哈希表比较小。现在假设,这个哈希表非常的大,例如有这么非常多个位置,从 1001 ~ 9999。那么,新元素插入的时候,有很大概率会插入到一个还没有元素存在的位置上,这样就不需要比较了,效率非常高。但是,我们会发现这样也有一个弊端,就是哈希表所占的内存空间就会变大。因此,这是一个权衡的过程。
有心的同学可能已经发现了。我去,上边的这个做法好熟悉啊。没错,它就是大名鼎鼎的 HashMap 底层实现的思想。对 HashMap 还不了解的,赶紧看这篇文章理一下思路:HashMap 底层实现原理及源码分析
所以,hashCode 有什么用。很明显,提高了查询,插入元素的效率呀。
equals 和 == 有什么区别?
这是万年不变,经久不衰的经典面试题了。让我油然想起,当初为了面试,背诵过的面经了,简直是一把心酸一把泪。现在还能记得这道题的标准答案:equals 比较的是内容, == 比较的是地址。
当时,真的就只是背答案,知其然而不知其所以然。再往下问,为什么要重写 equals ,就懵逼了。
首先,我们应该知道 equals 是定义在所有类的父类 Object 中的。
public boolean equals(Object obj) { return (this == obj); }可以看到,它的默认实现,就是 == ,这是用来比较内存地址的。所以,如果一个对象的 equals 不重写的话,和 == 的效果是一样的。
我们知道,当创建两个普通对象时,一般情况下,它们所对应的内存地址是不一样的。例如,我定义一个 User 类。
public class User { private String name; private int age; public String getName() { return name; } public void setName(String name) { this.name = name; } public int getAge() { return age; } public void setAge(int age) { this.age = age; } public User(String name, int age) { this.name = name; this.age = age; } public User() { } } public class TestHashCode { public static void main(String[] args) { User user1 = new User("zhangsan", 20); User user2 = new User("lisi", 18); System.out.println(user1 == user2); System.out.println(user1.equals(user2)); } } // 结果:false false很明显,zhangsan 和 lisi 是两个人,两个不同的对象。因此,它们所对应的内存地址不同,而且内容也不相等。
注意,这里我还没有对 User 重写 equals,实际此时 equals 使用的是父类 Object 的方法,返回的肯定是不相等的。因此,为了更好地说明问题,我仅把第二行代码修改如下:
//User user2 = new User("lisi", 18); User user2 = new User("zhangsan", 20);让 user1 和 user2 的内容相同,都是 zhangsan,20岁。按我们的理解,这虽然是两个对象,但是应该是指的同一个人,都是张三。但是,打印结果,如下:
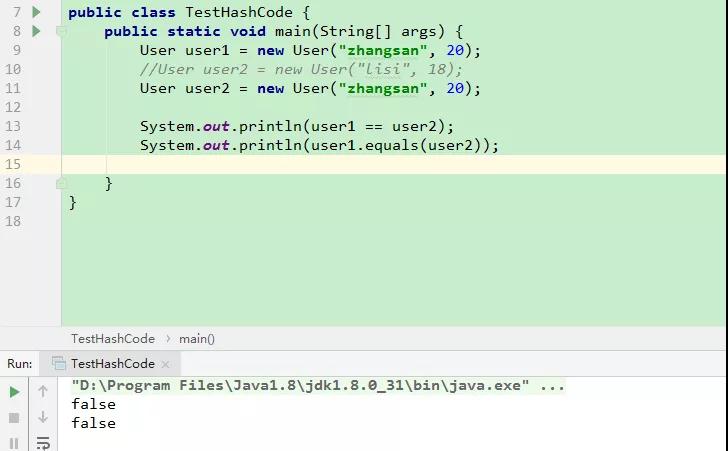
这有悖于我们的认知,明明是同一个人,为什么 equals 返回的却不相等呢。因此,此时我们就需要把 User 类中的 equals 方法重写,以达到我们的目的。在 User 中添加如下代码(使用 idea 自动生成代码):
public class User { ... //省略已知代码 @Override public boolean equals(Object o) { //若两个对象的内存地址相同,则说明指向的是同一个对象,故内容一定相同。 if (this == o) return true; //类都不是同一个,更别谈相等了 if (o == null || getClass() != o.getClass()) return false; User user = (User) o; //比较两个对象中的所有属性,即name和age都必须相同,才可认为两个对象相等 return age == user.age && Objects.equals(name, user.name); } } //打印结果: false true再次执行程序,我们会发现此时 equals 返回 true ,这才是我们想要的。
因此,当我们使用自定义对象时。如果需要让两个对象的内容相同时,equals 返回 true,则需要重写 equals 方法。
为什么要重写 equals 和 hashCode ?
在上边的案例中,其实我们已经说明了为什么要去重写 equals 。因为,在对象内容相同的情况下,我们需要让对象相等。因此,不能用 Object 类的默认实现,只去比较内存地址,这样是不合理的。
那 hashCode 为什么要重写呢?这就涉及到集合,如 Map 和 Set (底层其实也是 Map)了。
我们以 HashMap JDK1.8的源码来看,如 put 方法。
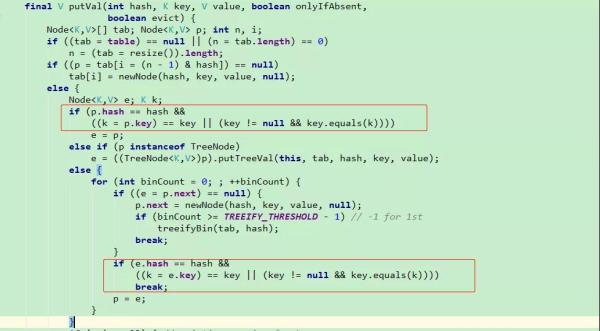
我们会发现,代码中会多次进行 hash 值的比较,只有当哈希值相等时,才会去比较 equals 方法。当 hashCode 和 equals 都相同时,才会覆盖元素。get 方法也是如此(先比较哈希值,再比较equals),
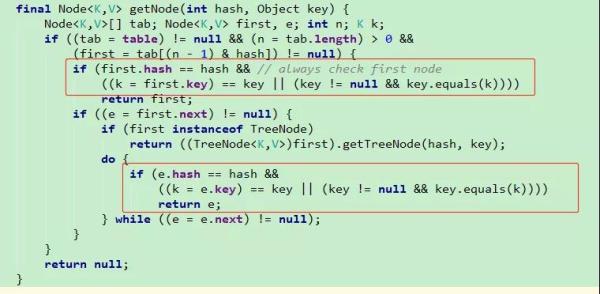
只有 hashCode 和 equals 都相等时,才认为是同一个元素,找到并返回此元素,否则返回 null。
这也对应 “hashCode 有什么用?”这一小节。重写 equals 和 hashCode 的目的,就是为了方便哈希表这样的结构快速的查询和插入。如果不重写,则无法比较元素,甚至造成元素位置错乱。
重写了 equals ,就必须要重写 hashCode 吗?
答案是肯定的。首先,在上边的 JDK 源码注释中第第二点,我们就会发现这句说明。其次,我们尝试重写 equals ,而不重写 hashCode 看会发生什么现象。
public class TestHashCode { public static void main(String[] args) { User user1 = new User("zhangsan", 20); User user2 = new User("zhangsan", 20); HashMap<User, Integer> map = new HashMap<>(); map.put(user1,90); System.out.println(map.get(user2)); } } // 打印结果:null对于代码中的 user1 和 user2 两个对象来说,我们认为他是同一个人张三。定义一个 map ,key 存储 User 对象, value 存储他的学习成绩。
当把 user1 对象作为 key ,成绩 90 作为 value 存储到 map 中时,我们肯定希望,用 key 为 user2 来取值时,得到的结果是 90 。但是,结果却大失所望,得到了 null 。
这是因为,我们自定义的 User 类,虽然重写了 equals ,但是没有重写 hashCode 。当 user1 放到 map 中时,计算出来的哈希值和用 user2 去取值时计算的哈希值不相等。因此,equals 方法都没有比较的机会。认为他们是不同的元素。然而,其实,我们应该认为 user1 和 user2 是相同的元素的。
用图来说明就是,user1 和 user2 存放在了 HashMap 中不同的桶里边,导致查询不到目标元素。
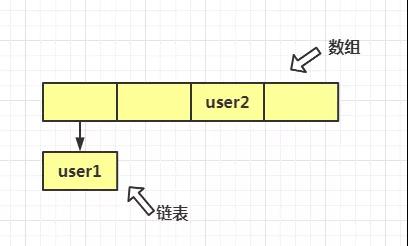
因此,当我们用自定义类来作为 HashMap 的 key 时,必须要重写 hashCode 和 equals 。否则,会得到我们不想要的结果。
这也是为什么,我们平时都喜欢用 String 字符串来作为 key 的原因。因为, String 类默认就帮我们实现了 equals 和 hashCode 方法的重写。如下,
// String.java public boolean equals(Object anObject) { if (this == anObject) { return true; } if (anObject instanceof String) { String anotherString = (String)anObject; int n = value.length; //从前向后依次比较字符串中的每个字符 if (n == anotherString.value.length) { char v1[] = value; char v2[] = anotherString.value; int i = 0; while (n-- != 0) { if (v1[i] != v2[i]) return false; i++; } return true; } } return false; } public int hashCode() { int h = hash; if (h == 0 && value.length > 0) { char val[] = value; //把字符串中的每个字符都取出来,参与运算 for (int i = 0; i < value.length; i++) { h = 31 * h + val[i]; } //把计算出来的最终值,存放在hash变量中。 hash = h; } return h; }重写 equals 时,可以使用 idea 提供的自动代码,也可以自己手动实现。
public class User { ... //省略已知代码 @Override public int hashCode() { return Objects.hash(name, age); } } //此时,map.get(user2) 可以得到 90 的正确值在重写了 hashCode 后,使用自定义对象作为 key 时,还需要注意一点,不要在使用过程中,改变对象的内容,这样会导致 hashCode 值发生改变,同样得不到正确的结果。如下,
public class TestHashCode { public static void main(String[] args) { User user = new User("zhangsan", 20); HashMap<User, Integer> map = new HashMap<>(); map.put(user,90); System.out.println(map.get(user)); user.setAge(18); //把对象的年龄修改为18 System.out.println(map.get(user)); } } // 打印结果: // 90 // null会发现,修改后,拿到的值是 null 。这也是,hashCode 源码注释中的第一点说明的,hashCode 值不变的前提是,对象的信息没有被修改。若被修改,则有可能导致 hashCode 值改变。
此时,有没有联想到其他一些问题。比如,为什么 String 类要设计成不可以变的呢?这里用 String 作为 HashMap 的 key 时,可以算作一个原因。你肯定不希望,放进去的时候还好好的,取出来的时候,却找不到元素了吧。
String 类内部会有一个变量(hash)来缓存字符串的 hashCode 值。只有字符串不可变,才可以保证哈希值不变。
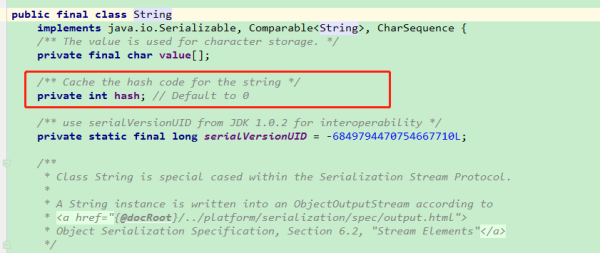
hashCode 相等时,equals 一定相等吗?
很显然不是的。在 HashMap 的源码中,我们就能看到,当 hashCode 相等时(产生哈希碰撞),还需要比较它们的 equals ,才可以确定是否是同一个对象。因此,hashCode 相等时, equals 不一定相等 。
反过来,equals 相等的话, hashCode 一定相等吗?那必须的。equals 都相等了,那说明在 HashMap 中认为它们是同一个元素,所以 hashCode 值必须也要保证相等。
结论:
hashCode 相等,equals 不一定相等。
hashCode 不等,equals 一定不等。
equals 相等, hashCode 一定相等。
equals 不等, hashCode 不一定不等。
关于最后这一点,就是 hashCode 源码注释中提到的第三点。当 equals 不等时,不用必须保证它们的 hashCode 也不相等。但是为了提高哈希表的效率,最好设计成不等。
因为,我们既然知道它们不相等了,那么当 hashCode 设计成不等时。只要比较 hashCode 不相等,我们就可以直接返回 null,而不必再去比较 equals 了。这样,就减少了比较的次数,无疑提高了效率。
到此,关于“什么是hashCode”的学习就结束了,希望能够解决大家的疑惑。理论与实践的搭配能更好的帮助大家学习,快去试试吧!若想继续学习更多相关知识,请继续关注亿速云网站,小编会继续努力为大家带来更多实用的文章!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://mp.weixin.qq.com/s/0497MyIgi3artD_X8feQyA



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



