这篇文章主要讲解了“RocketMQ消息发送出现system busy、broker busy的原因与解决方案”,文中的讲解内容简单清晰,易于学习与理解,下面请大家跟着小编的思路慢慢深入,一起来研究和学习“RocketMQ消息发送出现system busy、broker busy的原因与解决方案”吧!
最近收到很多RocketMQ使用者,反馈生产环境中在消息发送过程中偶尔会出现如下4个错误信息之一:
[REJECTREQUEST]system busy, start flow control for a while
too many requests and system thread pool busy, RejectedExecutionException
[PC_SYNCHRONIZED]broker busy, start flow control for a while
[PCBUSY_CLEAN_QUEUE]broker busy, start flow control for a while, period in queue: %sms, size of queue: %d
在进行消息中间件的选型时,如果待选中间件在功能上、性能上都能满足业务的情况下,建议把中间件的实现语言这个因素也考虑进去,毕竟选择一门用自己擅长的语言实现的中间件会更具掌控性。在出现异常的情况下,我们可以根据自己的经验提取错误信息关键字system busy,在RocketMQ源码中直接搜索,得到抛出上述错误信息的代码如下: 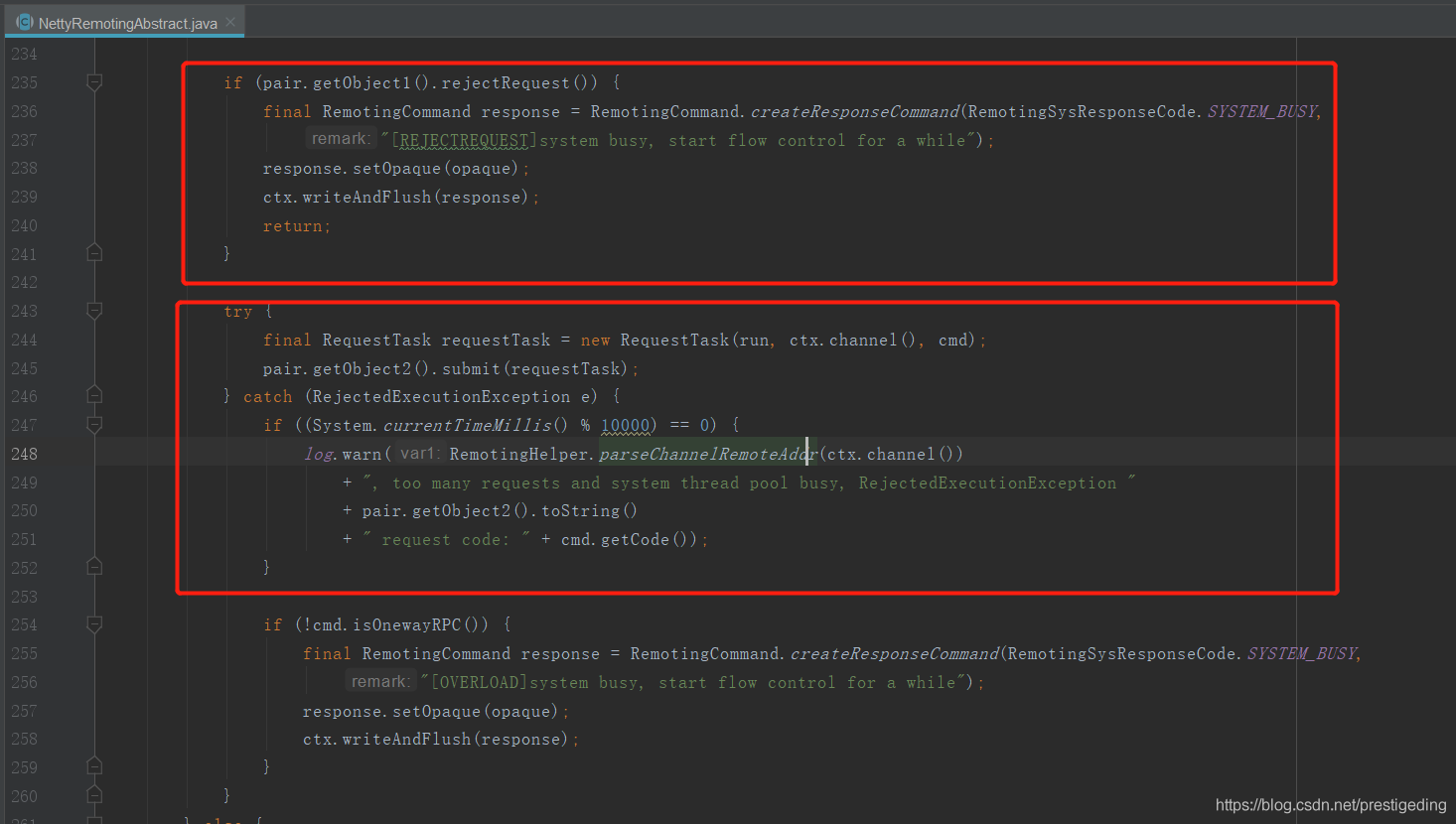
其代码入口为:org.apache.rocketmq.remoting.netty.NettyRemotingAbstract 的 processRequestCommand 方法。从图中可以看出,抛出上述错误的关键原因是:pair.getObject1() 的 rejectRequest 方法和抛出RejectedExecutionException 异常。
备注:本文偏实战,源码只是作为分析的重点证据,故本文只会点出关键源码,并不会详细跟踪其整个实现流程,如果想详细了解其实现,可以查阅笔者编著的《RocketMQ技术内幕》。
RocketMQ的网络设计非常值得我们学习与借鉴,首先在客户端端将不同的请求定义不同的请求命令CODE,服务端会将客户端请求进行分类,每个命令或每类请求命令定义一个处理器(NettyRequestProcessor),然后每一个NettyRequestProcessor绑定到一个单独的线程池,进行命令处理,不同类型的请求将使用不同的线程池进行处理,实现线程隔离。
为了方便下文的描述,我们先简单的认识一下NettyRequestProcessor、Pair、RequestCode。其核心关键点如下: 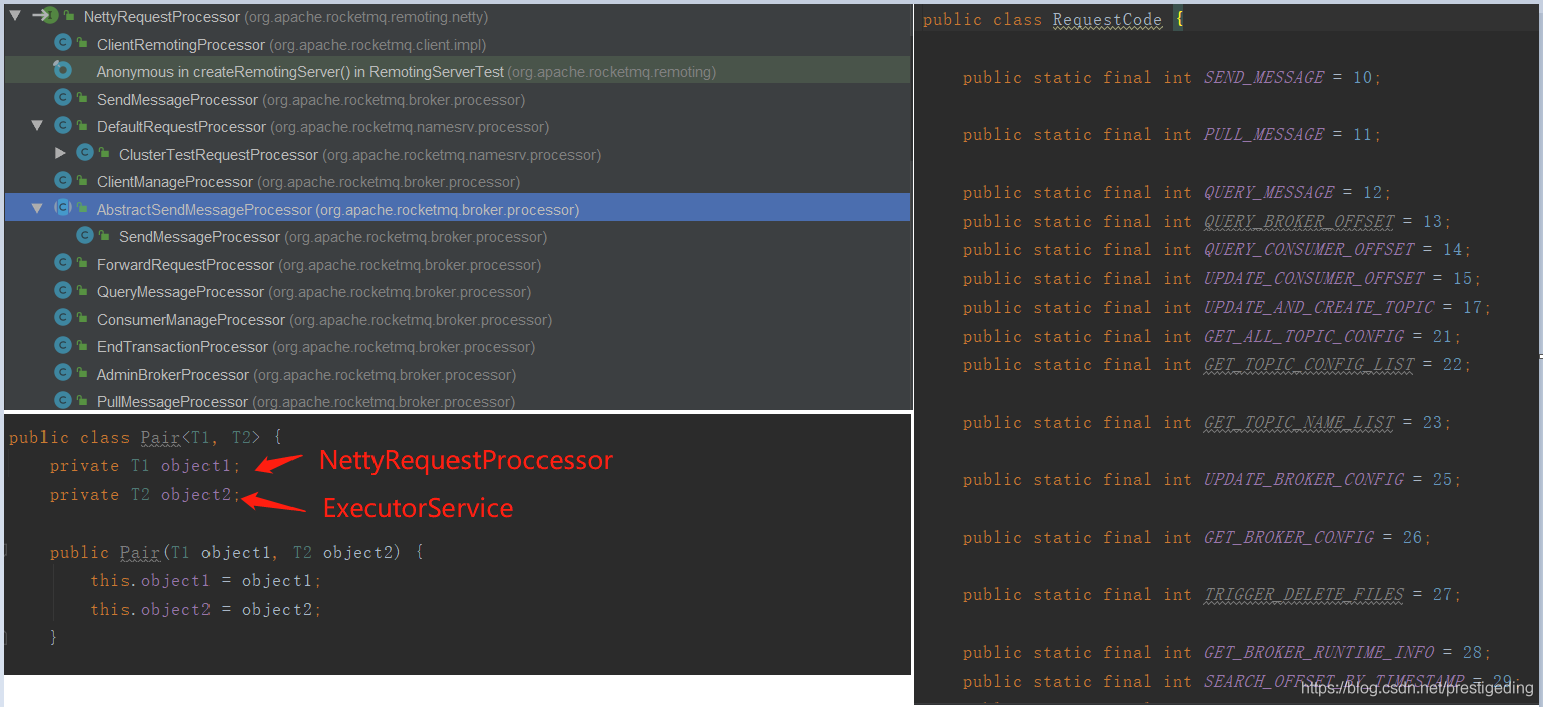
NettyRequestProcessor RocketMQ 服务端请求处理器,例如SendMessageProcessor是消息发送处理器、PullMessageProcessor是消息拉取命令处理器。
RequestCode 请求CODE,用来区分请求的类型,例如SEND_MESSAGE:表示该请求为消息发送,PULL_MESSAGE:消息拉取请求。
Pair 用来封装NettyRequestProcessor与ExecuteService的绑定关系。在RocketMQ的网络处理模型中,会为每一个NettyRequestProcessor与特定的线程池绑定,所有该NettyRequestProcessor的处理逻辑都在该线程池中运行。
由于读者朋友提出的问题,都是发生在消息发送过程中,故本文重点关注SendMessageProcessor#rejectRequest方法。 SendMessageProcessor#rejectRequest
public boolean rejectRequest() {
return this.brokerController.getMessageStore().isOSPageCacheBusy() || // [@1](https://my.oschina.net/u/1198)
this.brokerController.getMessageStore().isTransientStorePoolDeficient(); // @2
}拒绝请求的条件有两个,只要其中任意一个满足,则返回true。
代码@1:Os PageCache busy,判断操作系统PageCache是否繁忙,如果忙,则返回true。想必看到这里大家肯定与我一样好奇,RocketMQ是如何判断pageCache是否繁忙呢?下面会重点分析。
代码@2:transientStorePool是否不足。
DefaultMessageStore#isOSPageCacheBusy()
public boolean isOSPageCacheBusy() {
long begin = this.getCommitLog().getBeginTimeInLock(); // [@1](https://my.oschina.net/u/1198) start
long diff = this.systemClock.now() - begin; // @1 end
return diff < 10000000
&& diff > this.messageStoreConfig.getOsPageCacheBusyTimeOutMills(); // @2
}代码@1:先重点解释begin、diff两个局部变量的含义:
begin 通俗的一点讲,就是将消息写入Commitlog文件所持有锁的时间,精确说是将消息体追加到内存映射文件(DirectByteBuffer)或pageCache(FileChannel#map)该过程中开始持有锁的时间戳,具体的代码请参考:CommitLog#putMessage。
diff 一次消息追加过程中持有锁的总时长,即往内存映射文件或pageCache追加一条消息所耗时间。
代码@2:如果一次消息追加过程的时间超过了Broker配置文件osPageCacheBusyTimeOutMills,则认为pageCache繁忙,osPageCacheBusyTimeOutMills默认值为1000,表示1s。
DefaultMessageStore#isTransientStorePoolDeficient
public boolean isTransientStorePoolDeficient() {
return remainTransientStoreBufferNumbs() == 0;
}
public int remainTransientStoreBufferNumbs() {
return this.transientStorePool.remainBufferNumbs();
}最终调用TransientStorePool#remainBufferNumbs方法。
public int remainBufferNumbs() {
if (storeConfig.isTransientStorePoolEnable()) {
return availableBuffers.size();
}
return Integer.MAX_VALUE;
}如果启用transientStorePoolEnable机制,返回当前可用的ByteBuffer个数,即整个isTransientStorePoolDeficient方法的用意是是否还存在可用的ByteBuffer,如果不存在,即表示pageCache繁忙。那什么是transientStorePoolEnable机制呢?
Java NIO的内存映射机制,提供了将文件系统中的文件映射到内存机制,实现对文件的操作转换对内存地址的操作,极大的提高了IO特性,但这部分内存并不是常驻内存,可以被置换到交换内存(虚拟内存),RocketMQ为了提高消息发送的性能,引入了内存锁定机制,即将最近需要操作的commitlog文件映射到内存,并提供内存锁定功能,确保这些文件始终存在内存中,该机制的控制参数就是transientStorePoolEnable。
重点关注MappedFile的ByteBuffer writeBuffer、MappedByteBuffer mappedByteBuffer这两个属性的初始化,因为这两个方法是写消息与查消息操作的直接数据结构。 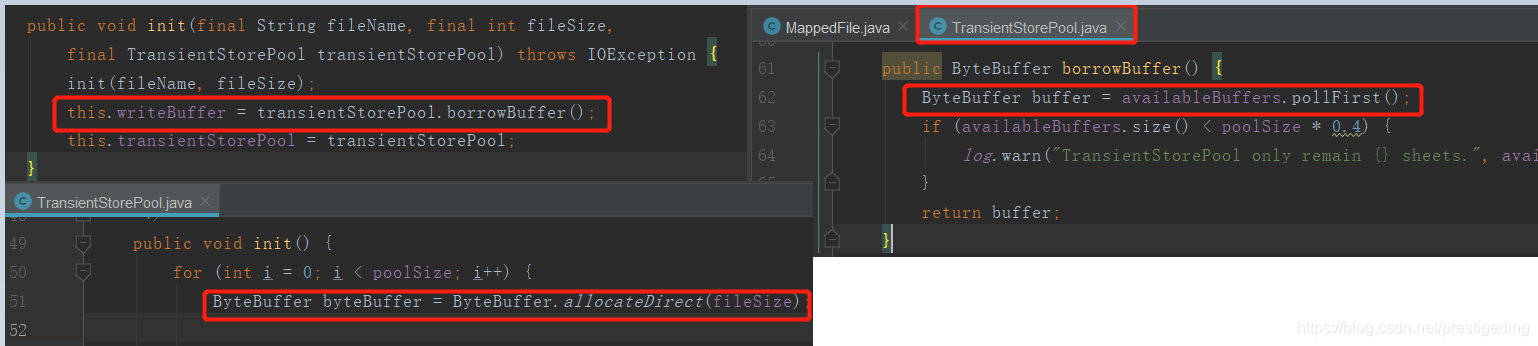
两个关键点如下:
ByteBuffer writeBuffer 如果开启了transientStorePoolEnable,则使用ByteBuffer.allocateDirect(fileSize),创建(java.nio的内存映射机制)。如果未开启,则为空。
MappedByteBuffer mappedByteBuffer 使用FileChannel#map方法创建,即真正意义上的PageCache。
消息写入时: MappedFile#appendMessagesInner 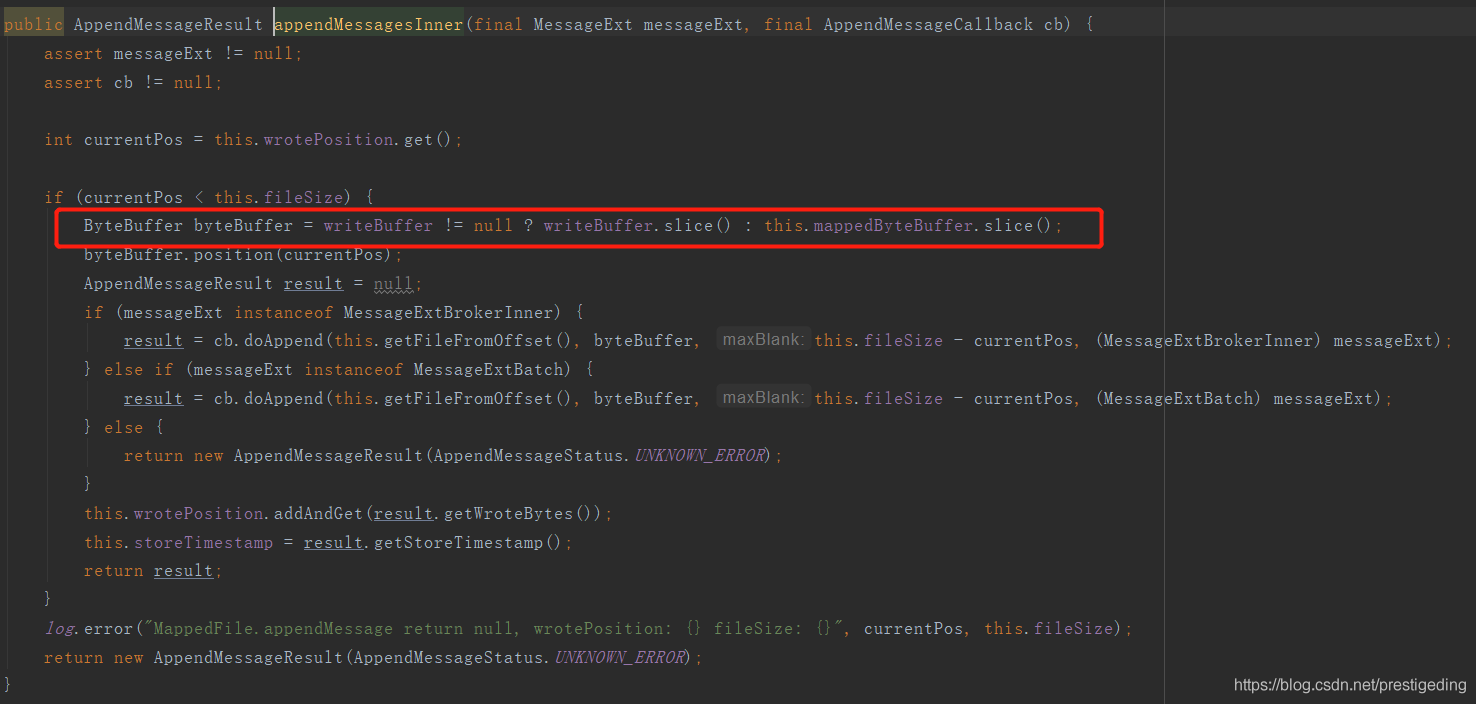
从中可见,在消息写入时,如果writerBuffer不为空,说明开启了transientStorePoolEnable机制,则消息首先写入writerBuffer中,如果其为空,则写入mappedByteBuffer中。
消息拉取(读消息): MappedFile#selectMappedBuffer 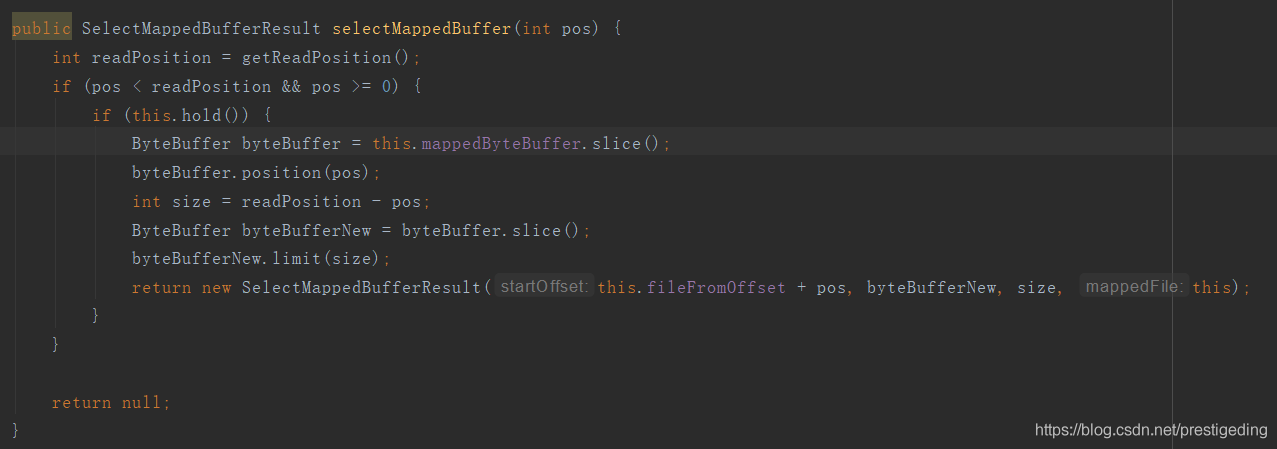
消息读取时,是从mappedByteBuffer中读(pageCache)。
大家是不是发现了一个有趣的点,如果开启transientStorePoolEnable机制,是不是有了读写分离的效果,先写入writerBuffer中,读却是从mappedByteBuffer中读取。
为了对transientStorePoolEnable引入意图阐述的更加明白,这里我引入Rocketmq社区贡献者胡宗棠关于此问题的见解。
通常有如下两种方式进行读写:
第一种,Mmap+PageCache的方式,读写消息都走的是pageCache,这样子读写都在pagecache里面不可避免会有锁的问题,在并发的读写操作情况下,会出现缺页中断降低,内存加锁,污染页的回写。
第二种,DirectByteBuffer(堆外内存)+PageCache的两层架构方式,这样子可以实现读写消息分离,写入消息时候写到的是DirectByteBuffer——堆外内存中,读消息走的是PageCache(对于,DirectByteBuffer是两步刷盘,一步是刷到PageCache,还有一步是刷到磁盘文件中),带来的好处就是,避免了内存操作的很多容易堵的地方,降低了时延,比如说缺页中断降低,内存加锁,污染页的回写。
温馨提示:如果想与胡宗棠大神进一步沟通交流,可以关注他的github账号:https://github.com/zongtanghu
不知道大家会不会有另外一个担忧,如果开启了transientStorePoolEnable,内存锁定机制,那是不是随着commitlog文件的不断增加,最终导致内存溢出?
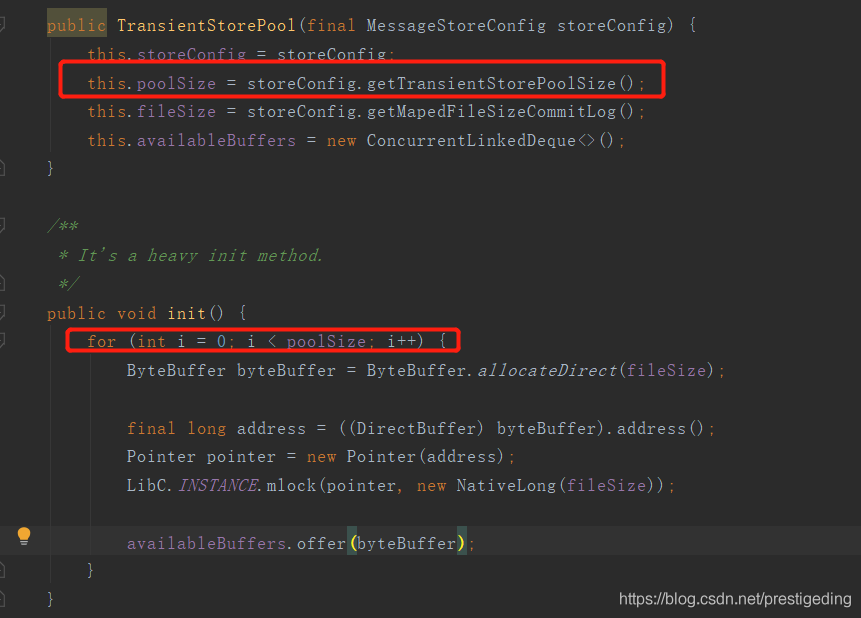
从这里可以看出,TransientStorePool默认会初始化5个DirectByteBuffer(对外内存),并提供内存锁定功能,即这部分内存不会被置换,可以通过transientStorePoolSize参数控制。
在消息写入消息时,首先从池子中获取一个DirectByteBuffer进行消息的追加。当5个DirectByteBuffer全部写满消息后,该如何处理呢?从RocketMQ的设计中来看,同一时间,只会对一个commitlog文件进行顺序写,写完一个后,继续创建一个新的commitlog文件。故TransientStorePool的设计思想是循环利用这5个DirectByteBuffer,只需要写入到DirectByteBuffer的内容被提交到PageCache后,即可重复利用。对应的代码如下: TransientStorePool#returnBuffer
public void returnBuffer(ByteBuffer byteBuffer) {
byteBuffer.position(0);
byteBuffer.limit(fileSize);
this.availableBuffers.offerFirst(byteBuffer);
}其调用栈如下: 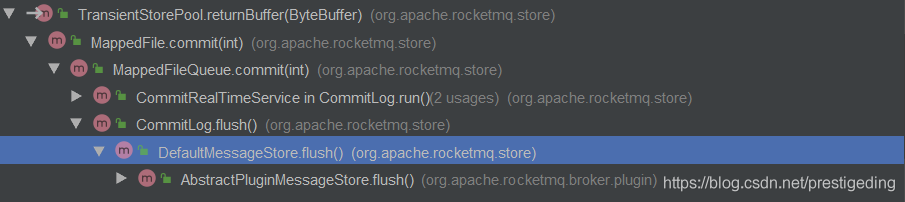
从上面的分析看来,并不会随着消息的不断写入而导致内存溢出。

其抛出的源码入口点:NettyRemotingAbstract#processRequestCommand,上面的原理分析部分已经详细介绍其实现原理,总结如下。
在不开启transientStorePoolEnable机制时,如果Broker PageCache繁忙时则抛出上述错误,判断PageCache繁忙的依据就是向PageCache追加消息时,如果持有锁的时间超过1s,则会抛出该错误;在开启transientStorePoolEnable机制时,其判断依据是如果TransientStorePool中不存在可用的堆外内存时抛出该错误。
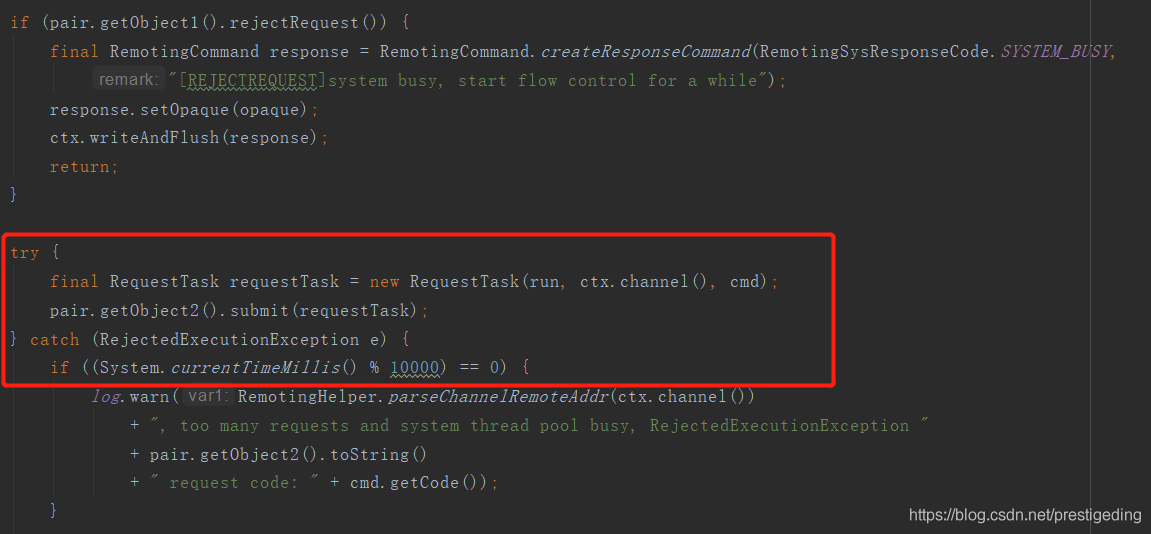
其抛出的源码入口点:NettyRemotingAbstract#processRequestCommand,其调用地方紧跟3.1,是在向线程池执行任务时,被线程池拒绝执行时抛出的,我们可以顺便看看Broker消息处理发送的线程信息: BrokerController#registerProcessor 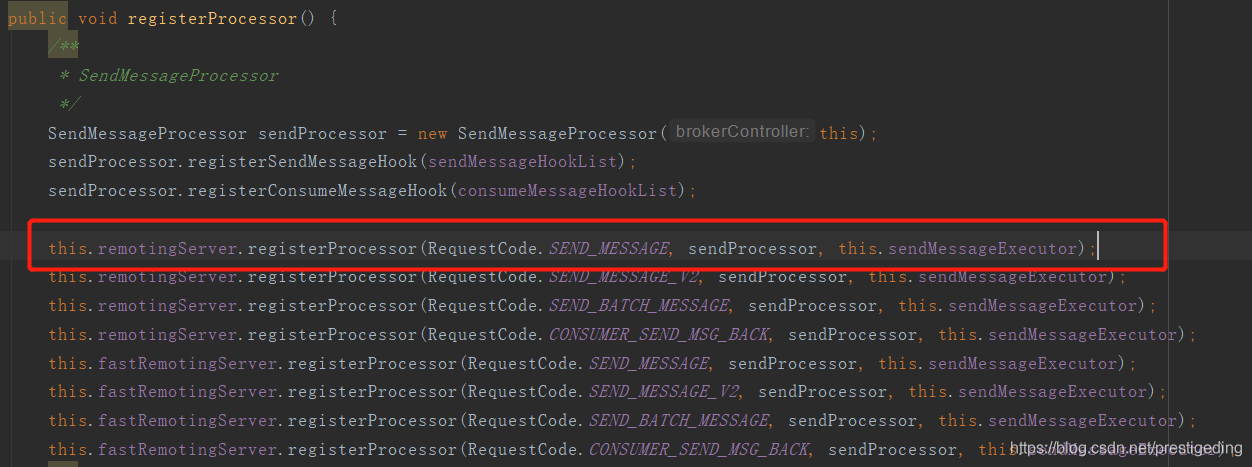
该线程池的队列长度默认为10000,我们可以通过sendThreadPoolQueueCapacity来改变默认值。

其抛出的源码入口点:DefaultMessageStore#putMessage,在进行消息追加时,再一次判断PageCache是否繁忙,如果繁忙,则抛出上述错误。
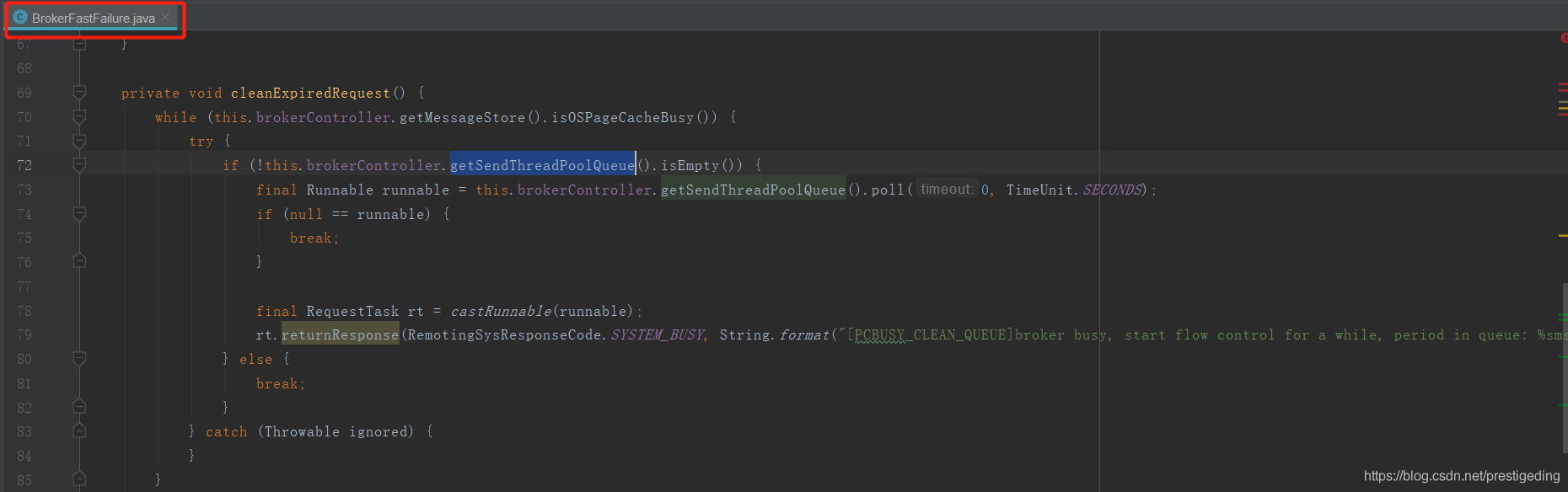
其抛出源码的入口点:BrokerFastFailure#cleanExpiredRequest。该方法的调用频率为每隔10s中执行一次,不过有一个执行前提条件就是Broker端要开启快速失败,默认为开启,可以通过参数brokerFastFailureEnable来设置。该方法的实现要点是每隔10s,检测一次,如果检测到PageCache繁忙,并且发送队列中还有排队的任务,则直接不再等待,直接抛出系统繁忙错误,使正在排队的线程快速失败,结束等待。
经过上面的原理讲解与现象分析,消息发送时抛出system busy、broker busy的原因都是PageCache繁忙,那是不是可以通过调整上述提到的某些参数来避免抛出错误呢?.例如如下参数:
osPageCacheBusyTimeOutMills 设置PageCache系统超时的时间,默认为1000,表示1s,那是不是可以把增加这个值,例如设置为2000或3000。作者观点:非常不可取。
sendThreadPoolQueueCapacity Broker服务器处理的排队队列,默认为10000,如果队列中积压了10000个请求,则会抛出RejectExecutionException。作者观点:不可取。
brokerFastFailureEnable 是否启用快速失败,默认为true,表示当如果发现Broker服务器的PageCache繁忙,如果发现sendThreadPoolQueue队列中不为空,表示还有排队的发送请求在排队等待执行,则直接结束等待,返回broker busy。那如果不开启快速失败,则同样可以避免抛出这个错误。作者观点:非常不可取。
修改上述参数,都不可取,原因是出现system busy、broker busy这个错误,其本质是系统的PageCache繁忙,通俗一点讲就是向PageCache追加消息时,单个消息发送占用的时间超过1s了,如果继续往该Broker服务器发送消息并等待,其TPS根本无法满足,哪还是高性能的消息中间了呀。故才会采用快速失败机制,直接给消息发送者返回错误,消息发送者默认情况会重试2次,将消息发往其他Broker,保证其高可用。
下面根据个人的见解,提出如下解决办法:
在broker.config中将transientStorePoolEnable=true。
方案依据: 启用“读写”分离,消息发送时消息先追加到DirectByteBuffer(堆外内存)中,然后在异步刷盘机制下,会将DirectByteBuffer中的内容提交到PageCache,然后刷写到磁盘。消息拉取时,直接从PageCache中拉取,实现了读写分离,减轻了PageCaceh的压力,能从根本上解决该问题。
方案缺点: 会增加数据丢失的可能性,如果Broker JVM进程异常退出,提交到PageCache中的消息是不会丢失的,但存在堆外内存(DirectByteBuffer)中但还未提交到PageCache中的这部分消息,将会丢失。但通常情况下,RocketMQ进程退出的可能性不大。
方案依据:
当Broker服务器自身比较忙的时候,快速失败,并且在接下来的一段时间内会规避该Broker,这样该Broker恢复提供了时间保证,Broker本身的架构是支持分布式水平扩容的,增加Topic的队列数,降低单台Broker服务器的负载,从而避免出现PageCache。 > 温馨提示:在Broker扩容时候,可以复制集群中任意一台Broker服务下${ROCKETMQ_HOME}/store/config/topics.json到新Broker服务器指定目录,避免在新Broker服务器上为Broker创建队列,然后消息发送者、消息消费者都能动态获取Topic的路由信息。
与之扩容对应的,也可以通过对原有Broker进行升配,例如增加内存、把机械盘换成SSD,但这种情况,通常需要重启Broekr服务器,没有扩容来的方便。
感谢各位的阅读,以上就是“RocketMQ消息发送出现system busy、broker busy的原因与解决方案”的内容了,经过本文的学习后,相信大家对RocketMQ消息发送出现system busy、broker busy的原因与解决方案这一问题有了更深刻的体会,具体使用情况还需要大家实践验证。这里是亿速云,小编将为大家推送更多相关知识点的文章,欢迎关注!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





