HBaseзҡ„е·ҘдҪңеҺҹзҗҶ
жң¬зҜҮеҶ…е®№д»Ӣз»ҚдәҶвҖңHBaseзҡ„е·ҘдҪңеҺҹзҗҶвҖқзҡ„жңүе…ізҹҘиҜҶпјҢеңЁе®һйҷ…жЎҲдҫӢзҡ„ж“ҚдҪңиҝҮзЁӢдёӯпјҢдёҚе°‘дәәйғҪдјҡйҒҮеҲ°иҝҷж ·зҡ„еӣ°еўғпјҢжҺҘдёӢжқҘе°ұи®©е°Ҹзј–еёҰйўҶеӨ§е®¶еӯҰд№ дёҖдёӢеҰӮдҪ•еӨ„зҗҶиҝҷдәӣжғ…еҶөеҗ§пјҒеёҢжңӣеӨ§е®¶д»”з»Ҷйҳ…иҜ»пјҢиғҪеӨҹеӯҰжңүжүҖжҲҗпјҒ
HadoopдёӯHBaseе·ҘдҪңзҡ„з®ҖиҰҒжҰӮиҝ°
1.еј•иЁҖ
HBaseжҳҜдёҖз§Қй«ҳеҸҜйқ жҖ§пјҢй«ҳжҖ§иғҪпјҢйқўеҗ‘еҲ—зҡ„еҸҜжү©еұ•еҲҶеёғејҸеӯҳеӮЁзі»з»ҹпјҢе®ғдҪҝз”ЁHBaseжҠҖжңҜеңЁе»үд»·зҡ„PCжңҚеҠЎеҷЁдёҠжһ„е»әеӨ§и§„жЁЎз»“жһ„еҢ–еӯҳеӮЁйӣҶзҫӨгҖӮ HBaseзҡ„зӣ®ж ҮжҳҜеӯҳеӮЁе’ҢеӨ„зҗҶеӨ§йҮҸж•°жҚ®пјҢзү№еҲ«жҳҜд»…дҪҝз”Ёж ҮеҮҶ硬件й…ҚзҪ®еҚіеҸҜеӨ„зҗҶеҢ…еҗ«ж•°еҚғиЎҢе’ҢеҲ—зҡ„еӨ§йҮҸж•°жҚ®гҖӮ
дёҺMapReduceзҡ„зҰ»зәҝжү№йҮҸи®Ўз®—жЎҶжһ¶дёҚеҗҢпјҢHBaseжҳҜйҡҸжңәи®ҝй—®еӯҳеӮЁе’ҢжЈҖзҙўж•°жҚ®е№іеҸ°пјҢејҘиЎҘдәҶHDFSж— жі•йҡҸжңәи®ҝй—®ж•°жҚ®зҡ„зјәзӮ№гҖӮ
е®ғйҖӮз”ЁдәҺе®һж—¶жҖ§иҰҒжұӮдёҚй«ҳзҡ„дёҡеҠЎеңәжҷҜ-HBaseеӯҳеӮЁByteж•°з»„пјҢиҜҘж•°з»„дёҚд»Ӣж„Ҹж•°жҚ®зұ»еһӢпјҢд»ҺиҖҢе…Ғи®ёеҠЁжҖҒпјҢзҒөжҙ»зҡ„ж•°жҚ®жЁЎеһӢгҖӮ
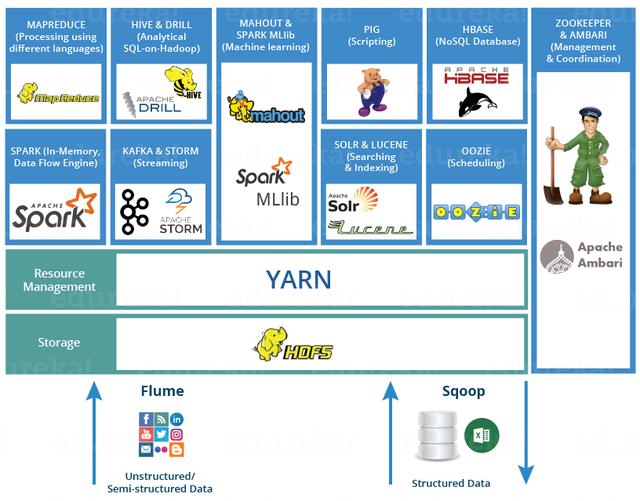
> Hadoop Ecosystem (Credit: Edureka.com)дёҠеӣҫжҸҸз»ҳдәҶHadoop 2.0з”ҹжҖҒзі»з»ҹзҡ„еҗ„дёӘеұӮ-дҪҚдәҺз»“жһ„еҢ–еӯҳеӮЁеұӮдёҠзҡ„HbaseгҖӮ
HDFSдёәHBaseжҸҗдҫӣдәҶй«ҳеҸҜйқ жҖ§зҡ„дҪҺзә§еӯҳеӮЁж”ҜжҢҒгҖӮ
MapReduceдёәHBaseжҸҗдҫӣдәҶй«ҳжҖ§иғҪзҡ„жү№еӨ„зҗҶеҠҹиғҪгҖӮ ZooKeeperдёәHBaseжҸҗдҫӣзЁіе®ҡзҡ„жңҚеҠЎе’Ңж•…йҡңиҪ¬з§»жңәеҲ¶гҖӮ Pigе’ҢHiveдёәж•°жҚ®з»ҹи®ЎеӨ„зҗҶзҡ„й«ҳзә§иҜӯиЁҖж”ҜжҢҒжҸҗдҫӣдәҶHBaseпјҢSqoopдёәHDBжҸҗдҫӣдәҶеҸҜз”Ёзҡ„RDBMSж•°жҚ®еҜје…ҘеҠҹиғҪпјҢиҝҷдҪҝеҫ—д»Һдј з»ҹж•°жҚ®еә“еҲ°HBaseзҡ„дёҡеҠЎж•°жҚ®иҝҒ移йқһеёёж–№дҫҝгҖӮ
2. HBaseжһ¶жһ„
2.1и®ҫи®ЎIdea
HBaseжҳҜдёҖдёӘеҲҶеёғејҸж•°жҚ®еә“пјҢдҪҝз”ЁZooKeeperжқҘз®ЎзҗҶзҫӨйӣҶе’ҢHDFSдҪңдёәеҹәзЎҖеӯҳеӮЁгҖӮ
еңЁдҪ“зі»з»“жһ„зә§еҲ«пјҢе®ғз”ұHMaster(з”ұZookeeperйҖүжӢ©зҡ„йўҶеҜјиҖ…)е’ҢеӨҡдёӘHRegionServersз»„жҲҗгҖӮ
дёӢеӣҫжҳҫзӨәдәҶеҹәзЎҖжһ¶жһ„пјҡ
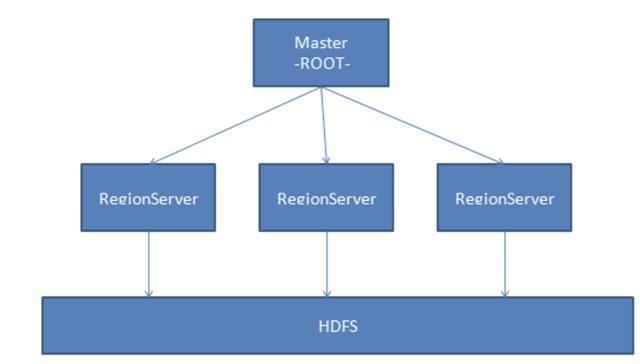
еңЁHBaseзҡ„жҰӮеҝөдёӯпјҢHRegionServerеҜ№еә”дәҺзҫӨйӣҶдёӯзҡ„дёҖдёӘиҠӮзӮ№пјҢдёҖдёӘHRegionServerиҙҹиҙЈз®ЎзҗҶеӨҡдёӘHRegionпјҢдёҖдёӘHRegionд»ЈиЎЁиЎЁж•°жҚ®зҡ„дёҖйғЁеҲҶгҖӮ
еңЁHBaseдёӯпјҢдёҖдёӘиЎЁеҸҜиғҪйңҖиҰҒеҫҲеӨҡHRegionжқҘеӯҳеӮЁж•°жҚ®пјҢ并且жҜҸдёӘHRegionдёӯзҡ„ж•°жҚ®йғҪдёҚдјҡжқӮд№ұж— з« гҖӮ
еҪ“HBaseз®ЎзҗҶHRegionж—¶пјҢе®ғе°ҶдёәжҜҸдёӘHRegionе®ҡд№үдёҖе®ҡиҢғеӣҙзҡ„RowkeyгҖӮ еұһдәҺе®ҡд№үиҢғеӣҙзҡ„ж•°жҚ®е°Ҷ被移дәӨз»ҷзү№е®ҡеҢәеҹҹпјҢд»ҺиҖҢе°ҶиҙҹиҪҪеҲҶй…Қз»ҷеӨҡдёӘиҠӮзӮ№пјҢд»ҺиҖҢеҲ©з”ЁеҲҶеёғе’Ңзү№жҖ§зҡ„дјҳеҠҝгҖӮ
еҗҢж ·пјҢHBaseе°ҶиҮӘеҠЁи°ғж•ҙеҢәеҹҹзҡ„дҪҚзҪ®гҖӮ еҰӮжһңHRegionServerиҝҮзғӯпјҢеҚіеӨ§йҮҸиҜ·жұӮиҗҪеңЁHRegionServerз®ЎзҗҶзҡ„HRegionдёҠпјҢеҲҷHBaseдјҡе°ҶHRegion移еҠЁеҲ°зӣёеҜ№з©әй—Ізҡ„е…¶д»–иҠӮзӮ№пјҢд»ҘзЎ®дҝқе……еҲҶеҲ©з”ЁзҫӨйӣҶзҺҜеўғгҖӮ
2.2еҹәжң¬жһ¶жһ„
HBaseз”ұHMasterе’ҢHRegionServerз»„жҲҗпјҢ并且йҒөеҫӘдё»д»ҺжңҚеҠЎеҷЁдҪ“зі»з»“жһ„гҖӮ HBaseе°ҶйҖ»иҫ‘иЎЁеҲҶдёәеӨҡдёӘж•°жҚ®еқ—HRegionпјҢ并е°Ҷе®ғ们еӯҳеӮЁеңЁHRegionServerдёӯгҖӮ
HMasterиҙҹиҙЈз®ЎзҗҶжүҖжңүHRegionServerгҖӮ е®ғжң¬иә«дёҚеӯҳеӮЁд»»дҪ•ж•°жҚ®пјҢиҖҢд»…еӯҳеӮЁж•°жҚ®еҲ°HRegionServerзҡ„жҳ е°„(е…ғж•°жҚ®)гҖӮ
зҫӨйӣҶдёӯзҡ„жүҖжңүиҠӮзӮ№еқҮз”ұZookeeperеҚҸи°ғпјҢ并еӨ„зҗҶHBaseж“ҚдҪңжңҹй—ҙеҸҜиғҪйҒҮеҲ°зҡ„еҗ„з§Қй—®йўҳгҖӮ HBaseзҡ„еҹәжң¬жһ¶жһ„еҰӮдёӢжүҖзӨәпјҡ
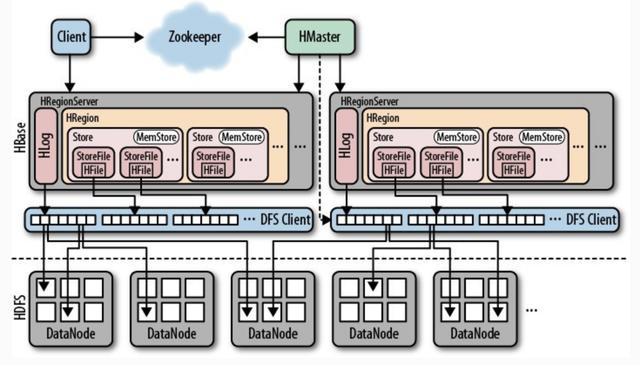
е®ўжҲ·з«ҜпјҡдҪҝз”ЁHBaseзҡ„RPCжңәеҲ¶дёҺHMasterе’ҢHRegionServerйҖҡдҝЎпјҢжҸҗдәӨиҜ·жұӮ并иҺ·еҫ—з»“жһңгҖӮ еҜ№дәҺз®ЎзҗҶж“ҚдҪңпјҢе®ўжҲ·з«ҜдҪҝз”ЁHMasterжү§иЎҢRPCгҖӮ еҜ№дәҺж•°жҚ®иҜ»еҸ–е’ҢеҶҷе…Ҙж“ҚдҪңпјҢе®ўжҲ·з«ҜдҪҝз”ЁHRegionServerжү§иЎҢRPCгҖӮ
ZookeeperпјҡйҖҡиҝҮе°ҶйӣҶзҫӨдёӯжҜҸдёӘиҠӮзӮ№зҡ„зҠ¶жҖҒдҝЎжҒҜжіЁеҶҢеҲ°ZooKeeperпјҢHMasterеҸҜд»ҘйҡҸж—¶ж„ҹзҹҘжҜҸдёӘHRegionServerзҡ„еҒҘеә·зҠ¶жҖҒпјҢиҝҳеҸҜд»ҘйҒҝе…ҚHMasterзҡ„еҚ•зӮ№ж•…йҡңгҖӮ
HMasterпјҡз®ЎзҗҶжүҖжңүHRegionServerпјҢе‘ҠиҜү他们йңҖиҰҒз»ҙжҠӨе“ӘдәӣHRegionпјҢ并зӣ‘и§ҶжүҖжңүHRegionServerзҡ„иҝҗиЎҢзҠ¶еҶөгҖӮ еҪ“ж–°зҡ„HRegionServerзҷ»еҪ•еҲ°HMasterж—¶пјҢHMasterе‘ҠиҜүе®ғзӯүеҫ…ж•°жҚ®еҲҶй…ҚгҖӮ еҪ“HRegionжӯ»дәЎж—¶пјҢHMasterе°Ҷе…¶иҙҹиҙЈзҡ„жүҖжңүHRegionж Үи®°дёәжңӘеҲҶй…ҚпјҢ然еҗҺе°Ҷе®ғ们еҲҶй…Қз»ҷе…¶д»–HRegionServerгҖӮ HMasterжІЎжңүеҚ•зӮ№й—®йўҳгҖӮ HBaseеҸҜд»ҘеҗҜеҠЁеӨҡдёӘHMasterгҖӮ йҖҡиҝҮZookeeperзҡ„йҖүдёҫжңәеҲ¶пјҢзҫӨйӣҶдёӯе§Ӣз»ҲжңүдёҖдёӘHMasterиҝҗиЎҢпјҢд»ҺиҖҢжҸҗй«ҳдәҶзҫӨйӣҶзҡ„еҸҜз”ЁжҖ§гҖӮ
HRegionпјҡеҪ“иЎЁзҡ„еӨ§е°Ҹи¶…иҝҮйў„и®ҫеҖјж—¶пјҢHBaseдјҡиҮӘеҠЁе°ҶиЎЁеҲ’еҲҶдёәдёҚеҗҢзҡ„еҢәеҹҹпјҢжҜҸдёӘеҢәеҹҹйғҪеҢ…еҗ«иЎЁдёӯжүҖжңүиЎҢзҡ„еӯҗйӣҶгҖӮ еҜ№дәҺз”ЁжҲ·жқҘиҜҙпјҢжҜҸдёӘиЎЁйғҪжҳҜж•°жҚ®зҡ„йӣҶеҗҲпјҢз”Ёдё»й”®(RowKey)еҠ д»ҘеҢәеҲҶгҖӮ д»Һзү©зҗҶдёҠи®ІпјҢдёҖдёӘиЎЁеҲҶдёәеӨҡдёӘеқ—пјҢжҜҸдёӘеқ—йғҪжҳҜдёҖдёӘHRegionгҖӮ жҲ‘们дҪҝз”ЁиЎЁеҗҚ+ејҖе§Ӣ/з»“жқҹдё»й”®жқҘеҢәеҲҶжҜҸдёӘHRegionгҖӮ дёҖдёӘHRegionдјҡе°ҶдёҖж®өиҝһз»ӯж•°жҚ®дҝқеӯҳеңЁдёҖдёӘиЎЁдёӯгҖӮ е®Ңж•ҙзҡ„иЎЁж•°жҚ®еӯҳеӮЁеңЁеӨҡдёӘHRegionsдёӯгҖӮ
HRegionServerпјҡHBaseдёӯзҡ„жүҖжңүж•°жҚ®йҖҡеёёд»Һеә•еұӮеӯҳеӮЁеңЁHDFSдёӯгҖӮ з”ЁжҲ·еҸҜд»ҘйҖҡиҝҮдёҖзі»еҲ—HRegionServerиҺ·еҫ—жӯӨж•°жҚ®гҖӮ йҖҡеёёпјҢзҫӨйӣҶзҡ„дёҖдёӘиҠӮзӮ№дёҠд»…иҝҗиЎҢдёҖеҸ°HRegionServerпјҢ并且жҜҸдёӘж®өзҡ„HRegionд»…з”ұдёҖдёӘHRegionServerз»ҙжҠӨгҖӮ HRegionServerдё»иҰҒиҙҹиҙЈе“Қеә”з”ЁжҲ·I / OиҜ·жұӮе°Ҷж•°жҚ®иҜ»еҸ–е’ҢеҶҷе…ҘHDFSж–Ү件系з»ҹгҖӮ е®ғжҳҜHBaseдёӯзҡ„ж ёеҝғжЁЎеқ—гҖӮ HRegionServerеңЁеҶ…йғЁз®ЎзҗҶдёҖзі»еҲ—HRegionеҜ№иұЎпјҢжҜҸдёӘHRegionеҜ№еә”дәҺйҖ»иҫ‘иЎЁдёӯзҡ„иҝһз»ӯж•°жҚ®ж®өгҖӮ HRegionз”ұеӨҡдёӘHStoreз»„жҲҗгҖӮ жҜҸдёӘHStoreеҜ№еә”дәҺйҖ»иҫ‘иЎЁдёӯдёҖдёӘеҲ—ж—Ҹзҡ„еӯҳеӮЁгҖӮ еҸҜд»ҘзңӢеҮәпјҢжҜҸдёӘеҲ—ж—ҸйғҪжҳҜдёҖдёӘйӣҶдёӯејҸеӯҳеӮЁеҚ•е…ғгҖӮ еӣ жӯӨпјҢдёәдәҶжҸҗй«ҳж“ҚдҪңж•ҲзҺҮпјҢжңҖеҘҪе°Ҷе…·жңүе…ұеҗҢI / Oзү№жҖ§зҡ„еҲ—ж”ҫеңЁдёҖдёӘеҲ—зі»еҲ—дёӯгҖӮ
HStoreпјҡе®ғжҳҜHBaseеӯҳеӮЁзҡ„ж ёеҝғпјҢе®ғз”ұMemStoreе’ҢStoreFilesз»„жҲҗгҖӮ MemStoreжҳҜеҶ…еӯҳзј“еҶІеҢәгҖӮз”ЁжҲ·еҶҷе…Ҙзҡ„ж•°жҚ®е°ҶйҰ–е…Ҳж”ҫе…ҘMemStoreгҖӮеҪ“MemStoreе·Іж»Ўж—¶пјҢFlushе°ҶжҳҜдёҖдёӘStoreFile(еә•еұӮе®һзҺ°жҳҜHFile)гҖӮеҪ“StoreFileж–Ү件зҡ„ж•°йҮҸеўһеҠ еҲ°жҹҗдёӘйҳҲеҖјж—¶пјҢе°Ҷи§ҰеҸ‘CompactеҗҲ并ж“ҚдҪңпјҢе°ҶеӨҡдёӘStoreFileеҗҲ并дёәдёҖдёӘStoreFileпјҢ并еңЁеҗҲ并иҝҮзЁӢдёӯжү§иЎҢзүҲжң¬еҗҲ并е’Ңж•°жҚ®еҲ йҷӨж“ҚдҪңгҖӮеӣ жӯӨпјҢеҸҜд»ҘзңӢеҮәпјҢHBaseд»…ж·»еҠ ж•°жҚ®пјҢ并且жүҖжңүжӣҙж–°е’ҢеҲ йҷӨж“ҚдҪңйғҪеңЁеҗҺз»ӯзҡ„CompactиҝӣзЁӢдёӯжү§иЎҢпјҢеӣ жӯӨз”ЁжҲ·зҡ„еҶҷе…Ҙж“ҚдҪңеҸҜд»ҘеңЁе…¶иҝӣе…ҘеҶ…еӯҳеҗҺз«ӢеҚіиҝ”еӣһпјҢд»ҺиҖҢзЎ®дҝқHBaseI /е“ҰеҪ“StoreFiles Compactж—¶пјҢе®ғе°ҶйҖҗжёҗеҪўжҲҗи¶ҠжқҘи¶ҠеӨ§зҡ„StoreFileгҖӮеҪ“еҚ•дёӘStoreFileзҡ„еӨ§е°Ҹи¶…иҝҮжҹҗдёӘйҳҲеҖјж—¶пјҢе°Ҷи§ҰеҸ‘еҲҶеүІж“ҚдҪңгҖӮеҗҢж—¶пјҢеҪ“еүҚзҡ„HRegionе°Ҷиў«жӢҶеҲҶдёә2дёӘHRegionпјҢ并且зҲ¶HRegionе°Ҷи„ұжңәгҖӮ HMasterе°ҶиҝҷдёӨдёӘеӯҗHRegionеҲҶй…Қз»ҷзӣёеә”зҡ„HRegionServerпјҢд»Ҙдҫҝе°ҶеҺҹе§ӢHRegionзҡ„иҙҹиҪҪеҺӢеҠӣеҲҶжөҒеҲ°иҝҷдёӨдёӘHRegionгҖӮ
HLogпјҡжҜҸдёӘHRegionServerйғҪжңүдёҖдёӘHLogеҜ№иұЎпјҢиҜҘеҜ№иұЎжҳҜе®һзҺ°йў„еҶҷж—Ҙеҝ—зҡ„йў„еҶҷж—Ҙеҝ—зұ»гҖӮ жҜҸж¬Ўз”ЁжҲ·е°Ҷж•°жҚ®еҶҷе…ҘMemStoreж—¶пјҢе®ғиҝҳе°Ҷж•°жҚ®зҡ„еүҜжң¬еҶҷе…ҘHLogж–Ү件гҖӮ е®ҡжңҹж»ҡеҠЁе’ҢеҲ йҷӨHLogж–Ү件пјҢ并еҲ йҷӨж—§ж–Ү件(е·ІдҝқеӯҳеҲ°StoreFileзҡ„ж•°жҚ®)гҖӮ еҪ“HMasterжЈҖжөӢеҲ°HRegionServerиў«Zookeeperж„ҸеӨ–з»Ҳжӯўж—¶пјҢHMasterйҰ–е…ҲеӨ„зҗҶж—§зүҲHLogж–Ү件пјҢеҲҶеүІдёҚеҗҢHRegionзҡ„HLogж•°жҚ®пјҢе°Ҷе®ғ们ж”ҫе…Ҙзӣёеә”зҡ„HRegionзӣ®еҪ•дёӯпјҢ然еҗҺйҮҚж–°еҲҶеҸ‘ж— ж•Ҳзҡ„HRegionгҖӮ еңЁеҠ иҪҪHRegionзҡ„иҝҮзЁӢдёӯпјҢиҝҷдәӣHRegionзҡ„HRegionServerе°ҶеҸ‘зҺ°йңҖиҰҒеӨ„зҗҶHLogзҡ„еҺҶеҸІи®°еҪ•пјҢеӣ жӯӨе°ҶReplay HLogдёӯзҡ„ж•°жҚ®дј иҫ“еҲ°MemStoreпјҢ然еҗҺеҲ·ж–°еҲ°StoreFilesд»Ҙе®ҢжҲҗж•°жҚ®жҒўеӨҚгҖӮ
2.3 ж №е’Ңе…ғ
HBaseзҡ„жүҖжңүHRegionе…ғж•°жҚ®йғҪеӯҳеӮЁеңЁ.METAдёӯгҖӮ иЎЁгҖӮ йҡҸзқҖHRegionзҡ„еўһеҠ пјҢ.METAиЎЁдёӯзҡ„ж•°жҚ®д№ҹеўһеҠ 并еҲҶиЈӮдёәеӨҡдёӘж–°зҡ„HRegionгҖӮ
дёәдәҶжүҫеҲ°.METAиЎЁдёӯжҜҸдёӘHRegionзҡ„дҪҚзҪ®пјҢе°ҶиЎЁдёӯ.METAиЎЁдёӯжүҖжңүHRegionзҡ„е…ғж•°жҚ®еӯҳеӮЁеңЁ-ROOT-tableдёӯпјҢжңҖеҗҺпјҢZookeeperи®°еҪ•ROOTиЎЁзҡ„дҪҚзҪ®дҝЎжҒҜгҖӮ
еңЁжүҖжңүе®ўжҲ·з«Ҝи®ҝй—®з”ЁжҲ·ж•°жҚ®д№ӢеүҚпјҢ他们йңҖиҰҒйҰ–е…Ҳи®ҝй—®Zookeeperд»ҘиҺ·еҸ–-ROOT-зҡ„дҪҚзҪ®пјҢ然еҗҺи®ҝй—®-ROOT-tableд»ҘиҺ·еҸ–.METAиЎЁзҡ„дҪҚзҪ®пјҢжңҖеҗҺж №жҚ®д»ҘдёӢдҝЎжҒҜзЎ®е®ҡз”ЁжҲ·ж•°жҚ®зҡ„дҪҚзҪ®пјҡ METAиЎЁдёӯзҡ„дҝЎжҒҜпјҢеҰӮдёӢжүҖзӨәпјҡиҜҘеӣҫжҳҫзӨәгҖӮ
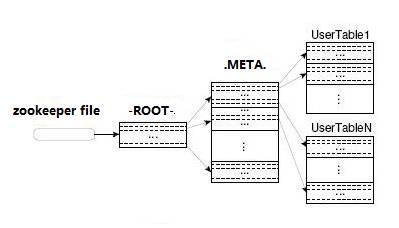
-ROOTиЎЁж°ёиҝңдёҚдјҡжӢҶеҲҶгҖӮ е®ғеҸӘжңүдёҖдёӘHRegionпјҢиҝҷеҸҜд»ҘзЎ®дҝқеҸӘйңҖдёүдёӘи·іиҪ¬е°ұеҸҜд»Ҙе®ҡдҪҚд»»дҪ•HRegionгҖӮ дёәдәҶеҠ еҝ«и®ҝй—®йҖҹеәҰпјҢ.METAиЎЁзҡ„жүҖжңүеҢәеҹҹйғҪдҝқз•ҷеңЁеҶ…еӯҳдёӯгҖӮ
е®ўжҲ·з«Ҝзј“еӯҳжҹҘиҜўзҡ„дҪҚзҪ®дҝЎжҒҜпјҢ并且缓еӯҳдёҚдјҡдё»еҠЁеӨұиҙҘгҖӮ еҰӮжһңе®ўжҲ·з«Ҝд»Қз„¶ж— жі•еҹәдәҺзј“еӯҳзҡ„дҝЎжҒҜи®ҝй—®ж•°жҚ®пјҢеҲҷиҜ·зӣёе…і.METAиЎЁзҡ„RegionжңҚеҠЎеҷЁе°қиҜ•иҺ·еҸ–ж•°жҚ®зҡ„дҪҚзҪ®гҖӮ еҰӮжһңд»Қ然еӨұиҙҘпјҢиҜ·иҜўй—®дёҺ-ROOT-tableе…іиҒ”зҡ„.METAиЎЁеңЁе“ӘйҮҢгҖӮ
жңҖеҗҺпјҢеҰӮжһңе…ҲеүҚзҡ„дҝЎжҒҜе…ЁйғЁж— ж•ҲпјҢеҲҷZookeeperе°ҶHRegionзҡ„ж•°жҚ®йҮҚе®ҡдҪҚгҖӮ еӣ жӯӨпјҢеҰӮжһңе®ўжҲ·з«ҜдёҠзҡ„зј“еӯҳе®Ңе…Ёж— ж•ҲпјҢеҲҷйңҖиҰҒжқҘеӣһе…ӯж¬Ўд»ҘиҺ·еҸ–жӯЈзЎ®зҡ„HRegionгҖӮ
3. HBaseж•°жҚ®жЁЎеһӢ
HBaseжҳҜзұ»дјјдәҺBigTableзҡ„еҲҶеёғејҸж•°жҚ®еә“гҖӮ е®ғжҳҜзЁҖз–Ҹзҡ„й•ҝжңҹеӯҳеӮЁ(еңЁHDFSдёҠ)пјҢеӨҡз»ҙе’ҢжҺ’еәҸзҡ„жҳ е°„иЎЁгҖӮ иҜҘиЎЁзҡ„зҙўеј•жҳҜиЎҢе…ій”®еӯ—пјҢеҲ—е…ій”®еӯ—е’Ңж—¶й—ҙжҲігҖӮ HBaseж•°жҚ®жҳҜеӯ—з¬ҰдёІпјҢжІЎжңүзұ»еһӢгҖӮ

е°ҶиЎЁи§ҶдёәеӨ§еһӢжҳ е°„гҖӮ жӮЁеҸҜд»ҘжҢүиЎҢй”®пјҢиЎҢй”®+ж—¶й—ҙжҲіжҲ–иЎҢй”®+еҲ—(еҲ—ж—ҸпјҡеҲ—дҝ®йҘ°з¬Ұ)жҹҘжүҫзү№е®ҡж•°жҚ®гҖӮ з”ұдәҺHBaseзЁҖз–Ҹең°еӯҳеӮЁж•°жҚ®пјҢеӣ жӯӨжҹҗдәӣеҲ—еҸҜд»Ҙдёәз©әгҖӮ дёҠиЎЁз»ҷеҮәдәҶcom.cnn.wwwзҪ‘з«ҷзҡ„йҖ»иҫ‘еӯҳеӮЁйҖ»иҫ‘и§ҶеӣҫгҖӮ иЎЁдёӯеҸӘжңүдёҖиЎҢж•°жҚ®гҖӮ
иҜҘиЎҢзҡ„е”ҜдёҖж ҮиҜҶз¬ҰжҳҜ" com.cnn.www"пјҢ并且жӯӨж•°жҚ®иЎҢзҡ„жҜҸж¬ЎйҖ»иҫ‘дҝ®ж”№йғҪжңүдёҖе®ҡзҡ„ж—¶й—ҙгҖӮ ж Үи®°еҜ№еә”дәҺгҖӮ
иҜҘиЎЁдёӯжңүеӣӣеҲ—пјҡеҶ…е®№пјҡHTMLпјҢanchorпјҡcnnsi.comпјҢanchorпјҡmy.look.caпјҢmimeпјҡtypeпјҢжҜҸдёӘеҲ—йғҪз»ҷеҮәдәҶе®ғжүҖеұһзҡ„еҲ—ж—ҸгҖӮ
иЎҢй”®(RowKey)жҳҜиЎЁдёӯж•°жҚ®иЎҢзҡ„е”ҜдёҖж ҮиҜҶз¬ҰпјҢ并用дҪңжЈҖзҙўи®°еҪ•зҡ„дё»й”®гҖӮ
еңЁHBaseдёӯпјҢеҸӘжңүдёүз§Қж–№жі•еҸҜд»Ҙи®ҝй—®иЎЁдёӯзҡ„иЎҢпјҡйҖҡиҝҮиЎҢй”®иҝӣиЎҢи®ҝй—®пјҢз»ҷе®ҡиЎҢй”®зҡ„иҢғеӣҙи®ҝй—®д»ҘеҸҠе…ЁиЎЁжү«жҸҸгҖӮ
иЎҢй”®еҸҜд»ҘжҳҜд»»дҪ•еӯ—з¬ҰдёІ(жңҖеӨ§й•ҝеәҰдёә64KB)пјҢ并жҢүеӯ—е…ёйЎәеәҸеӯҳеӮЁгҖӮ еҜ№дәҺз»ҸеёёдёҖиө·иҜ»еҸ–зҡ„иЎҢпјҢйңҖиҰҒд»”з»Ҷи®ҫи®Ўеҹәжң¬еҖјпјҢд»ҘдҫҝеҸҜд»Ҙе°Ҷе®ғ们дёҖиө·еӯҳеӮЁгҖӮ
4. HBaseиҜ»еҶҷиҝҮзЁӢ
дёӢеӣҫжҳҜHRegionServerж•°жҚ®еӯҳеӮЁе…ізі»еӣҫгҖӮ еҰӮдёҠжүҖиҝ°пјҢHBaseдҪҝз”ЁMemStoreе’ҢStoreFileе°Ҷжӣҙж–°еӯҳеӮЁеҲ°иЎЁдёӯгҖӮ ж•°жҚ®еңЁжӣҙж–°еҗҺйҰ–е…ҲеҶҷе…ҘHLogе’ҢMemStoreгҖӮ MemStoreдёӯзҡ„ж•°жҚ®е·ІжҺ’еәҸгҖӮ
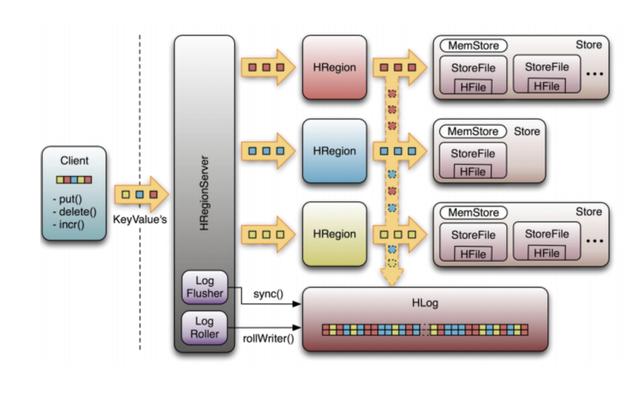
еҪ“MemStoreзҙҜз§ҜеҲ°жҹҗдёӘйҳҲеҖјж—¶пјҢе°ҶеҲӣе»әдёҖдёӘж–°зҡ„MemStoreпјҢ并е°Ҷж—§зҡ„MemStoreж·»еҠ еҲ°FlushйҳҹеҲ—дёӯпјҢ并е°ҶдёҖдёӘеҚ•зӢ¬зҡ„зәҝзЁӢеҲ·ж–°еҲ°зЈҒзӣҳдёҠд»ҘжҲҗдёәStoreFileгҖӮ еҗҢж—¶пјҢзі»з»ҹе°ҶеңЁZookeeperдёӯи®°еҪ•дёҖдёӘCheckPointпјҢиЎЁжҳҺиҜҘж—¶й—ҙд№ӢеүҚзҡ„ж•°жҚ®жӣҙж”№е·Ідҝқз•ҷгҖӮ еҪ“еҸ‘з”ҹж„ҸеӨ–зі»з»ҹж—¶пјҢMemStoreдёӯзҡ„ж•°жҚ®еҸҜиғҪдјҡдёўеӨұгҖӮ
еңЁиҝҷз§Қжғ…еҶөдёӢпјҢHLogз”ЁдәҺеңЁCheckPointд№ӢеҗҺжҒўеӨҚж•°жҚ®гҖӮ
StoreFileжҳҜеҸӘиҜ»зҡ„пјҢдёҖж—ҰеҲӣе»әдҫҝж— жі•дҝ®ж”№гҖӮ еӣ жӯӨпјҢHBaseзҡ„жӣҙж–°жҳҜдёҖйЎ№йҷ„еҠ ж“ҚдҪңгҖӮ еҪ“е•Ҷеә—дёӯзҡ„StoreFileиҫҫеҲ°жҹҗдёӘйҳҲеҖјж—¶пјҢе°Ҷжү§иЎҢеҗҲ并ж“ҚдҪңпјҢ并且е°ҶзӣёеҗҢеҜҶй’Ҙзҡ„дҝ®ж”№еҗҲ并д»ҘеҪўжҲҗдёҖдёӘеӨ§еһӢStoreFileгҖӮ еҪ“StoreFileзҡ„еӨ§е°ҸиҫҫеҲ°жҹҗдёӘйҳҲеҖјж—¶пјҢStoreFileиў«жӢҶеҲҶ并еҲҶдёәдёӨдёӘStoreFilesгҖӮ
4.1еҶҷж“ҚдҪңжөҒзЁӢ
жӯҘйӘӨ1пјҡе®ўжҲ·з«ҜйҖҡиҝҮZookeeperзҡ„и°ғеәҰеҗ‘HRegionServerеҸ‘йҖҒеҶҷж•°жҚ®иҜ·жұӮпјҢ并е°Ҷж•°жҚ®еҶҷе…ҘHRegionгҖӮ
жӯҘйӘӨ2пјҡе°Ҷж•°жҚ®еҶҷе…ҘHRegionзҡ„MemStoreпјҢзӣҙеҲ°MemStoreиҫҫеҲ°йў„и®ҫйҳҲеҖјгҖӮ
жӯҘйӘӨ3пјҡMemStoreдёӯзҡ„ж•°жҚ®иў«ж•ҙзҗҶеҲ°StoreFileдёӯгҖӮ
жӯҘйӘӨ4пјҡйҡҸзқҖStoreFileж–Ү件数йҮҸзҡ„еўһеҠ пјҢеҪ“StoreFileж–Ү件数йҮҸеўһеҠ еҲ°зү№е®ҡйҳҲеҖјж—¶пјҢе°Ҷжү§иЎҢCompactеҗҲ并ж“ҚдҪңпјҢ并е°ҶеӨҡдёӘStoreFilesеҗҲ并еҲ°дёҖдёӘStoreFileдёӯпјҢ并еңЁзүҲжң¬еә“дёӯжү§иЎҢзүҲжң¬еҗҲ并е’Ңж•°жҚ®еҲ йҷӨгҖӮ еҗҢж—¶гҖӮ
жӯҘйӘӨ5пјҡStoreFilesйҖҡиҝҮиҝһз»ӯзҡ„Compactж“ҚдҪңйҖҗжёҗеҪўжҲҗи¶ҠжқҘи¶ҠеӨ§зҡ„StoreFileгҖӮ
жӯҘйӘӨ6пјҡеңЁеҚ•дёӘStoreFileзҡ„еӨ§е°Ҹи¶…иҝҮжҹҗдёӘйҳҲеҖјд№ӢеҗҺпјҢе°Ҷи§ҰеҸ‘Splitж“ҚдҪңпјҢе°ҶеҪ“еүҚзҡ„HRegionжӢҶеҲҶдёәдёӨдёӘж–°зҡ„HRegionгҖӮ зҲ¶HRegionе°Ҷи„ұжңәпјҢж–°зҡ„Splitзҡ„дёӨдёӘеӯҗHRegionе°Ҷз”ұHMasterеҲҶй…Қз»ҷзӣёеә”зҡ„HRegionServerпјҢд»ҘдҫҝеҸҜд»Ҙе°ҶеҺҹе§ӢHRegionзҡ„еҺӢеҠӣеҲҶжөҒеҲ°иҝҷдёӨдёӘHRegionгҖӮ
4.2иҜ»еҸ–ж“ҚдҪңжөҒзЁӢ
жӯҘйӘӨ1пјҡе®ўжҲ·з«Ҝи®ҝй—®ZookeeperпјҢжүҫеҲ°-ROOT-tableпјҢ并иҺ·еҫ—.METAгҖӮ иЎЁдҝЎжҒҜгҖӮ
жӯҘйӘӨ2пјҡд»Һ.METAдёӯжҗңзҙўгҖӮ иЎЁиҺ·еҸ–зӣ®ж Үж•°жҚ®зҡ„HRegionдҝЎжҒҜпјҢжүҫеҲ°еҜ№еә”зҡ„HRegionServerгҖӮ
жӯҘйӘӨ3пјҡиҺ·еҸ–йңҖиҰҒйҖҡиҝҮHRegionServerжҹҘжүҫзҡ„ж•°жҚ®гҖӮ
жӯҘйӘӨ4пјҡHRegionserverзҡ„еҶ…еӯҳеҲҶдёәдёӨйғЁеҲҶпјҡMemStoreе’ҢBlockCacheгҖӮ MemStoreдё»иҰҒз”ЁдәҺеҶҷе…Ҙж•°жҚ®пјҢиҖҢBlockCacheдё»иҰҒз”ЁдәҺиҜ»еҸ–ж•°жҚ®гҖӮ йҰ–е…Ҳе°ҶиҜ·жұӮиҜ»еҸ–еҲ°MemStoreд»ҘжЈҖжҹҘж•°жҚ®пјҢжЈҖжҹҘBlockCacheжЈҖжҹҘпјҢ然еҗҺжЈҖжҹҘStoreFileпјҢ然еҗҺе°ҶиҜ»еҸ–з»“жһңж”ҫе…ҘBlockCacheгҖӮ
5. HBaseдҪҝз”ЁеңәжҷҜ
еҚҠз»“жһ„еҢ–жҲ–йқһз»“жһ„еҢ–ж•°жҚ®пјҡеҜ№дәҺжІЎжңүеҫҲеҘҪе®ҡд№үжҲ–ж··д№ұзҡ„ж•°жҚ®з»“жһ„еӯ—ж®өпјҢеҫҲйҡҫж №жҚ®йҖӮз”ЁдәҺHBaseзҡ„жҰӮеҝөжқҘжҸҗеҸ–ж•°жҚ®гҖӮ еҰӮжһңйҡҸзқҖдёҡеҠЎеўһй•ҝеӯҳеӮЁжӣҙеӨҡеӯ—ж®өпјҢеҲҷйңҖиҰҒе…ій—ӯRDBMSжқҘз»ҙжҠӨжӣҙж”№иЎЁз»“жһ„пјҢ并且HBaseж”ҜжҢҒеҠЁжҖҒж·»еҠ гҖӮ
и®°еҪ•йқһеёёзЁҖз–ҸпјҡRDBMSиЎҢзҡ„еӨҡе°‘еҲ—жҳҜеӣәе®ҡзҡ„пјҢиҖҢз©әеҲ—еҲҷжөӘиҙ№еӯҳеӮЁз©әй—ҙгҖӮ HBaseдёәз©әзҡ„еҲ—дёҚдјҡеӯҳеӮЁпјҢиҝҷж ·еҸҜд»ҘиҠӮзңҒз©әй—ҙ并жҸҗй«ҳиҜ»еҸ–жҖ§иғҪгҖӮ
еӨҡзүҲжң¬ж•°жҚ®пјҡж №жҚ®RowKeyе’ҢеҲ—ж ҮиҜҶз¬Ұе®ҡдҪҚзҡ„еҖјеҸҜд»Ҙе…·жңүд»»ж„Ҹж•°йҮҸзҡ„зүҲжң¬еҖј(ж—¶й—ҙжҲіжҳҜдёҚеҗҢзҡ„)пјҢеӣ жӯӨе°ҶHBaseз”ЁдәҺйңҖиҰҒеӯҳеӮЁжӣҙж”№еҺҶеҸІи®°еҪ•зҡ„ж•°жҚ®йқһеёёж–№дҫҝ гҖӮ
еӨ§йҮҸж•°жҚ®пјҡеҪ“ж•°жҚ®йҮҸи¶ҠжқҘи¶ҠеӨ§ж—¶пјҢRDBMSж•°жҚ®еә“е°Ҷж— жі•жүҝеҸ—пјҢ并且еӯҳеңЁиҜ»еҶҷеҲҶзҰ»зӯ–з•ҘгҖӮ йҖҡиҝҮдёҖдёӘдё»жңәпјҢе®ғиҙҹиҙЈеҶҷж“ҚдҪңпјҢиҖҢеӨҡдёӘд»ҺжңәеҲҷиҙҹиҙЈиҜ»еҸ–ж“ҚдҪңпјҢжңҚеҠЎеҷЁжҲҗжң¬еўһеҠ дәҶдёҖеҖҚгҖӮ йҡҸзқҖеҺӢеҠӣзҡ„еўһеҠ пјҢиҲ№й•ҝж— жі•жүҝеҸ—еҺӢеҠӣгҖӮ жӯӨж—¶пјҢе°ҶеҜ№еә“иҝӣиЎҢеҲ’еҲҶпјҢ并且е°ҶеҮ д№ҺдёҚзӣёе…ізҡ„ж•°жҚ®еҲҶеҲ«йғЁзҪІгҖӮ жҹҗдәӣиҒ”жҺҘжҹҘиҜўж— жі•дҪҝз”ЁпјҢ并且йңҖиҰҒдҪҝз”Ёдёӯй—ҙеұӮгҖӮ йҡҸзқҖж•°жҚ®йҮҸзҡ„иҝӣдёҖжӯҘеўһеҠ пјҢиЎЁзҡ„и®°еҪ•еҸҳеҫ—и¶ҠжқҘи¶ҠеӨ§пјҢжҹҘиҜўеҸҳеҫ—йқһеёёж…ўгҖӮ
еӣ жӯӨпјҢжңүеҝ…иҰҒдҫӢеҰӮйҖҡиҝҮеҜ№IDиҝӣиЎҢжЁЎеҢ–е°ҶиЎЁеҲ’еҲҶдёәеӨҡдёӘиЎЁпјҢд»ҘеҮҸе°‘еҚ•дёӘиЎЁзҡ„и®°еҪ•ж•°гҖӮ з»ҸеҺҶиҝҮиҝҷдәӣдәӢжғ…зҡ„дәәйғҪзҹҘйҒ“еҰӮдҪ•жҠӣејғиҝҷдёӘиҝҮзЁӢгҖӮ
HBaseеҫҲз®ҖеҚ•пјҢеҸӘйңҖе°Ҷж–°иҠӮзӮ№ж·»еҠ еҲ°зҫӨйӣҶпјҢHBaseе°ұдјҡиҮӘеҠЁж°ҙе№іжӢҶеҲҶпјҢ并且дёҺHadoopзҡ„ж— зјқйӣҶжҲҗеҸҜзЎ®дҝқж•°жҚ®еҸҜйқ жҖ§(HDFS)е’Ңй«ҳжҖ§иғҪзҡ„жө·йҮҸж•°жҚ®еҲҶжһҗ(MapReduce)гҖӮ
6. HBase Map Reduce
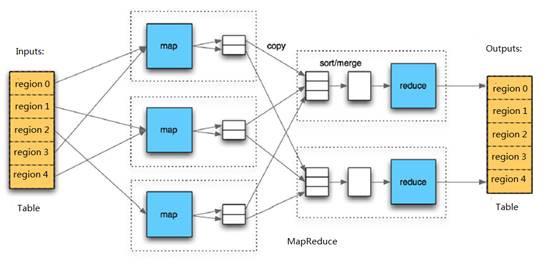
HBaseдёӯзҡ„TableдёҺRegionд№Ӣй—ҙзҡ„е…ізі»дёҺHDFSдёӯзҡ„FileдёҺBlockд№Ӣй—ҙзҡ„е…ізі»жңүдәӣзӣёдјјгҖӮ з”ұдәҺHBaseжҸҗдҫӣдәҶдёҺMapReduceиҝӣиЎҢдәӨдә’зҡ„APIпјҢдҫӢеҰӮTableInputFormatе’ҢTableOutputFormatпјҢеӣ жӯӨHBaseж•°жҚ®иЎЁеҸҜд»ҘзӣҙжҺҘз”ЁдҪңHadoop MapReduceзҡ„иҫ“е…Ҙе’Ңиҫ“еҮәпјҢиҝҷжңүеҲ©дәҺMapReduceеә”з”ЁзЁӢеәҸзҡ„ејҖеҸ‘пјҢ并且дёҚйңҖиҰҒжіЁж„ҸHBaseзҡ„еӨ„зҗҶгҖӮ зі»з»ҹжң¬иә«зҡ„иҜҰз»ҶдҝЎжҒҜгҖӮ
вҖңHBaseзҡ„е·ҘдҪңеҺҹзҗҶвҖқзҡ„еҶ…е®№е°ұд»Ӣз»ҚеҲ°иҝҷйҮҢдәҶпјҢж„ҹи°ўеӨ§е®¶зҡ„йҳ…иҜ»гҖӮеҰӮжһңжғідәҶи§ЈжӣҙеӨҡиЎҢдёҡзӣёе…ізҡ„зҹҘиҜҶеҸҜд»Ҙе…іжіЁдәҝйҖҹдә‘зҪ‘з«ҷпјҢе°Ҹзј–е°ҶдёәеӨ§е®¶иҫ“еҮәжӣҙеӨҡй«ҳиҙЁйҮҸзҡ„е®һз”Ёж–Үз« пјҒ





