这期内容当中小编将会给大家带来有关ES集群故障的问题追踪与解决方案是什么,文章内容丰富且以专业的角度为大家分析和叙述,阅读完这篇文章希望大家可以有所收获。
1、很久前的历史问题了,来记录下。问题原因是某2个索引发生了写故障,开始是怀疑某台机器硬盘导致的。这种情况的影响是集群状态变red,部分记录无法被搜索到。诡异的是其中一个索引出现故障后自动恢复了,而另外一个索引却无法自动回复。
2、话不多说,日志是反映问题的第一现场。

以上日志可以看出该索引的副本3出现了故障,且是write bulk的写故障。由于ES的写操作会先写主分片,然后主分片再将操作同步到副本分片,再等待副本并发操作完再返回客户端。故查看ES副本执行操作时的源码,发现日志返回的报错信息恰好就在副本操作发生异常时回调的onFailure方法中,里边再调用了failShardIfNeeded方法,failShardIfNeeded方法又调用了decPendingAndFinishIfNeeded onPrimaryDemoted这两个方法,通过查找资料对比源码发现:
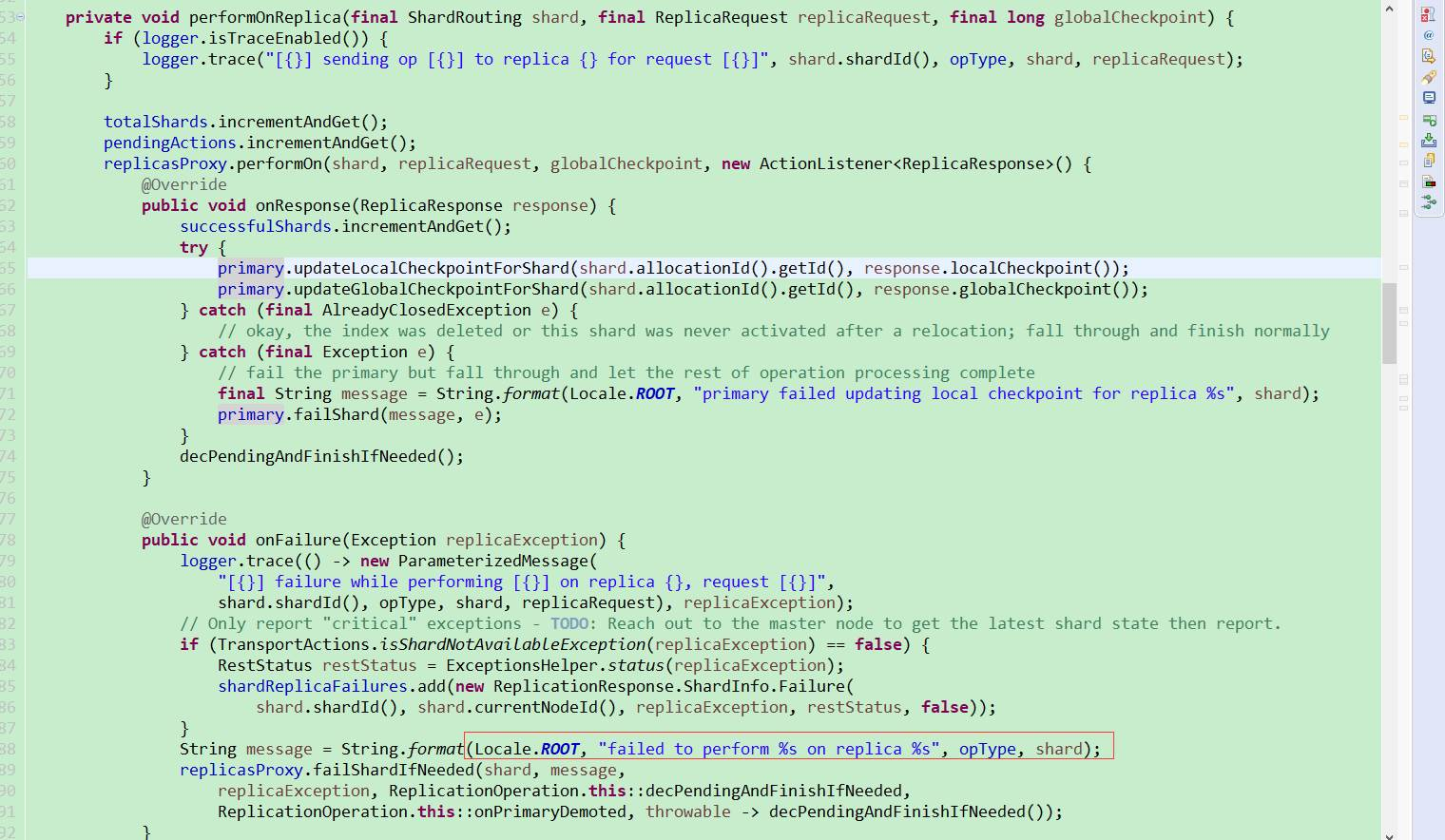
decPendingAndFinishIfNeeded 是当所有的分片都处理完这个请求后,不管是查询失败还是成功、超时,每执行一次,都会总查询的总分片数减1,直到所有分片都返回了,再调用finish()方法响应客户端:

onPrimaryDemoted是写操作首先在主分片执行成功,然后同步到副本,但是副本发现它的主分片 的 primary term 比它知道的该索引的primary term 还小,term因为是写的请求总是分发到主分片,所以每次更新主分片,term都会加1,在主向副发送同步数据的请求时候会带上这个term值(感觉应该是为了保证数据一致性)。当主带过来的term值对比之前带过来的还要小,那证明这个主分片处于一种不正常的状态。于是副本就认为这个主分片是一个已经过时了的主分片,因此就回调onFailure方法拒绝执行,并执行onPrimaryDemoted通知master节点,master节点会检测该主分片是否真的异常,真的过时会在索引Meta信息中更新配置,将该副本分片移除(集群中经常体现的就是unsigned了)。

查看异常日志,发现确实出现了方法中打印的异常日志,且对比term值确实发现主分片异常:

3、开篇提到了,因为是同时有2个索引发生了故障,所以怀疑是机器本身的原因。但是按理说,剔除了副本就好了,但是为什么一个索引的主分片故障后自动分配,并从translog恢复数据变为健康状态了,另一个索引的主分片却无法自动恢复分配呢?原因是ES移除shard后有一个故障恢复时间,当故障超过一定时间,ES会分配一个新的shard到新node上,此时需要全量同步数据。但是如果之前故障的shard回来了,就可以只回补故障之后的数据,追平后加回来即可,实现快速故障恢复。联合之前的经验,确实有这种故障后恢复是需要从重新从主分片拷贝一份,完了后再删除原来那个副本的情况。且日志里面也有体现timeout了:

4、解决方案综合以上分析,此时不能直接恢复,执行命令让ES重试分配,从原来的shard中恢复,如果是手动分配自动复制的话,会有挤爆硬盘的风险:POST /_cluster/reroute?retry_failed=true
5、总结至此看到了这次故障的大概原因,但是为什么会引发这样的故障还是没有头绪,更深层次的原理还是需要努力一层一层往深了挖,阅读源码,万法不离其宗,es也只是一个java应用。
上述就是小编为大家分享的ES集群故障的问题追踪与解决方案是什么了,如果刚好有类似的疑惑,不妨参照上述分析进行理解。如果想知道更多相关知识,欢迎关注亿速云行业资讯频道。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/u/3152157/blog/4674035



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



