本篇文章给大家分享的是有关怎么进行Analytics Zoo入门,小编觉得挺实用的,因此分享给大家学习,希望大家阅读完这篇文章后可以有所收获,话不多说,跟着小编一起来看看吧。
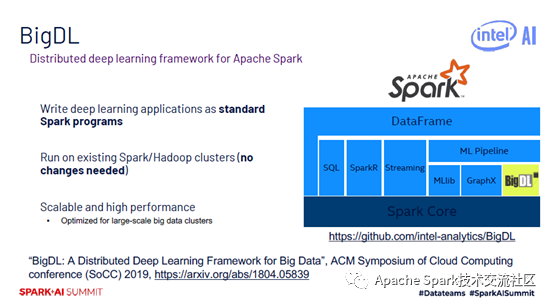
BigDL
BigDL是2016底开源项目,是基于Spark的分布式深度学习框架。当时考虑到Spark在深度学习的支持方面比较弱,所以希望为大数据用户提供更多先进的深度学习算法。开发完BigDL之后发现它对深度学习出身的开发者并不友好,因为大家需要学习Spark相关知识,还需要学习Scala。因此开发了Analytics Zoo,在Analytics Zoo中直接提供了TensorFlow,PyTorch,Keras,BigDL,Ray的支持。
当时做BigDL的初衷是因为很多大数据用户希望使用深度学习的算法,如京东有大量图像存储在HBase上,需要对图像做预处理,将处理后数据放到模型中继续工作,还需要将特征提取结果存放在HDFS上,做图像相似性检索等应用。京东使用的是Caffe,与大数据集群不同的是,两个集群网络带宽有限,且图像经常更新,用户每次从GPU集群拉取到大数据集群网络开销都非常大。当英特尔将整个预测的pipeline搬到Spark集群上时,HBase和Spark可以结合在一起,提供零拷贝的处理策略,这种策略使得京东预测速度提升了3.83倍。
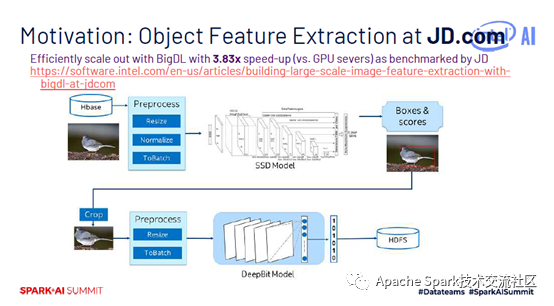
BigDL可以直接跑Spark集群上面,不需要对集群做修改,集成了很多英特尔特有的技术,对模型训练进行加速。大家如果对BigDL有兴趣可参考SoCC上发表的一篇工作。
Analytics Zoo
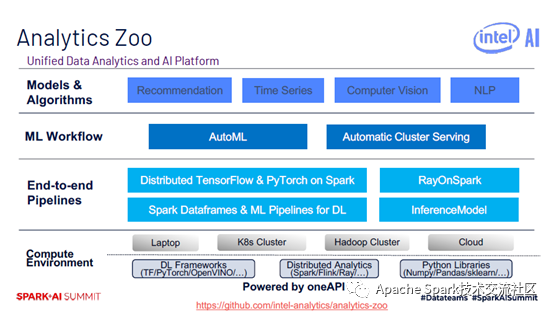
Analytics Zoo是统一的数据分析AI平台,支持笔记本、云、Hadoop Cluster、K8s Cluster等平台、此外,Analytics Zoo提供了端到端的pipeline,大家可以将AI模型应用到分布式大数据场景中。Analytics Zoo还提供了端到端的ML workflow和内置的模型和算法。具体而言,在底层的使用环境中,支持深度学习框架,如TensorFlow、PyTorch、OpenVINO等,还支持分布式框架,如Spark、Flink、Ray等,还可以使用Python库,如Numpy、Pandas、sklearn等。在端到端的pipeline中用户可以使用原生的TensorFlow和PyTorch,用户只需要很简单的修改就可以将原有的TensorFlow和PyTorch代码移植到Spark上来做分布式训练。Analytics Zoo还提供了RayOnSpark,ML Pipeplines,Automatic Cluster Serving,支持流式Serving。在内置算法中,提供了推荐算法,时序算法,视觉以及自然语言处理等。
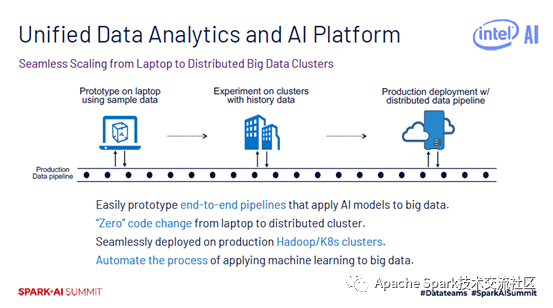
一般大家在开发大数据AI应用时,需要经过三步。首先在laptop上面使用一些样本数据实现模型的原型。然后将代码移植到集群上面,使用历史数据做测试。再将代码移到生产环境中,处理分布式数据。从用户角度而言,希望代码尽可能在第一步完成,后面两步不再修改,即可部署到自己的Hadoop或K8S集群上。
用户首先需要安装Analytics Zoo,可以通过Google Colab或者Aliyun EMR,亦或是在笔记本上Pull Analytics Zoo Docker Image,pip install 等方式安装。

Aliyun EMR指的是Aliyun E-MapReduce, 用户可以选择Analytics Zoo 0.8.1版本或TensorFlow 1.15.0作为可选服务。
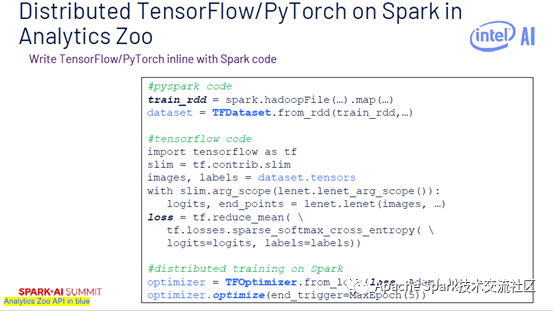
下图中代码部分是Analytics Zoo代码,train_rdd使用了Hadoop API,dataset是从train_rdd导出的TFDataset。开始构建TensorFlow模型,将其放到TFOptimizer中,再定义MaxEpoch。
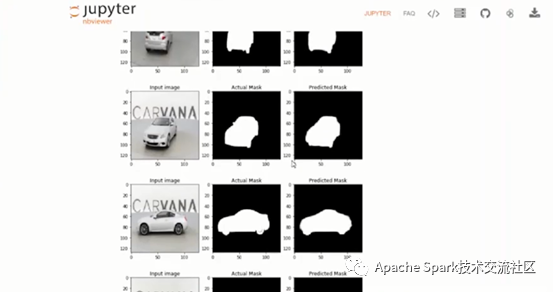
下面展示了Image Segmentation 的一个例子。注意在第一步,需要带上sc=init_nncontext(),表示初始化运行环境,帮助用户初始化analytic-zoo的环境变量以及Spark context。

再将数据下载到指定目录中,加载数据。还可以可视化数据,展示原生图片和Mask后的图片。定义参数,如img_shape,batch_size,epoch等。使用Scipy做数据预处理,得到处理好的特征数据,将数据放到TFDataset中,定义U-Net模型,使用Keras function API,定义loss,使用net.compile()方法,调用summary可查看目前的结构,使用keras_model.fit()方法训练模型,最后再可视化预测结果。比对原始图片,实际Mask图片以及预测图片如下:
下面介绍使用PyTorch的Face Generation 的一个例子,先从PyTorch Hub中下载的PAGN模型,再使用noise方法获得随机数据,将noise放在model中生成结果,如下图: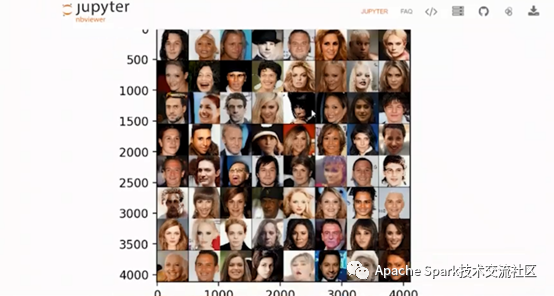
Analytics Zoo的初始化有三种方法,包括sc=init_nncontext(),第二种是使用init_spark_on _yarn() 方法,第三种是使用 init_spark_on_local()方法。
如果想要将Analytics Zoo使用在现有的Spark MLPipeline里面的话,可以使用NNEstimater。

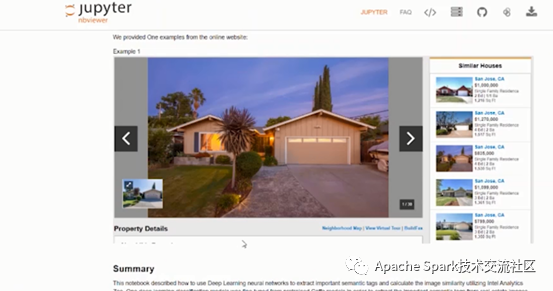
下面介绍Image similarity的例子。客户主要做房产交易,它们的一种业务场景是为用户推荐房子。最开始还是需要sc=init_nncontext() 初始化环境,使用NNImageReader将图片读取到Spark中,定义模型,加载模型,再使用NNEstimater集成Analytics Zoo。

Image similarity可视化结果如下图:
在Production Deployment时,首先要训练模型,再提取图片特征数据集,最后是做预测。下图中左边是正在观看的House的样子,右边是推荐的较为相似的House。
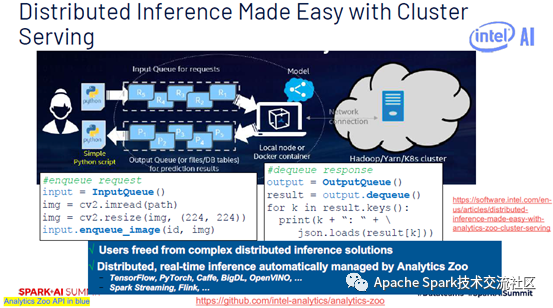
在做Cluster Serving时可以通过InputQueue方式将数据存放到pipeline中,再通过OutputQueue方式输出数据。用户可以更方便的构建出Serving工程。
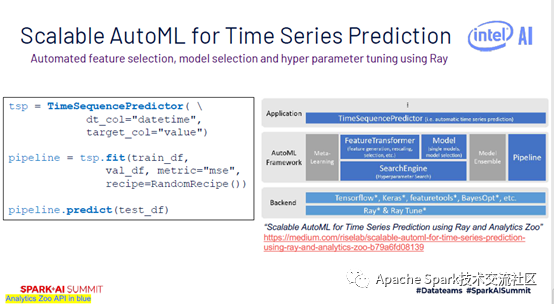
使用AutoML可以做时序数据预测,相信对做医学的同学还是很有用的,如观察某个病人的健康特征随着时间变化的情况。
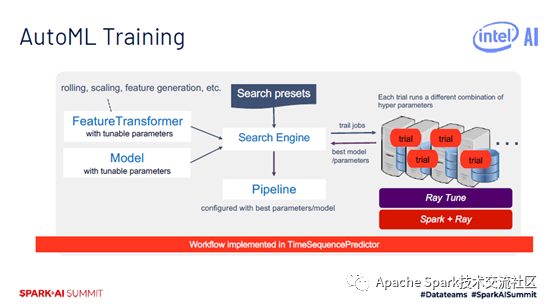
以上就是怎么进行Analytics Zoo入门,小编相信有部分知识点可能是我们日常工作会见到或用到的。希望你能通过这篇文章学到更多知识。更多详情敬请关注亿速云行业资讯频道。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





