本篇内容介绍了“怎么用R语言制作柱形图”的有关知识,在实际案例的操作过程中,不少人都会遇到这样的困境,接下来就让小编带领大家学习一下如何处理这些情况吧!希望大家仔细阅读,能够学有所成!
其实R语言本身就带有各种作图函数,比如plot、bar、pie等,而且语法非常简单明了,为什么还要用ggplot2这种语法独立性很强、自成体系的作图包来作图呢?
一个例子就能感受到:
plot(mpg$cty,mpg$hwy)#R语言内置散点图函数(无需加载任何辅助工具包)
ggplot(mpg,aes(cty, hwy)) + geom_point(colour="steelblue")+labs(x = "City mpg", y = "Highway") #ggplot2包中的ggplot函数(需先加载ggplot2工具包支持)
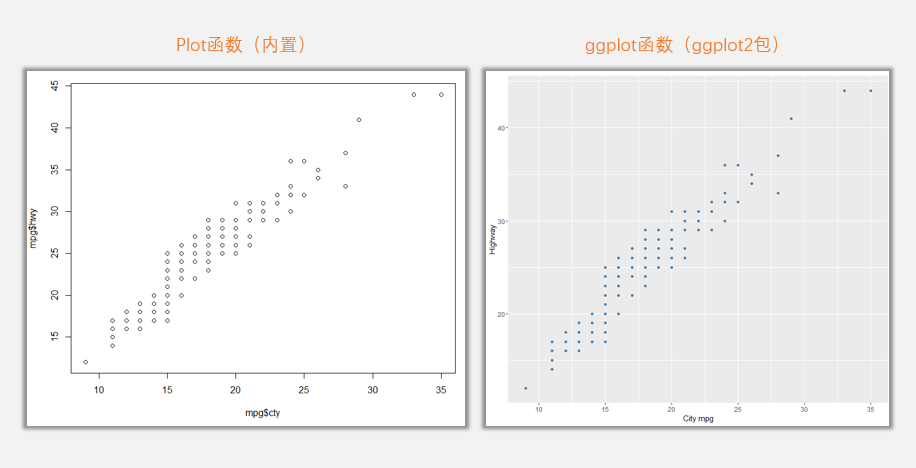
这只是一个很简单的例子,两个图所表达的是同样的数据变量,同样的图表形式,而且在精确度上几乎毫无差异。
但是,即便两种味道同样的食物,外观的好坏也会影响食欲,这两个图表给人的感受,就像是一款诺基亚手机与一款iPhone手机给人带来的对比一样,即便功能差异不大,但是外观上的艺术感已经将两者拉开了层次。
这也是为啥我曾经刚接触R语言,还在糊里糊涂的学各种内置图表函数时,突然看到大神们早已用上了ggplot,立马选择入门ggplot的原因。
今天给大家介绍ggplot函数中柱形图的用法(一大家子呢,单序列柱形图、簇状柱形图、堆积柱形图、百分比堆积柱形图、以及分面柱形图)。
其实严格来讲,在R预言的作图函数中,是并不严格区分柱形图与条形图,因为二者无论是形式上还是功能上都表达着同样的数据类型和信息。他们有一个通用的名称——Barplot。
二者之间的转换往往只需要添加一个额外的参数而已。
coord_flip()
今天先介绍柱形图:
这里就暂且使用ggplot2包中内置的数据集mpg。
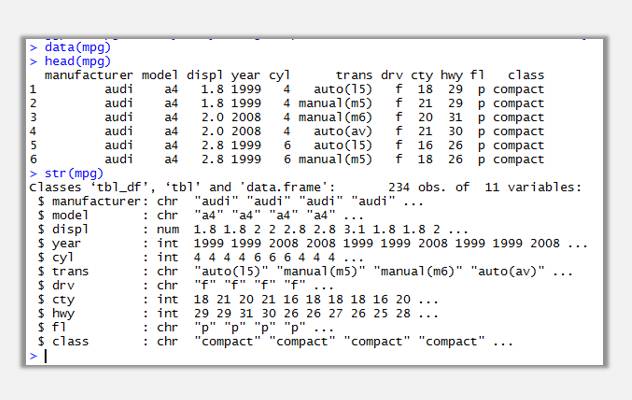
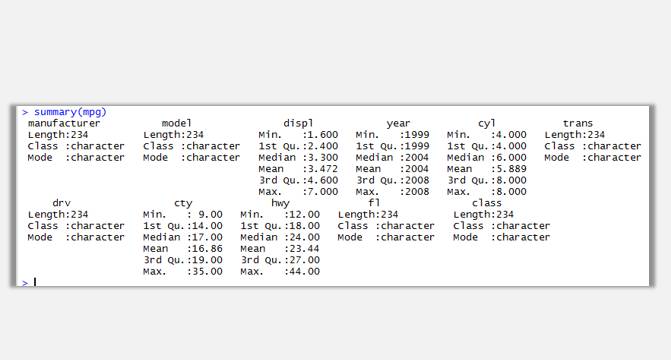
通过head(mpg)函数可以查看该数据集前6条记录,通过str(mpg)查看数据集各变量类型,summary(mpg)可以查看该数据集简单的统计汇总结果。
单序列柱形图:
ggplot(mpg,aes(class,displ))+geom_bar(stat="identity",fill="steelblue")
以上参数中,mpg是数据集名称,aes内的参数依次是x值——class(分类变量),y值——displ(连续变量)。
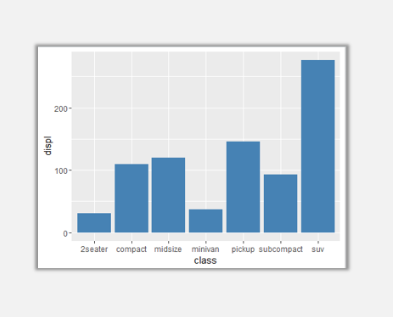
geom_bar是在ggplot坐标系系统之上添加的柱形图图层,stat是对其中的数值型变量所做的统计变换(默认为count),fill是颜色填充设定,可以是某一分类变量,也可以直接映射为颜色。
ggplot(mpg,aes(reorder(class,displ),displ)+geom_bar(stat="identity",fill="steelblue")
以上最简单的单序列柱形图,其实还有非常多的参数调整设定,这里不再一一详解,感兴趣可以参考ggplot2——数据分析与图形艺术这本该包作者的书。
多系列簇状柱形图:
with(mpg,table(class,year))
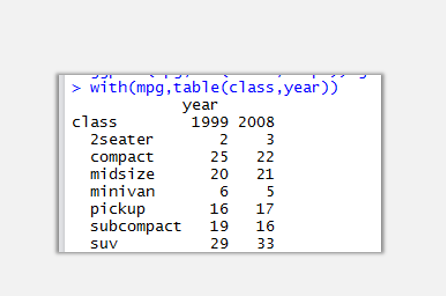
通过汇总可以看到class与year之间的交叉表关系,以下将以这两个变量来制作系列簇状柱形图。
ggplot(data=mpg,aes(x=class,fill=factor(year)))+geom_bar(position='identity')
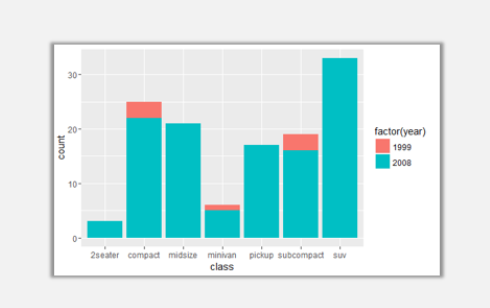
因为year是int型变量,所以在参数设定市需要用factor变成因子型。以上图表是未做任何设定时的两系列柱形图,可以看到两个系列位置重叠无法看到无法看清楚1999年的柱形图实际高度。
ggplot(data=mpg,aes(x=class,fill=factor(year)))+geom_bar(position='identity',alpha=0.3)
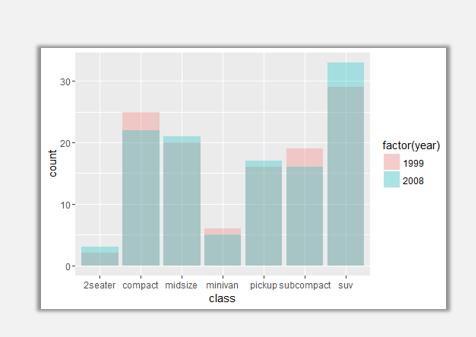
即便是通过alpha参数来设置柱形图的透明度,也还是很难将1999年与2008年的柱形图清晰的区别开。这里我们想要看到的效果是,1999年与2008年的柱形图互不重叠而是并列放置。需要调整postion参数。
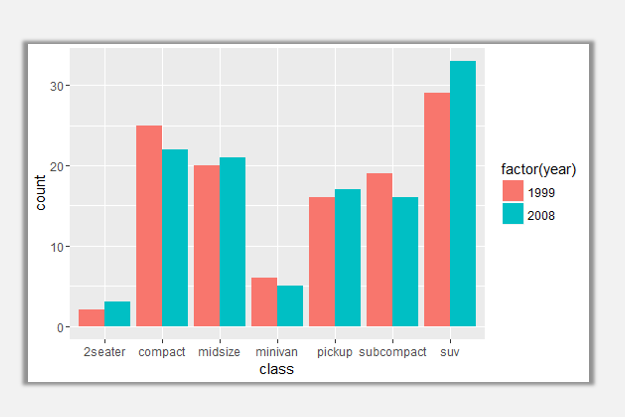
ggplot(data=mpg,aes(x=class,fill=factor(year)))+geom_bar(position='dodge')
将position参数调整为dodge之后,达到了我们想要的效果,此时两个序列并列,可以清晰的看到彼此高度。
当然我们也可以设置两个序列堆叠。
ggplot(data=mpg,aes(x=class,fill=factor(year)))+geom_bar(position='stack')
通过设定position参数为stack,我们可以以堆叠形式处理两年的指标,同样达到目标。
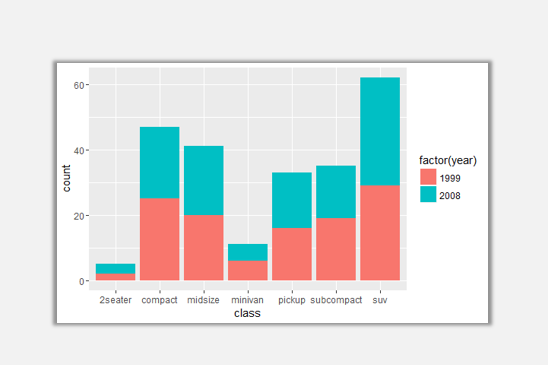
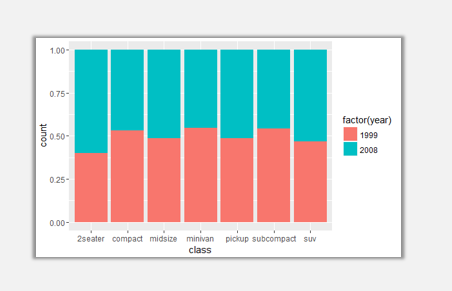
如果我们想要观察每一个品类中两年度所占份额百分比,同样也可以通过修改position参数实现。
ggplot(data=mpg,aes(x=class,fill=factor(year)))+geom_bar(position='fill')
此时便可以得到各品类两年数据份额占比,仔细观察你会发现,图例颜色顺序与图表中颜色顺序相反,果然到处都是坑啊。
ggplot(data=mpg,aes(x=class,fill=factor(year)))+geom_bar(position='stack')+guides(fill = guide_legend(reverse = TRUE))
ggplot(data=mpg,aes(x=class,fill=factor(year)))+geom_bar(position='fill')+ guides(fill = guide_legend(reverse = TRUE))
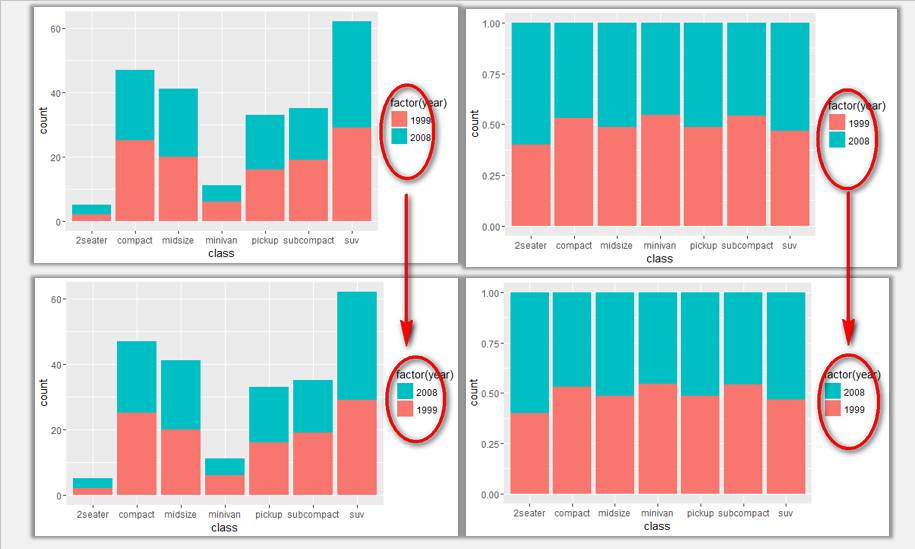
通过设定柱形图填充顺序与图例显示顺序,使得图例中的颜色顺序与图表中一致。
最后一种图表类型是分面组图:
ggplot(data=mpg,aes(x=class,fill=factor(year)))+geom_bar(position='fill')+facet_grid(. ~ drv)
ggplot(data=mpg,aes(x=class,fill=factor(year)))+geom_bar(position='fill')+facet_grid(drv~.)
除此之外,我们还可以套用现有主题、对图表各细分元素进行精修(图例、坐标轴标签、数据标签、柱形间距、背景及颜色主题等),这些细节有很多的专用参数进行调整设置,详细内容还是最好看看哈德利那本专著,会理解的比较透彻。
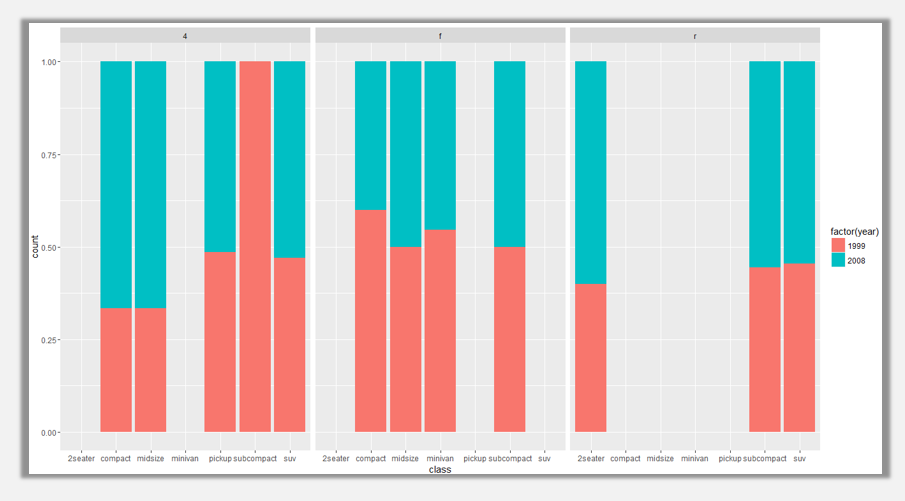

通过设定分面参数:facet_grid,我们可以将某一分类变量做成每一个分类项的分面组图。
但是考虑到大家日常在excel中作图比较多一点儿,R语言中的作图方法与excel截然不同:
excel中通过汇总过后的宽数据作图(也是office能够识别的唯一格式)
但是R语言秉承的作图规则是标准数据源(长数据,也就是类型数据库格式的数据源)
图表所支持的数据存储格式的巨大差别往往成为初学者在R语言图表面前磕磕碰碰、引起困惑的重大原因。(本人也是初学者哦~)
所以,想要玩转R语言可视化,必须能够适应长数据这种标准数据存储格式的特点。理解变量类型是如何对图表呈现产生的影响。
想要适应R语言作图:个人觉得有两条路子可以参考:
1、假设你已经完全沉浸在或者无法脱离excel的宽数据作图形式,这样也就意味着你导入的数据集往往也是宽数据格式。你需要非常熟练的使用R语言中的数据重塑辅助工具包:dplyr、tidyr、reshape2等将宽数据重塑为R作图支持的长数据格式。好处是可以循序渐进的适应R语言作图数据的习惯,但是需要额外学很多数据重塑工具与函数。
2、假如你对于长数据有很好的理解(比如经常用统计分析软件,大部分都接触的标准长数据,也就是一维表),那么你完全可以直接在excel中将宽数据转化为长数据(二维转一维),或者直接将数据库中的长数据导入R,只需做一些基本的设定即可,至少不会在数据长宽格式转换上浪费太多时间和精力。
我比较提倡第二种,因为,excel不是标准的可视化软件(虽说功能不可小觑,但是因为兼顾着数据汇总的办公属性,所以对于数据存储的格式没有做过多的设定,灵活性太高,为了适应这种情景,微软的工程师们所开发的图表引擎也要使用这种汇总后的二维数据表作为作图数据,这很明显,因为从数据库刚导出的一维表(长数据),很多场合是不适合直接在excel中作图的)。
而像Eviews、SPSS、Stata以及R、Python等专业的统计分析工具甚至Tableau、PowerBI等数据可视化软件,都是默认接受长数据作图的。(在数据导入前都会做变量格式设定,尽管也会提供一些长宽数据转换的工具)。
“怎么用R语言制作柱形图”的内容就介绍到这里了,感谢大家的阅读。如果想了解更多行业相关的知识可以关注亿速云网站,小编将为大家输出更多高质量的实用文章!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/u/3335309/blog/4575547



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



