今天就跟大家聊聊有关如何使用Antlr构建用户筛选的DSL,可能很多人都不太了解,为了让大家更加了解,小编给大家总结了以下内容,希望大家根据这篇文章可以有所收获。
随着业务的发展,我们会积攒越来越多的用户,为了能够对用户更精准的进行营销,挖掘,或者统计,我们会对用户进行打标,打标可以包含诸多维度,例如:
基础信息:包括年龄段,性别等
订单信息:例如,首次订单时间,近30日订单量,近7天订单量等
券信息:近7日使用券次数
有了这些用户标签之后,我们可以对用户进行筛选,创建人群,然后针对人群做一些有针对性的营销活动,例如:
乌鲁木齐低频-满送:((常驻城市==乌鲁木齐)and (近7日成单数>0)and (近7日成单数 <6))
上海新注册用户-拉新:((注册城市==上海) and (注册时间距今天数 < 3))
这些活动都必须按照某些标签来筛选用户,因此,我们设计了一个用户画像系统,让运营可以很方便的进行人群的创建和过滤,整体的结构如下:
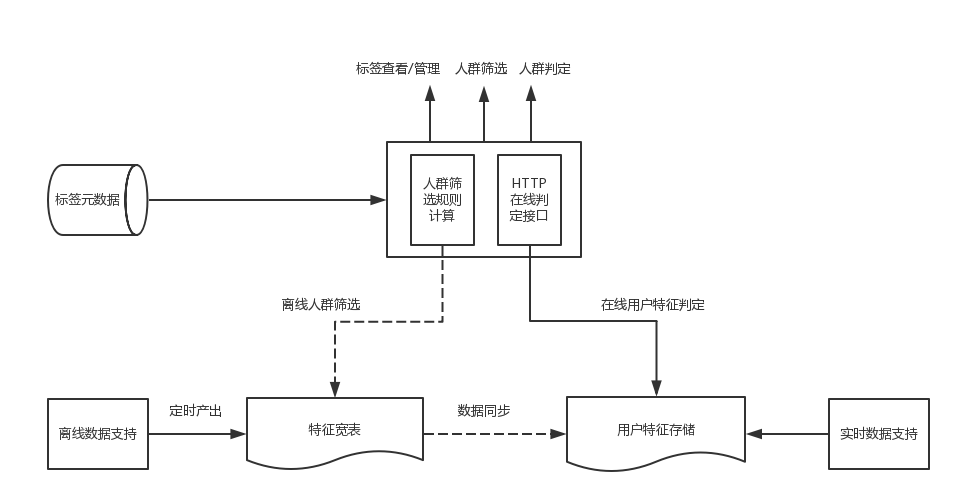
整个架构分为两部分:
离线数据筛选:根据用户输入的各种规则筛选用户,例如筛选规则:((常驻城市==乌鲁木齐)and (近7日成单数>0)and (近7日成单数 <6))
在线用户判定:给定一个用户,判定该用户是否满足特定规则,例如,判断当前用户的注册时间距今天数是否小于3天。
今天,我们就讲一下用户筛选的核心处理流程:筛选规则的解析和处理,整体流程如下图:

规则处理模块简单说来就是将前端运营输入的规则转化为SQL。运营输入的筛选规则就是我们的定制的DSL(domain-specific language),虽然简单,但是可以依此为例,讲一下借助于Antlr4来处理DSL的一般过程。
本文主要分为两个部分:
第一部分讲一下语法分析的基础,里面会大概讲一下自定义一个DSL的基本步骤,如何使用Antlr达到事半功倍的效果;
第二部分讲一下我们是如何具体设计的,包括我们的DSL是怎么定义的,整个流程包含哪些步骤,以及一些我们的总结。
回忆一下大学的编译原理,一门语言的处理流程基本包括:
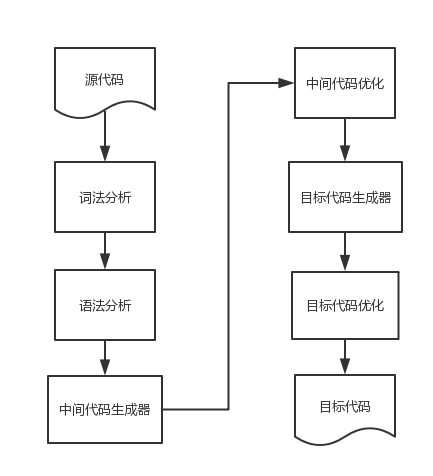
整个流程还是很复杂的,幸好我们不需要自己创造一门目标代码,我们只需要将我们的DSL转化为SQL,那么,流程会简化很多。通过使用Antlr之后,前面的词法分析和语法分析也可以节省大量工作:

借助于Antlr我们只需要定义文法文件,然后,通过对应的开发插件可以自动生成Antlr的处理程序,Antlr会完成词法分析和语法分析,并提给给我们两种遍历抽象语法树的能力:
Listener模式:Antlr默认的模式,被动的按照深度遍历的方式访问整个抽象语法树
Visitor模式:需要显式告诉Anltr创建Visitor,开发者可以主动控制遍历整棵树的过程
通过上面这两种方式,我们就可以获得抽象语法树的结果,接下来,我们可以接收一个节点处理一个节点,类似于解释执行,或者翻译生成中间表示形式,类似于Java的Class文件。
这个地方有必要简单说一下Antlr的文法文件,Antrl文法使用EBNF的方式定义,不支持左递归。一个文法文件的例子(不完整):

在定义文法文件的时候,可以自顶向下设计,逐渐拆分更细粒度的“语法”,然后,注意消除歧义,避免左递归。不过幸运的是,我们基本不需要自己从头开始写这么一个文法文件,Antlr已经给我们列举了常见语言的文法文件,我们可以直接搬来使用,后面讲到的我们的DSL,也是参考了JSON的文法文件。
更多的Antlr技术资料可以查看官方文档,下面重点介绍下我们是如何定义DSL以及如何处理的。
既然是DSL,那么在设计的时候就必须考虑自己的业务场景,我们所面临的需求主要包括:
方便运营通过拖拽的形式组合查询规则
方便前端模块化的组合查询规则
方便跟公司其他业务线的规则进行整合
我们主要看看前面两条的考虑,下面是我们产品设计的前端界面:
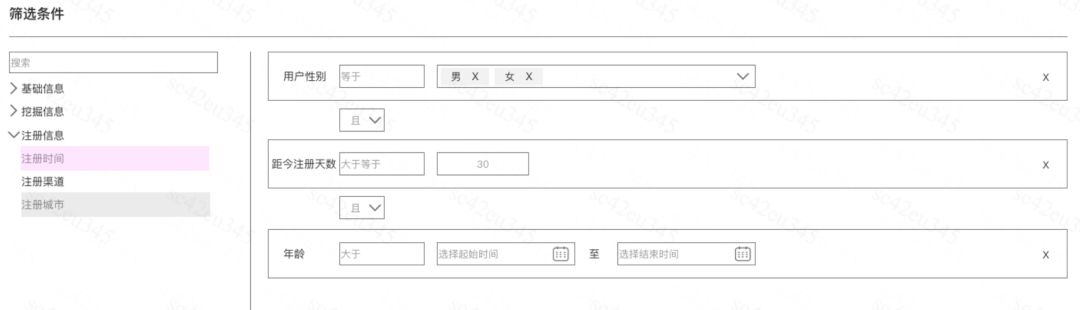
可以看出,整个规则筛选模块也包括下面几个部分:
条件组合:条件可以嵌套条件,或者嵌套一个具体规则对象
规则对象:具体的用户标签和标签的取值范围
基于上面的页面组合方式,我们设计了我们的DSL,例如,我们想筛选出一线城市2018年来高频用户,组装的规则如下:
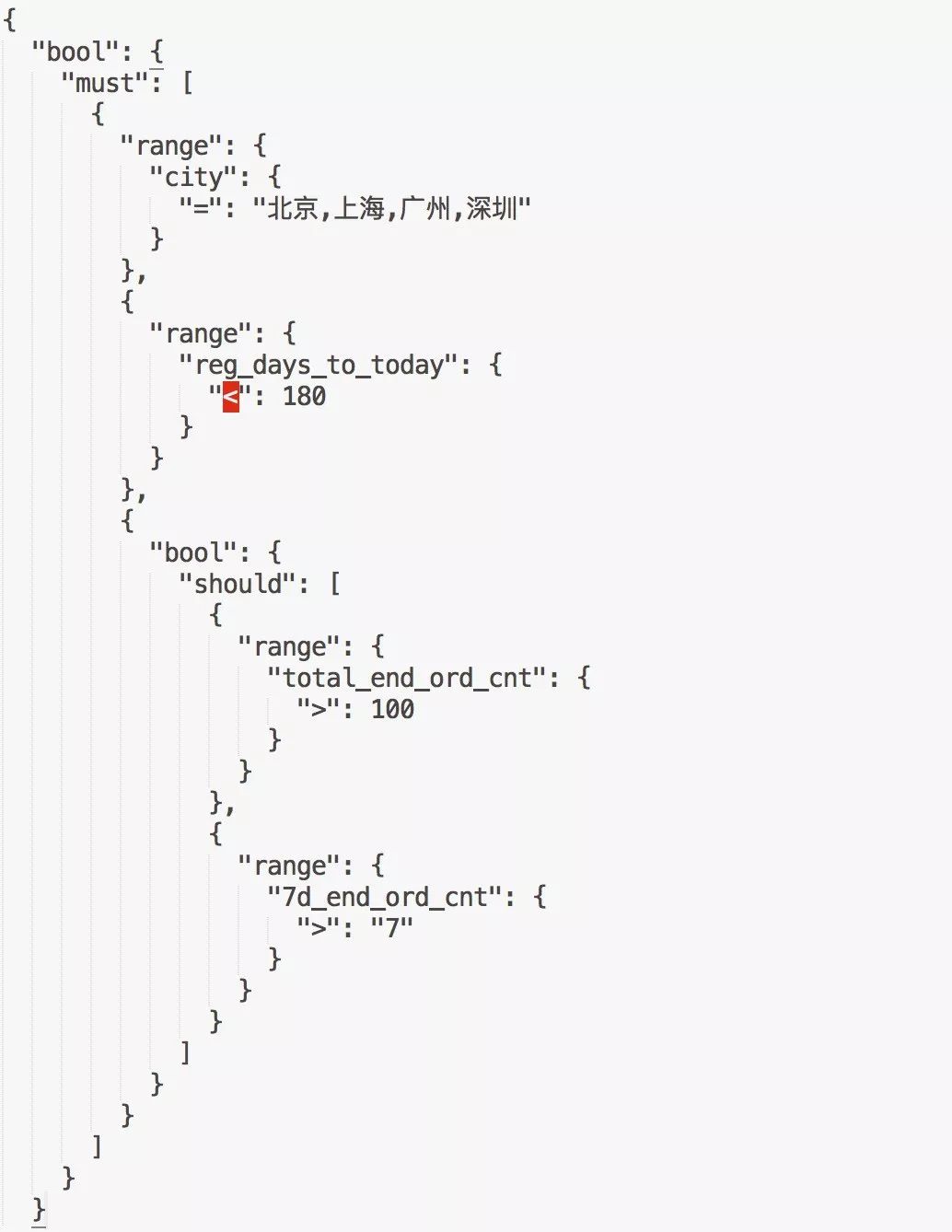
我们的文法文件如下(不完整):
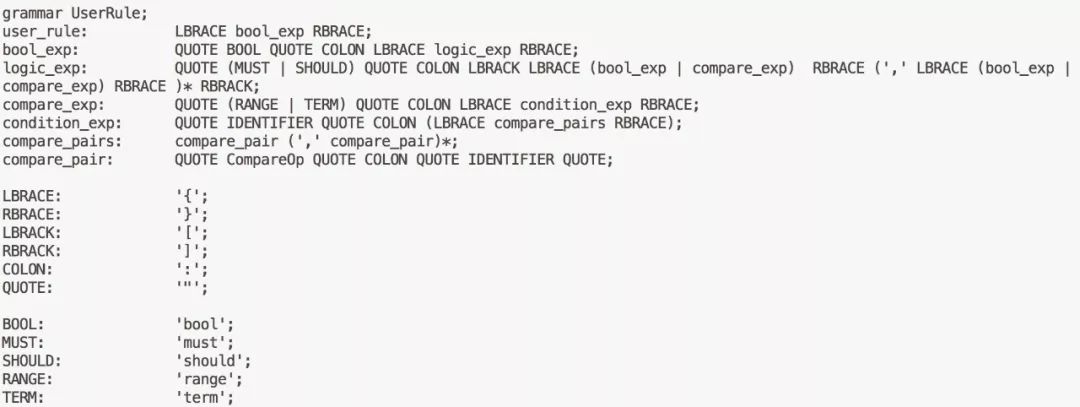
我们的DSL基于JSON语法,定义跟前端页面的布局基本可以对应起来:
bool表达式:表示一个逻辑块,可以是与的关系,也可以是或的关系,bool可以嵌套,也可以包含一个具体的筛选表达式
筛选表达式:包括筛选的标签名字,筛选的条件,对应与页面的一个筛检模块,不能包含子元素,必须按照特定的规则进行组装
有了这套DSL之后,前端就可以比较方便的进行渲染和修改,最终会将运营通过拖拽创建的规则以JSON的形式交给后端处理。
接收到DSL规则后,系统按照下面的步骤进行处理:

在设计的时候,借助于语法分析的常规流程以及Java的编译流程,我们抽象出来两层中间结果的三层处理模型:
第一层:原始的Anltr处理模块,将DSL规则转化为GrammarNode。GrammarNode基本跟抽象语法树保持一致,也是一颗树形结构,里面包含了规则的原始信息:
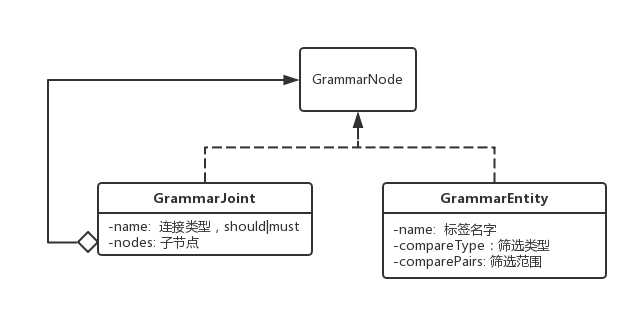
第二层:预处理模块:预处理模块反向依赖于一个MetaProvider。预处理模块通过MetaProvider获取每个标签的Hive表信息,包括:表的名字,表的取数规则,字段类型等等,这一阶段主要负责:
数据验证:主要包括用户输入数据的合法性校验
查询条件的生成:基于单个标签生成查询条件,将最终的结果输出成SqlNode的形式。

其中在SqlTableNode节点中是组合好的部分条件语句,形如下面的形式:
datediff(from_unixtime(unix_timestamp(),'yyyy-MM-dd HH:mm:ss'), regis_time) < 180
第三层:目标代码生成器:也就是SQL生成器,这一层的输入除了第二部的SqlNode之外,还包括公共的上下文参数,例如:筛选的日期(用于分区),最终筛选的字段(也就是select出来的参数)等。最终,通过深度优先的算法,将每棵子树进行转化和拼装,形成完整SQL。可以看出来,每个小的condition都会使用'()'括起来,防止出现条件间逻辑错乱。

事实上,中间结果的设计并不是一蹴而就的,而是在实际编码的过程中,逐步抽象出来,最终演化成这样一个流程。采用中间结果的方式有下面几点好处:
隔离性比较好:GrammarNode对后面两层屏蔽了页面规则的变化,SqlNode对最后一层屏蔽了表结构的变化
流程复用:一个典型的场景就是,需要事先判断满足运营输入规则的用户数有多少。基于上面的流程就很简单的,可以扩展的目标代码生成器用于生成select count的sql语句。
虽然前端支持的筛选规则有限,例如,嵌套层级的限制等,但是我们的DSL可以做的很强大,在预处理模块我们甚至还可以做一些优化性的工作,比如:
跨表join的时候,根据历史数据评估每个表的数据量,让小表join大表
属于统一个表的筛选字段自动合并,而不是使用join
借助于Antlr,我们可以很方便的构建符合自己业务场景的DSL,所以,我们可以多思考有哪些业务领域,有哪些操作可以标准化起来,然后使用DSL来实现业务的描述和执行,既可以让代码简洁清晰,又可以提高生产力。
看完上述内容,你们对如何使用Antlr构建用户筛选的DSL有进一步的了解吗?如果还想了解更多知识或者相关内容,请关注亿速云行业资讯频道,感谢大家的支持。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/u/4590259/blog/4585180



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



