这篇文章给大家分享的是有关Spyfari怎么用的内容。小编觉得挺实用的,因此分享给大家做个参考,一起跟随小编过来看看吧。
Spyfari
用javascrip编写爬虫规则,
可视化的爬虫软件。
我拿它,对著名的p站爬取了一些数据,
在这里我们先回顾下爬虫爬取数据的步骤:
1、通过浏览器查看网站结构,提取出需要获取数据所在的标签,这里跟各种element的节点打交道,需要解释网页标签,用到类选择、id选择、父节点、子节点、正则表达式等等。如果是用python有相应的库,比如BeautifulSoup;
2、处理自动登录,验证码等。
3、获取到数据,或者url,数据存入本地或者数据库
4、根据url再次爬取其他数据,或者根据url下载文件(包括图片、视频、文本、网页等等)。
大致是这么个过程。
有2个事情比较头疼:
1、注册登录账号才能访问
2、各种验证码
登录的话获取登录后的cookie,以后每次爬取的时候,模拟即可。
但是验证码的话,如果碰到变态的验证码,就哭吧。。。
像下面这种:

反正我是没办法攻破。。
不过用上Spyfari,人工点击下,这是很容易的事。
下次再登录,登录状态已经保存了,哈。
除非每一步都要验证码,这种情况不太可能发生吧,毕竟牺牲了用户体验哈。
这就是可视化的优点,各种网站都可以爬取。
我今天先把p站的各个排行榜上的信息爬下来了,还下了图片~
喜欢二次元的朋友应该会喜欢看吧~~



p站的一些排行榜,我都保存为一个个的json文件了,每天都更新排名,看来可以定时去爬取了。
上面那个pixivRank.js是爬取的代码,我会打包进spyfari里的,作为例子。
初次接触可以直接在spyfari里打开,运行下,体验下爬取数据的乐趣。
下面是我爬取的数据存放的格式:
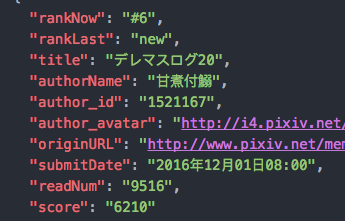
主要爬取了名次、作者、图片url、还有投稿日期;
这个页面是异步加载的,需要不断的滑动到页面最底端才能获取得到数据,但是对于spyfari来说,这个还算是很容易的,毕竟是可视化的爬虫工具,哈,可以做到完全模拟人工操作,过程还是可见的。
其中,投稿日期是异步获取的,需要模拟鼠标点击,然后获取数据。
Spyfari处理异步加载的内容很容易。
这是今天修完Spyfari的一些bug之后,测试代码下载的图片。
下面看看工作页面吧~
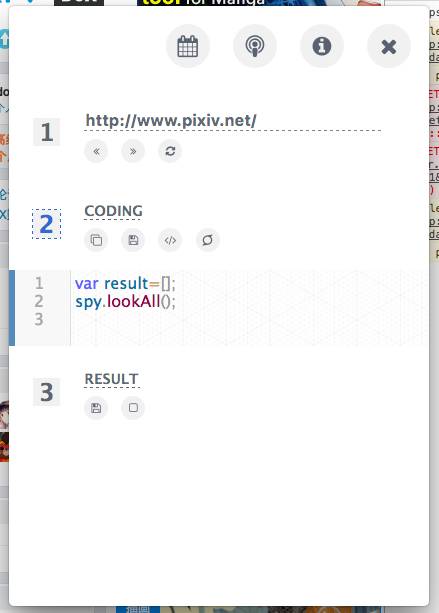
最上面一栏是:
定时任务、云端代码共享、操作指引、关闭spyfari。
都还没有进一步开发,待我下礼拜继续完善。
接下来是:
1、需要爬取数据的网址控制,调用的是我精简的chrome浏览器,毕竟爬取数据第一步是分析网页结构啊,要方便的调试代码,还要方便定位标签。
2、编写爬取代码的地方,我集成了一个编辑器。简单好用,在右侧浏览器调试好代码,直接拷过来,保存在本地或者打开本地已有的爬取代码。
代码编写完后,直接点击运行按钮。
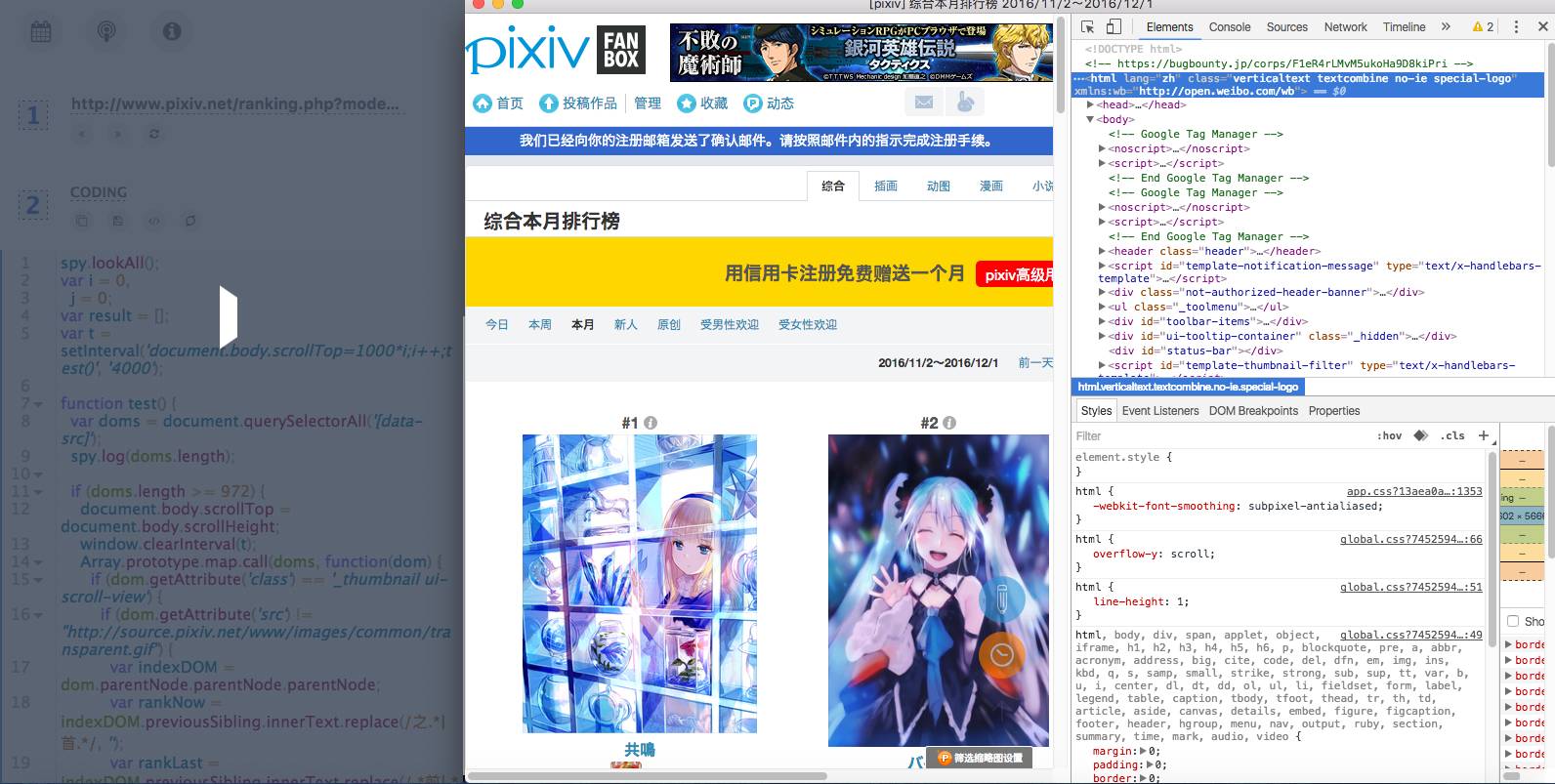
愉快的工作起来了,右边还可以实时看到运行的情况,包括一些模拟登录啊,模拟鼠标点击、滑动动作啊~一目了然。
3、是一些爬取的结果输出,还有log的输出,我整合了一些api,方便使用。
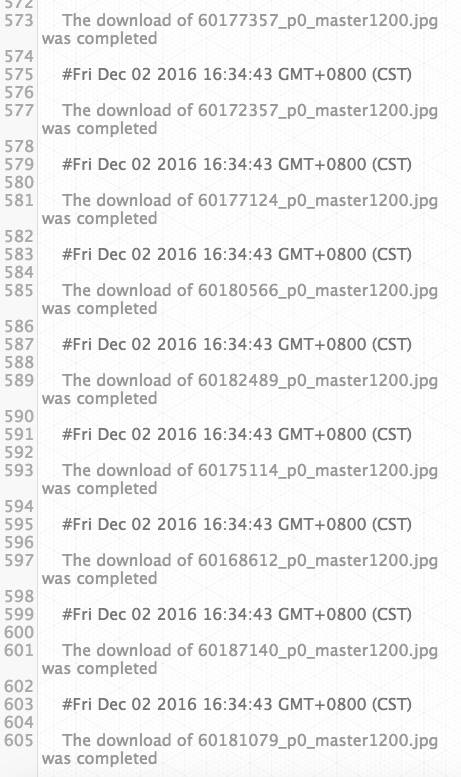
如果有下载动作,比如下载图片,也会自动得打印出来。后续会再完善进度提示的功能。
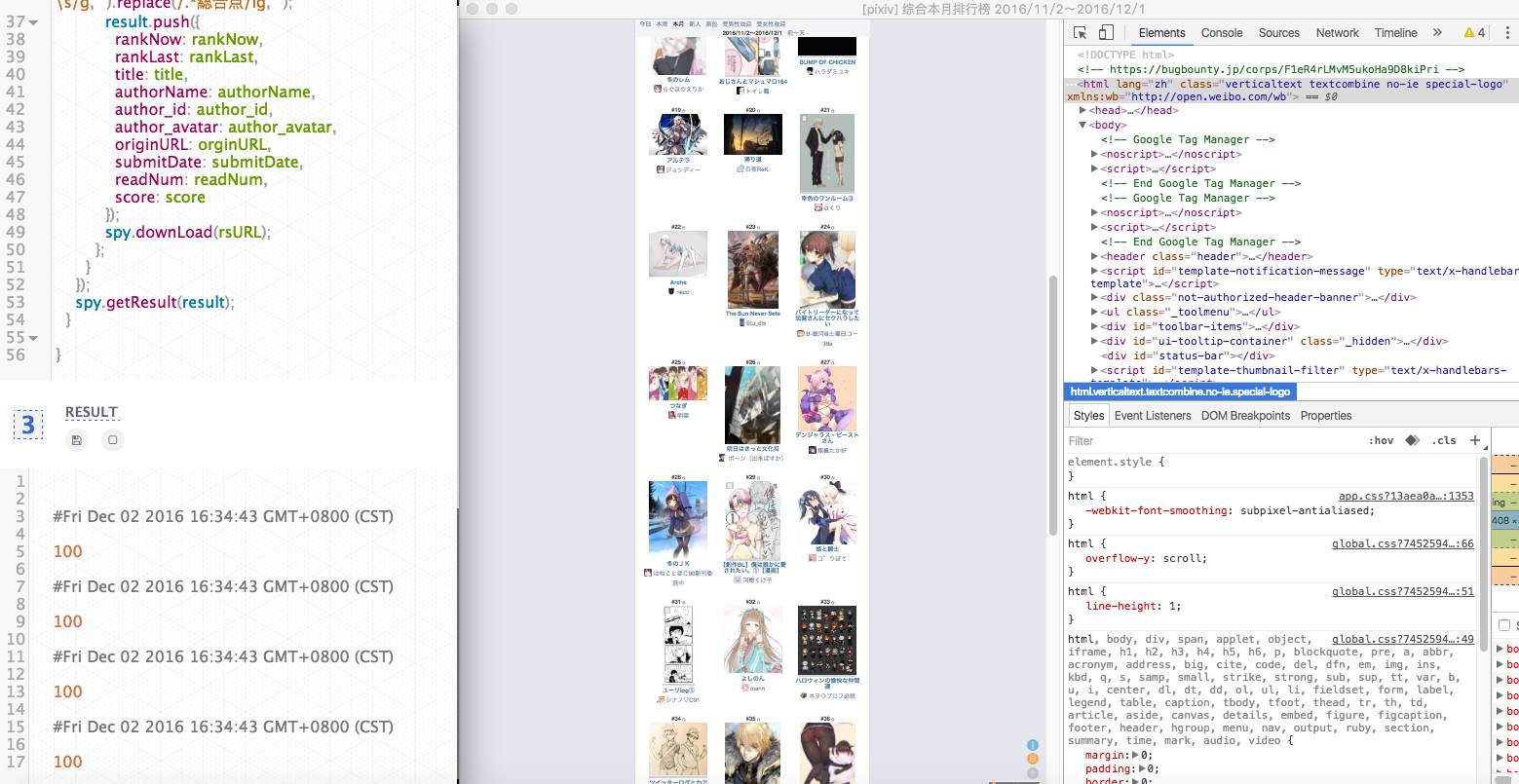
下面这张图是下载的信息输出:
感谢各位的阅读!关于“Spyfari怎么用”这篇文章就分享到这里了,希望以上内容可以对大家有一定的帮助,让大家可以学到更多知识,如果觉得文章不错,可以把它分享出去让更多的人看到吧!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





