这篇文章主要介绍“如何实现Base64与Base32”,在日常操作中,相信很多人在如何实现Base64与Base32问题上存在疑惑,小编查阅了各式资料,整理出简单好用的操作方法,希望对大家解答”如何实现Base64与Base32”的疑惑有所帮助!接下来,请跟着小编一起来学习吧!
要写Base32,就要先理解Base64,那么Base64是干什么用的呢?为什么要有Base64呢?这个是根本原因,把Base64产生的过程搞清楚了,那么Base32,我们就可以依葫芦画瓢了。
我们知道在计算机中,数据的单位是字节byte,它是由8位2进制组成的,总共可以有256个不同的数。那么这些二进制的数据要怎么进行传输呢?我们要将其转化为ASCII字符,ASCII字符中包含了33个控制字符(不可见)和95个可见字符,我们如果能将这些二进制的数据转化成这95个可见字符,就可以正常传输了。于是,我们从95个字符中,挑选了64个,将2进制的数据转化为这个64个可见字符,这样就可以正常的传输了,这就是Base64的由来。那这64个字符是什么呢?
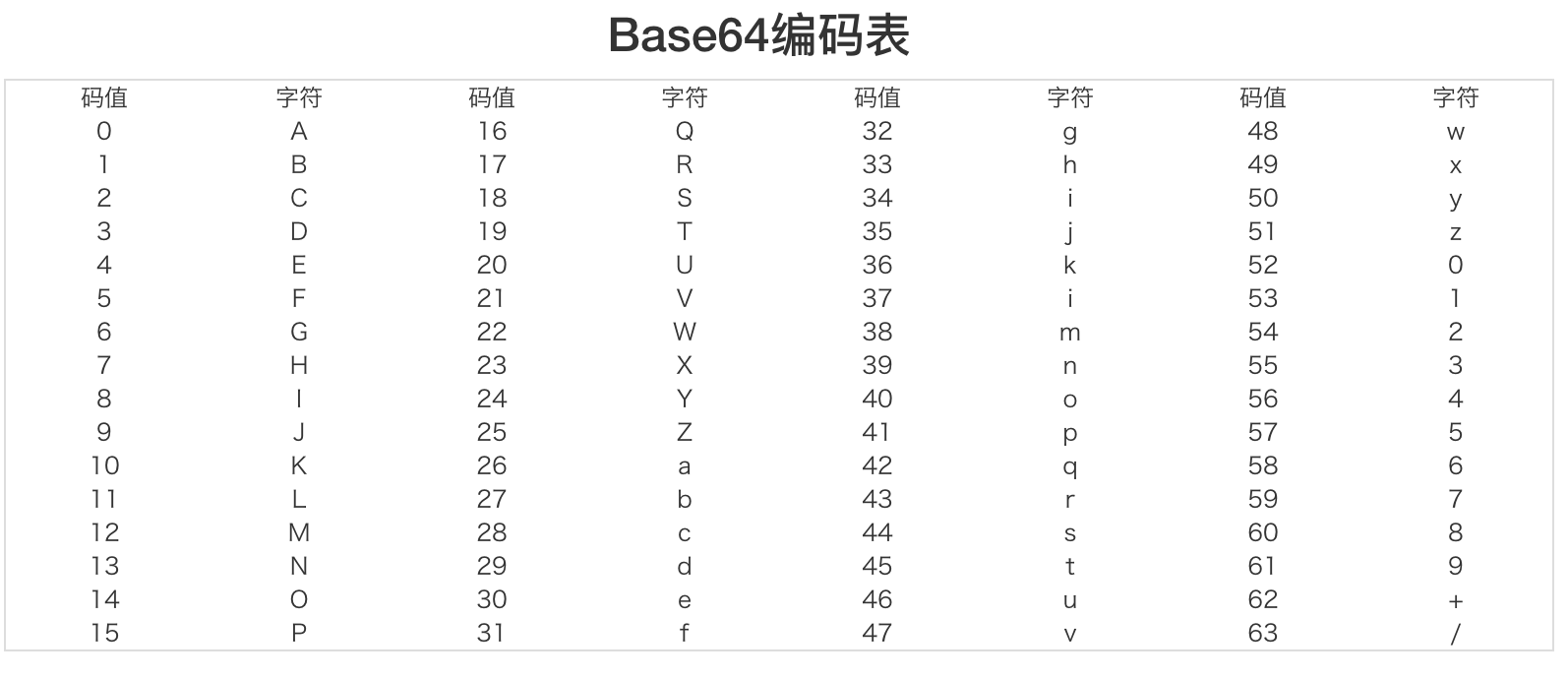
这就是Base64的那64个字符。那么如果我们要实现Base32呢?对了,我们要挑选出32个可见字符,具体如下:
private static final char[] toBase32 = {
'A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J', 'K', 'L', 'M',
'N', 'O', 'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X', 'Y', 'Z',
'0', '1', '2', '3', '4', '5'
};我们挑选了大写的A-Z,再加上0-5,一共32个可见字符。
好了,32个可见字符已经选好了,接下来就是将2进制转化成这32个字符的过程。我们先来看一下Base64是一个什么样的转化过程,我们一个字节是8位,而64是2的6次方,也即是一个字节(8位)的数据,我们要截取其中的6位进行编码,取到其可见字符。那么剩余的2位数怎么办呢?它将和下一个自己的前4位组成一个6位的数据进行编码。那么我们需要多少字节才能得到一个完整的不丢位的编码呢?我们要取6和8的最小公倍数,也就是24,24位恰好是3个字节,如果取6位进行编码,则可以取到4个编码。我们看看下面的图就可以更好地理解了,

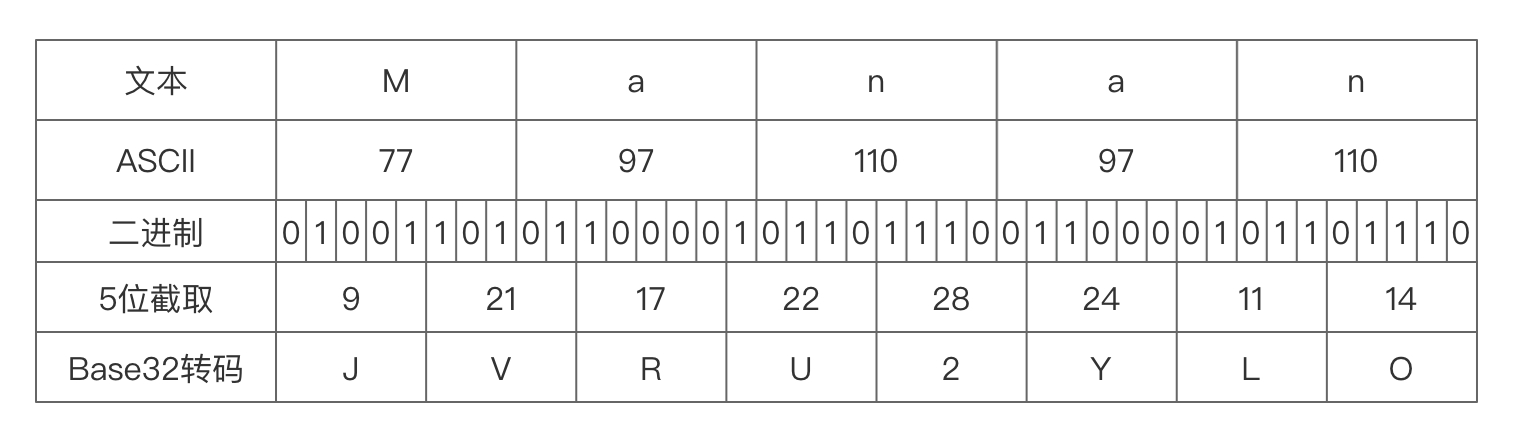
M,a,n对应的ASCII码分别是77,97,110。
对应的二进制是01001101,01100001,01101110。
然后我们按照6位截取,恰好能够截取4个编码,对应的6位二进制分别为:010011,010110,000101,101110。
对应的64位编码为:T,W,F,u。
同理,如果我们要实现Base32怎么办呢?32是2的5次方,那么我们再进行2进制截位时,要一次截取5位。那么一个字节8位,截取了5位,剩下的3位怎么办?同理和下一个字节的前2位组成一个新的5位。那么多少个字节按照5位截取才能不丢位呢?我们要取5和8的最小公倍数,40位,按照5位截取,正好得到8个编码。40位,正好5个字节,所以我们要5个字节分为一组,进行Base32的编码。如下图:
对比前面的Base64,Base32就是按照5位去截取,然后去编码表中找到对应的字符。好了,原理我们明白了,下面进入程序阶段。
原理明白了,程序怎么写呢?这也就是程序猿的价值所在,把现实中的规则、功能、逻辑用程序把它实现。但是实现Base32也是比较难的,不过有先人给我们留下了Base64,我们参照Base64去实现Base32就容易多了。
首先,我们要根据输入字节的长度,确定返回字节的长度,以上面为例,输入字节的长度是5,那么Base32转码后的字节长度就是8。那么如果输入字节的长度是1,返回结果的字节长度是多少呢?这就需要补位了,也就是说输入字节的长度不是5的倍数,我们要进行补位,将其长度补成5的倍数,这样编码以后,返回字节的长度就是8的倍数。这样做,我们不会丢失信息,比如,我们只输入了一个字节,是8位,编码时,截取了前5位,那么剩下的后3位怎么办?不能舍弃吧,我们要在其后面补足40位,补位用0去补,前面截取有剩余的位数再加上后面补位的0,凑成5位,再去编码。其余的,全是0的5位二进制,我们编码成“=”,这个和Base64是一样的。
好了,我们先来看看编码后返回字节的长度怎么计算。
//返回结果的数组长度 int rLength = 8 * ((src.length + 4) / 5); //返回结果 byte[] result = new byte[rLength];
其中src是输入的字节数组;
返回长度的公式我们要仔细看一下,对5取整,再乘以8,这是一个最基本的操作,我们用上面的例子套一下,输入字节的长度是5个字节,8*(5/5) = 8,需要返回8个字节。我们再来看看加4的作用,比如我们输入的是1个字节,那么返回几个字节呢?按照前面的要求,如果二进制长度不满40位,要补满40位,也就是输入字节的长度要补满成5的整数倍。这里先加4再对5取整,就可以补位后可以进行完整编码的个数,然后再乘以8,得到返回的字节数。大家可以随便想几个例子,验证一下结果对不对。
然后我们定义返回结果的数组。
返回结果的数组长度已经确定了,接下来我们做什么呢?当然是编码的工作了,这里我们分为两个步骤:
先处理可以正常进行编码的那些字节,也就是满足5的倍数的那些字节,这些字节可以进行5字节到8字节转换的,不需要进行补位。
然后处理最后几位,这些是需要补位的,将其补成5个字节。
编码的步骤已经确定了,下面要确定可以正常编码的字节长度,以及需要补位的长度,如下:
//正常转换的长度 int normalLength = src.length / 5 * 5; //补位长度 int fillLength = (5 - (src.length % 5)) % 5;
又是两个计算公式,我们分别看一下:
可以正常编码的字节长度,对5取整,再乘以5,过滤掉最后不满足5的倍数的字节,这些过滤掉的字节需要补位,满足5个字节;
这一步就是计算最后需要补几位才能满足5的倍数,最后可以得到需要补位的长度,如果输入字节的长度恰好是5的倍数,不需要补位,则计算的结果是0,大家可以验证一下这两个公式。
接下来,我们处理一下可以正常编码的字节,如下:
//输入字节下标
int srcPos = 0;
//返回结果下标
int resultPos = 0;
while (srcPos < normalLength) {
long bits = ((long)(src[srcPos++] & 0xff)) << 32 |
(src[srcPos++] & 0xff) << 24 |
(src[srcPos++] & 0xff) << 16 |
(src[srcPos++] & 0xff) << 8 |
(src[srcPos++] & 0xff);
result[resultPos++] = (byte) toBase32[(int)((bits >> 35) & 0x1f)];
result[resultPos++] = (byte) toBase32[(int)((bits >> 30) & 0x1f)];
result[resultPos++] = (byte) toBase32[(int)((bits >> 25) & 0x1f)];
result[resultPos++] = (byte) toBase32[(int)((bits >> 20) & 0x1f)];
result[resultPos++] = (byte) toBase32[(int)((bits >> 15) & 0x1f)];
result[resultPos++] = (byte) toBase32[(int)((bits >> 10) & 0x1f)];
result[resultPos++] = (byte) toBase32[(int)((bits >> 5) & 0x1f)];
result[resultPos++] = (byte) toBase32[(int)(bits & 0x1f)];
}我们先定义输入字节的下标和返回结果的下标,用作取值与赋值;
再写个while循环,只要输入的字节下标在正常转换的范围内,就可以正常的编码;
接下来看看while循环的处理细节,我们先要将5个字节拼成一个40位的二进制,在程序中,我们通过位移运算和 | 或运算得到一个long型的数字,当然它的二进制就是我们用5个字节拼成的。
这里有个坑要和大家说明一下,我们第一个字节位移的时候用long转型了,为什么?因为int型在Java中占4个字节,32位,我们左移32位后,它会回到最右侧的位置。而long占64位,我们左移32位是不会循环的。这一点大家要格外注意。
接下来就是将这40位的二进制进行分拆,同样通过位移操作,每次从左侧截取5位,我们分别向右移动35、30、25、20、15、10、5、0,然后将其和0x1f进行与操作,0x1f是一个16进制的数,其二进制是0001 1111,对了,就是5个1,移位后和0x1f进行与操作,只留取最右侧的5位二进制,并计算其数值,然后从32位编码表中找到对应的字符。
可以正常编码的部分就正常结束了,大家要多多理解位移符号的运用。接下来,我们再看看结尾字节的处理。先上代码:
if (fillLength > 0) {
switch (fillLength) {
case 1:
int normalBits1 = (src[srcPos] & 0xff) << 24 |
(src[srcPos+1] & 0xff) << 16 |
(src[srcPos+2] & 0xff) << 8 |
(src[srcPos+3] & 0xff);
result[resultPos++] = (byte) toBase32[(normalBits1 >> 27) & 0x1f];
result[resultPos++] = (byte) toBase32[(normalBits1 >> 22) & 0x1f];
result[resultPos++] = (byte) toBase32[(normalBits1 >> 17) & 0x1f];
result[resultPos++] = (byte) toBase32[(normalBits1 >> 12) & 0x1f];
result[resultPos++] = (byte) toBase32[(normalBits1 >> 7) & 0x1f];
result[resultPos++] = (byte) toBase32[(normalBits1 >> 2) & 0x1f];
result[resultPos++] = (byte) toBase32[(normalBits1 << 3) & 0x1f];
result[resultPos++] = '=';
break;
case 2:
int normalBits2 = (src[srcPos] & 0xff) << 16 |
(src[srcPos+1] & 0xff) << 8 |
(src[srcPos+2] & 0xff);
result[resultPos++] = (byte) toBase32[(normalBits2 >> 19) & 0x1f];
result[resultPos++] = (byte) toBase32[(normalBits2 >> 14) & 0x1f];
result[resultPos++] = (byte) toBase32[(normalBits2 >> 9) & 0x1f];
result[resultPos++] = (byte) toBase32[(normalBits2 >> 4) & 0x1f];
result[resultPos++] = (byte) toBase32[(normalBits2 << 1) & 0x1f];
result[resultPos++] = '=';
result[resultPos++] = '=';
result[resultPos++] = '=';
break;
case 3:
int normalBits3 = (src[srcPos] & 0xff) << 8 |
(src[srcPos+1] & 0xff);
result[resultPos++] = (byte) toBase32[(normalBits3 >> 11) & 0x1f];
result[resultPos++] = (byte) toBase32[(normalBits3 >> 6) & 0x1f];
result[resultPos++] = (byte) toBase32[(normalBits3 >> 1) & 0x1f];
result[resultPos++] = (byte) toBase32[(normalBits3 << 4) & 0x1f];
result[resultPos++] = '=';
result[resultPos++] = '=';
result[resultPos++] = '=';
result[resultPos++] = '=';
break;
case 4:
int normalBits4 = (src[srcPos] & 0xff) ;
result[resultPos++] = (byte) toBase32[(normalBits4 >> 3) & 0x1f];
result[resultPos++] = (byte) toBase32[(normalBits4 << 2) & 0x1f];
result[resultPos++] = '=';
result[resultPos++] = '=';
result[resultPos++] = '=';
result[resultPos++] = '=';
result[resultPos++] = '=';
result[resultPos++] = '=';
break;
}
}fillLength就是需要补位的位数,如果等于0,我们就不需要补位了。大于0就需要进行补位。
需要补位的情况,我们分为4种,分别为:补1位、补2位、补3位和补4位。
我嗯先看看补1位的情况,需要补1位,说明之前剩下4个字节,我们先将这4个字节拼起来,那么第一个字节要向左移动24位,这个和正常情况下第一个字节向左移动的位数是不一样的。剩余的字节分别向左移动相应的位数,大家可以参照程序计算一下。
然后将得到的32位二进制数,从最高位每次截取5位,每次向右移动位数分别为27、22、17、12、7、2,注意,最后剩下2位,不足5位,我们要向左移动3位。移位后要和0x1f进行与操作,这个作用和前面是一样的,这里不赘述了。然后将得到的数字在32位编码表中,去除对应的字符。
剩下的位数我们统一使用=进行补位。
其他的需要补1位、补2位和补3位的情况,我们重复步骤3-步骤5,里边具体的移动位数有所区别,需要大家仔细计算。
整个的编码过程到这里就结束了,我们将result数组返回即可。
到此,关于“如何实现Base64与Base32”的学习就结束了,希望能够解决大家的疑惑。理论与实践的搭配能更好的帮助大家学习,快去试试吧!若想继续学习更多相关知识,请继续关注亿速云网站,小编会继续努力为大家带来更多实用的文章!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





