python中怎么利用jieba模块提取关键词,相信很多没有经验的人对此束手无策,为此本文总结了问题出现的原因和解决方法,通过这篇文章希望你能解决这个问题。
1.读取一个用户的全部数据时,注意区分read(), readline()和readlines()的区别,read()读取文件全部内容并存在一个字符串变量中,readline()每次只读取文件里面的一行,readlines()返回一个行的列表。
2.注意将一个列表以字符串表达的写法:','.join(list).例如:list = [1,2,3],则可输出1,2,3
代码如下:
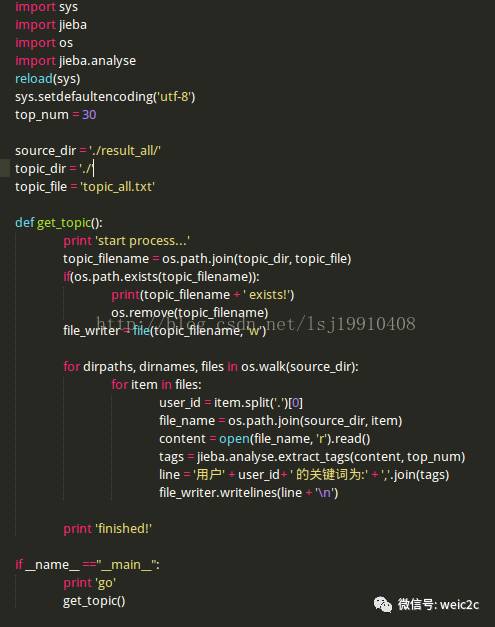
文本分析--关键词获取(jieba分词器,TF-IDF模型)
关键词获取可以通过两种方式来获取:
1、在使用jieba分词对文本进行处理之后,可以通过统计词频来获取关键词:jieba.analyse.extract_tags(news, topK=10),获取词频在前10的作为关键词。
2、使用TF-IDF权重来进行关键词获取,首先需要对文本构建词频矩阵,其次才能使用向量求TF-IDF值。
# -*-coding:utf-8-*-import uniout # 编码格式,解决中文输出乱码问题import jieba.analysefrom sklearn import feature_extractionfrom sklearn.feature_extraction.text import TfidfTransformerfrom sklearn.feature_extraction.text import CountVectorizer""" TF-IDF权重: 1、CountVectorizer 构建词频矩阵 2、TfidfTransformer 构建tfidf权值计算 3、文本的关键字 4、对应的tfidf矩阵"""# 读取文件def read_news(): news = open('news.txt').read() return news# jieba分词器通过词频获取关键词def jieba_keywords(news): keywords = jieba.analyse.extract_tags(news, topK=10) print keywordsdef tfidf_keywords(): # 00、读取文件,一行就是一个文档,将所有文档输出到一个list中 corpus = [] for line in open('news.txt', 'r').readlines(): corpus.append(line) # 01、构建词频矩阵,将文本中的词语转换成词频矩阵 vectorizer = CountVectorizer() # a[i][j]:表示j词在第i个文本中的词频 X = vectorizer.fit_transform(corpus) print X # 词频矩阵 # 02、构建TFIDF权值 transformer = TfidfTransformer() # 计算tfidf值 tfidf = transformer.fit_transform(X) # 03、获取词袋模型中的关键词 word = vectorizer.get_feature_names() # tfidf矩阵 weight = tfidf.toarray() # 打印特征文本 print len(word) for j in range(len(word)): print word[j] # 打印权重 for i in range(len(weight)): for j in range(len(word)): print weight[i][j] # print '\n'if __name__ == '__main__': news = read_news() jieba_keywords(news) tfidf_keywords() 看完上述内容,你们掌握python中怎么利用jieba模块提取关键词的方法了吗?如果还想学到更多技能或想了解更多相关内容,欢迎关注亿速云行业资讯频道,感谢各位的阅读!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/u/4585416/blog/4627606



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



