这篇“r语言性别质控的方法”文章的知识点大部分人都不太理解,所以小编给大家总结了以下内容,内容详细,步骤清晰,具有一定的借鉴价值,希望大家阅读完这篇文章能有所收获,下面我们一起来看看这篇“r语言性别质控的方法”文章吧。
「原理:」检查性别差异。先验信息,女性的受试者的F值必须小于0.2,男性的受试者的F值必须大于0.8。这个F值是基于X染色体近交(纯合子)估计。不符合这些要求的受试者被PLINK标记为“PROBLEM”。
「上一步,去掉缺失信息后,现在有文件是过滤缺失后的文件:」
HapMap_3_r3_5.bed HapMap_3_r3_5.fam HapMap_3_r3_5.iremHapMap_3_r3_5.bim HapMap_3_r3_5.hh HapMap_3_r3_5.logplink --bfile HapMap_3_r3_5 --check-sex 结果文件:plink.sexcheck第一列为家系ID,第二列为个体ID,第三列为系谱中的性别,第四列为SNP推断的性别,第五列是否正常,第六列为F值。
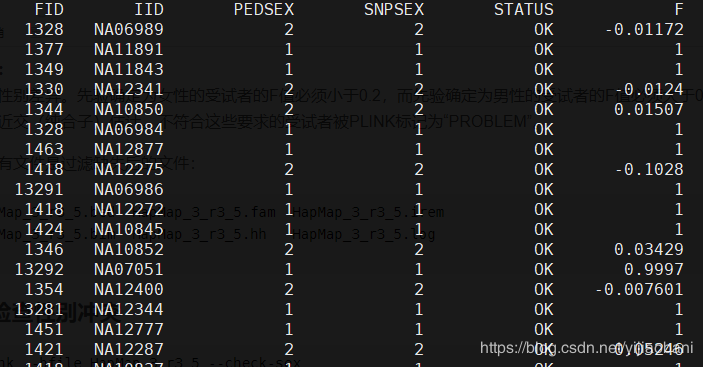
「使用R语言作图:」
gender <- read.table("plink.sexcheck", header=T,as.is=T)pdf("Gender_check.pdf")hist(gender[,6],main="Gender", xlab="F")dev.off()pdf("Men_check.pdf")male=subset(gender, gender$PEDSEX==1)hist(male[,6],main="Men",xlab="F")dev.off()pdf("Women_check.pdf")female=subset(gender, gender$PEDSEX==2)hist(female[,6],main="Women",xlab="F")dev.off()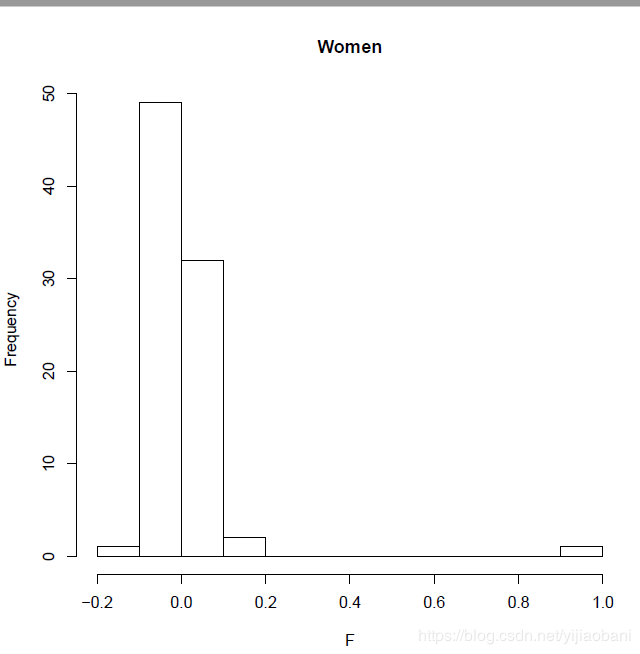
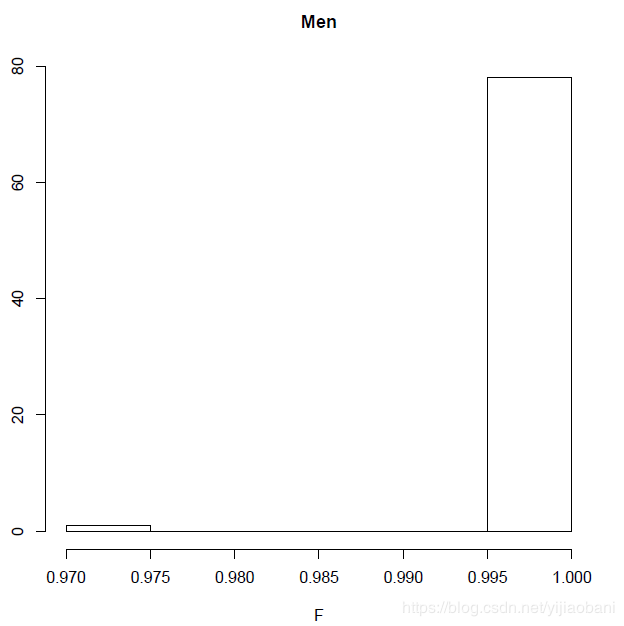
图中可以看出,woman中,大部分都是小于0.2,有一个为1,应该是错误的ID。
我们使用grep过滤一下:根据STATUS列,如果有问题的话,为“PROBLEM”,我们可以根据这个关键词将有问题的行打印出来。
grep "PROBLEM" plink.sexcheck 1349 NA10854 2 1 PROBLEM 0.99
可以看出,个体NA10854是有问题的。
将相关错误的ID提取出来(家系ID,个体ID),之所以提取家系ID和个体ID,因为plink有参数remove可以根据ID进行筛选。
grep 'PROBLEM' plink.sexcheck | awk '{print $1,$2}' >sex_discrepancy.txt 我们将结果保存在sex_discrepancy.txt。
remove去掉个体plink --bfile HapMap_3_r3_5 --remove sex_discrepancy.txt --make-bed --out HapMap_3_r3_6 当然,你也可以对个体进行判定填充,这是用--impute-sex就可以实现,这样的话那个错误的个体会根据统计量更改性别信息。这里我们选择的是删掉这个个体。
去掉个体或者SNP,关键词不一样,容易混淆,这里总结一下。
「保留或去掉个体:」
--keep <filename>--remove <filename>--keep-fam <filename>--remove-fam <filename>「保留或去掉SNP:」
--extract ['range'] <filename>--exclude ['range'] <filename>以上就是关于“r语言性别质控的方法”这篇文章的内容,相信大家都有了一定的了解,希望小编分享的内容对大家有帮助,若想了解更多相关的知识内容,请关注亿速云行业资讯频道。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/u/4592498/blog/4451095



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



