PythonзәҝзЁӢзј–зЁӢдёӯзҡ„ThreadиҜҘеҰӮдҪ•зҗҶи§Ј
PythonзәҝзЁӢзј–зЁӢдёӯзҡ„ThreadиҜҘеҰӮдҪ•зҗҶи§ЈпјҢй’ҲеҜ№иҝҷдёӘй—®йўҳпјҢиҝҷзҜҮж–Үз« иҜҰз»Ҷд»Ӣз»ҚдәҶзӣёеҜ№еә”зҡ„еҲҶжһҗе’Ңи§Јзӯ”пјҢеёҢжңӣеҸҜд»Ҙеё®еҠ©жӣҙеӨҡжғіи§ЈеҶіиҝҷдёӘй—®йўҳзҡ„е°ҸдјҷдјҙжүҫеҲ°жӣҙз®ҖеҚ•жҳ“иЎҢзҡ„ж–№жі•гҖӮ
дёҖгҖҒзәҝзЁӢзј–зЁӢ(Thread)
1гҖҒзәҝзЁӢеҹәжң¬жҰӮеҝө
1.1гҖҒд»Җд№ҲдәӢзәҝзЁӢ
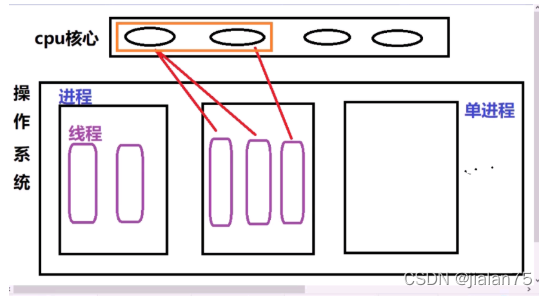
зәҝзЁӢиў«з§°дёәиҪ»йҮҸзә§зҡ„иҝӣзЁӢ
зәҝзЁӢд№ҹеҸҜд»ҘдҪҝз”Ёи®Ўз®—жңәеӨҡж ёиө„жәҗ,жҳҜеӨҡд»»еҠЎзј–зЁӢж–№ејҸ
зәҝзЁӢжҳҜзі»з»ҹеҲҶй…ҚеҶ…ж ёзҡ„жңҖе°ҸеҚ•е…ғ
зәҝзЁӢеҸҜд»ҘзҗҶи§ЈдёәиҝӣзЁӢзҡ„еҲҶж”Ҝд»»еҠЎ
1.2гҖҒзәҝзЁӢзү№еҫҒ
дёҖдёӘиҝӣзЁӢдёӯеҸҜд»ҘеҢ…еҗ«еӨҡдёӘзәҝзЁӢ
зәҝзЁӢд№ҹжҳҜдёҖдёӘиҝҗиЎҢиЎҢдёә,ж¶ҲиҖ—и®Ўз®—жңәиө„жәҗ
дёҖдёӘзәҝзЁӢдёӯзҡ„жүҖжңүзәҝзЁӢе…ұдә«иҝҷдёӘиҝӣзЁӢзҡ„иө„жәҗ
еӨҡдёӘзәҝзЁӢд№Ӣй—ҙзҡ„иҝҗиЎҢдә’дёҚеҪұе“Қеҗ„иҮӘиҝҗиЎҢ
зәҝзЁӢзҡ„еҲӣе»әе’Ңй”ҖжҜҒж¶ҲиҖ—иө„жәҗиҝңе°ҸдәҺиҝӣзЁӢ
еҗ„дёӘзәҝзЁӢд№ҹжңүиҮӘе·ұзҡ„IDзӯүзү№еҫҒ
дәҢгҖҒthreadingжЁЎеқ—еҲӣе»әзәҝзЁӢ
1гҖҒеҲӣе»әзәҝзЁӢеҜ№иұЎ
from threading import Thread
t = Thread()
еҠҹиғҪ: еҲӣе»әзәҝзЁӢеҜ№иұЎ
еҸӮж•°: target з»‘е®ҡзәҝзЁӢеҮҪж•°
args е…ғз»„ з»ҷзәҝзЁӢеҮҪж•°дҪҚзҪ®дј еҸӮ
kwargs еӯ—е…ё з»ҷзәҝзЁӢеҮҪж•°й”®еҖјдј еҸӮ
2гҖҒ еҗҜеҠЁзәҝзЁӢ
t.start()
3гҖҒ еӣһ收зәҝзЁӢ
t.join([timeout])
4гҖҒд»Јз Ғжј”зӨә
"""
thread1.py зәҝзЁӢеҹәзЎҖдҪҝз”Ё
жӯҘйӘӨ:
1. е°ҒиЈ…зәҝзЁӢеҮҪж•°
2.еҲӣе»әзәҝзЁӢеҜ№иұЎ
3.еҗҜеҠЁзәҝзЁӢ
4.еӣһ收зәҝзЁӢ
"""
import os
from threading import Thread
from time import sleep
a = 1
# зәҝзЁӢеҮҪж•°
def music():
for i in range(3):
sleep(2)
print('ж’ӯж”ҫ:й»„жІіеӨ§еҗҲе”ұ %s' % os.getpid())
global a
print("a,",a)
a = 1000
# еҲӣе»әзәҝзЁӢеҜ№иұЎ
t = Thread(target=music)
# еҗҜеҠЁзәҝзЁӢ
t.start()
for i in range(3):
sleep(1)
print('ж’ӯж”ҫ:beauty love %s' % os.getpid())
# еӣһ收зәҝзЁӢ
t.join()
print('зЁӢеәҸз»“жқҹ')
print("a,", a)5гҖҒзәҝзЁӢеҜ№иұЎеұһжҖ§
1.t.name зәҝзЁӢеҗҚз§°
2.t.setName() и®ҫзҪ®зәҝзЁӢеҗҚз§°
3.t.getName()иҺ·еҸ–зәҝзЁӢеҗҚз§°
4.t.is_alive() жҹҘзңӢзәҝзЁӢжҳҜеҗҰеңЁз”ҹе‘Ҫе‘Ёжңҹ
5.t.daemon и®ҫзҪ®дё»зәҝзЁӢе’ҢеҲҶж”ҜзәҝзЁӢйҖҖеҮәеҲҶж”ҜзәҝзЁӢд№ҹйҖҖеҮә.иҰҒеңЁstartеүҚи®ҫзҪ® йҖҡеёёдёҚе’Ңjoin дёҖиө·дҪҝз”Ё
6.д»Јз Ғжј”зӨә
"""
thread3.py
зәҝзЁӢеұһжҖ§жј”зӨә
"""
from threading import Thread
from time import sleep
def fun():
sleep(3)
print('зәҝзЁӢеұһжҖ§жөӢиҜ•')
t = Thread(target=fun, name='ceshi')
# дё»зәҝзЁӢйҖҖеҮәеҲҶж”ҜзәҝзЁӢд№ҹйҖҖеҮә еҝ…йЎ»еңЁstartеүҚдҪҝз”Ё дёҺjoin жІЎжңүж„Ҹд№ү
t.setDaemon(True)
t.start()
print(t.getName())
t.setName('Tedu')
print('is alive:', t.is_alive())
print('daemon', t.daemon)6гҖҒиҮӘе®ҡд№үзәҝзЁӢзұ»
1.еҲӣе»әжӯҘйӘӨ
1.继жүҝThreadзұ»
2.йҮҚеҶҷ __init__ж–№жі•ж·»еҠ иҮӘе·ұзҡ„еұһжҖ§ дҪҝз”ЁsuperеҠ иҪҪзҲ¶зұ»еұһжҖ§
3.йҮҚеҶҷrunж–№жі•
2.дҪҝз”Ёж–№жі•
1.е®һдҫӢеҢ–еҜ№иұЎ
2.и°ғдҪЈstartиҮӘеҠЁжү§иЎҢrunж–№жі•
3.и°ғдҪЈjoinеӣһ收зәҝзЁӢ
д»Јз Ғжј”зӨә
"""
иҮӘе®ҡд№үзәҝзЁӢзұ»дҫӢеӯҗ
"""
from threading import Thread
# иҮӘе®ҡд№үзәҝзЁӢзұ»
class ThreadClass(Thread):
# йҮҚеҶҷзҲ¶зұ» init
def __init__(self, *args, **kwargs):
self.attr = args[0]
# еҠ иҪҪзҲ¶зұ»init
super().__init__()
# еҒҮи®ҫйңҖиҰҒеҫҲеӨҡжӯҘйӘӨе®ҢжҲҗеҠҹиғҪ
def f1(self):
print('1')
def f2(self):
print(2)
# йҮҚеҶҷrun йҖ»иҫ‘и°ғдҪЈ
def run(self):
self.f1()
self.f2()
t = ThreadClass()
t.start()
t.join()7гҖҒдёҖдёӘеҫҲйҮҚиҰҒзҡ„з»ғд№ жҲ‘еҫҲеӨҡдёҚжҮӮ
from threading import Thread
from time import sleep, ctime
class MyThread(Thread):
def __init__(self, group=None, target=None, name=None,
args=(), kwargs=None, *, daemon=None):
super().__init__()
self.fun = target
self.args = args
self.kwargs = kwargs
def run(self):
self.fun(*self.args, **self.kwargs)
def player(sec, song):
for i in range(3):
print("Playing %s : %s" % (song, ctime()))
sleep(sec)
t = MyThread(target=player, args=(3,), kwargs={'song': 'йҮҸйҮҸ'})
t.start()
t.join()8гҖҒзәҝзЁӢй—ҙйҖҡдҝЎ
1.йҖҡдҝЎж–№жі•
1.зәҝзЁӢй—ҙдҪҝз”Ёе…ЁеұҖйҒҚеҺҶиҝӣиЎҢйҖҡдҝЎ
2.е…ұдә«иө„жәҗдәүеӨә
1.е…ұдә«иө„жәҗ:еӨҡдёӘиҝӣзЁӢжҲ–иҖ…зәҝзЁӢйғҪеҸҜд»Ҙж“ҚдҪңзҡ„иө„жәҗз§°дёәе…ұдә«иө„жәҗ,еҜ№е…ұдә«иө„жәҗзҡ„ж“ҚдҪңд»Јз Ғж®өз§°дёәдёҙз•ҢеҢә
2.еҪұе“Қ:еҜ№е…¬е…ұиө„жәҗзҡ„ж— еәҸж“ҚдҪңеҸҜиғҪдјҡеёҰжқҘж•°жҚ®зҡ„ж··д№ұ,жҲ–иҖ…ж“ҚдҪңй”ҷиҜҜ.жӯӨж—¶еҫҖеҫҖйңҖиҰҒеҗҢжӯҘдә’ж–ҘжңәеҲ¶еҚҸи°ғж“ҚдҪңйЎәеәҸ
3.еҗҢжӯҘдә’ж–ҘжңәеҲ¶
1.еҗҢжӯҘ:еҗҢжӯҘжҳҜдёҖз§ҚеҚҸдҪңе…ізі»,дёәе®ҢжҲҗж“ҚдҪң,еӨҡиҝӣзЁӢжҲ–иҖ…зәҝзЁӢеҪўжҲҗдёҖз§ҚеҚҸи°ғ,жҢүз…§еҝ…иҰҒзҡ„жӯҘйӘӨжңүеәҸжү§иЎҢж“ҚдҪң
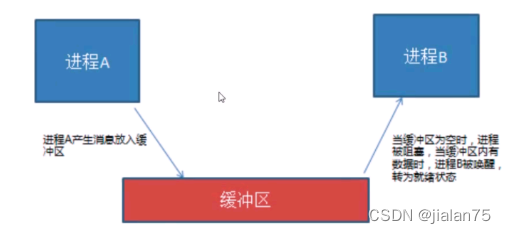
2.дә’ж–Ҙ:дә’ж–ҘжҳҜдёҖз§ҚеҲ¶зәҰе…ізі»,еҪ“дёҖдёӘиҝӣзЁӢжҲ–иҖ…зәҝзЁӢеҚ жңүиө„жәҗж—¶,дјҡиҝӣиЎҢеҠ й”ҒеӨ„зҗҶ,жӯӨж—¶е…¶е®ғиҝӣзЁӢзәҝзЁӢе°ұж— жі•ж“ҚдҪңиҜҘиө„жәҗ,зӣҙеҲ°и§Јй”ҒеҗҺжүҚиғҪж“ҚдҪң
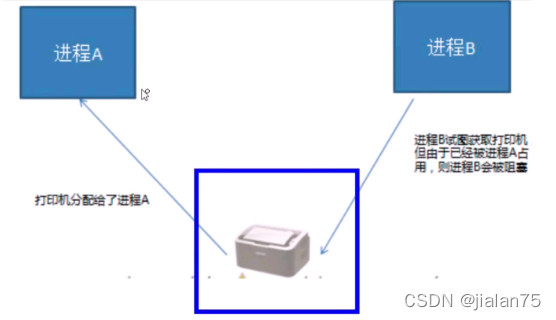
## 9.зәҝзЁӢеҗҢжӯҘдә’ж–Ҙж–№жі•
1. зәҝзЁӢEvent д»Јз Ғжј”зӨә
from threading import Event
# еҲӣе»әзәҝзЁӢeventеҜ№иұЎ
e = Event()
# йҳ»еЎһзӯүеҫ…eиў«set
e.wait([timeout])
# и®ҫзҪ®e, дҪҝwaitз»“жқҹйҳ»еЎһ
e.set()
# дҪҝeеӣһеҲ°жңӘиў«и®ҫзҪ®зҠ¶жҖҒ
e.clear()
# жҹҘзңӢеҪ“еүҚeжҳҜеҗҰиў«и®ҫзҪ®
e.is_set()
"""
event зәҝзЁӢдә’ж–Ҙж–№жі•жј”зӨә
"""
from threading import Event, Thread
s = None # з”ЁдәҺйҖҡдҝЎ
e = Event()
def yzr():
print('жқЁеӯҗиҚЈеүҚжқҘжӢңеұұеӨҙ')
global s
s = 'еӨ©зҺӢзӣ–ең°иҷҺ'
e.set() #ж“ҚдҪңе®Ңе…ұдә«иө„жәҗ eи®ҫзҪ®
t = Thread(target=yzr)
t.start()
print('иҜҙеҜ№еҸЈд»Өе°ұжҳҜиҮӘе·ұдәә')
e.wait() #йҳ»еЎһзӯүеҫ… e.set()
if s == 'еӨ©зҺӢзӣ–ең°иҷҺ':
print('е®қеЎ”й•ҮжІіеҰ–')
print('зЎ®и®ӨиҝҮзңјзҘһ,дҪ жҳҜеҜ№зҡ„дәә')
e.clear()
else:
print('жү“жӯ»д»–...')
t.join()
print('зЁӢеәҸз»“жқҹ')2. зәҝзЁӢй”Ғ Lockд»Јз Ғжј”зӨә
from threading import Lock
lock = Lock()еҲӣе»әй”ҒеҜ№иұЎ
lock.acquire() дёҠй”Ғ еҰӮжһңlockе·Із»ҸдёҠй”ҒеҶҚи°ғз”Ёдјҡйҳ»еЎһ
lock.release() и§Јй”Ғ
with lock: дёҠй”Ғ
....
....
with д»Јз Ғеқ—и§Јй”ҒиҮӘеҠЁи§Јй”Ғ
"""
thread_lock
зәҝзЁӢй”Ғжј”зӨә
"""
from threading import Thread, Lock
a = b = 0
lock = Lock()
def value():
while True:
# дёҠй”Ғ
lock.acquire()
print('a=%d,b=%d' % (a, b)) if a != b else print('aдёҚзӯүдәҺb')
# и§Јй”Ғ
lock.release()
t = Thread(target=value)
t.start()
while True:
# with ејҖе§ӢдёҠй”Ғ
with lock:
a += 1
b += 1
# with и§Јй”Ғ иҮӘеҠЁи§Јй”Ғ
t.join()
print('зЁӢеәҸз»“жқҹ')10гҖҒжӯ»й”ҒеҸҠе…¶еӨ„зҗҶ
1.е®ҡд№ү
жӯ»й”ҒжҳҜжҢҮдёӨдёӘжҲ–иҖ…дёӨдёӘд»ҘдёҠзҡ„зәҝзЁӢеңЁжү§иЎҢиҝҮзЁӢдёӯ,з”ұдәҺз«һдәүиө„жәҗжҲ–иҖ…з”ұдәҺеҪјжӯӨйҖҡдҝЎиҖҢйҖ жҲҗзҡ„дёҖз§Қйҳ»еЎһзҡ„зҺ°иұЎ,иӢҘж— еӨ–еҠӣдҪңз”Ё,他们йғҪе°Ҷж— жі•жҺЁиҝӣдёӢеҺ».жӯӨж—¶з§°зі»з»ҹеӨ„дәҺжӯ»й”ҒзҠ¶жҖҒжҲ–зі»з»ҹдә§з”ҹдәҶжӯ»й”Ғ.
2.еӣҫи§Ј

3. жӯ»й”Ғдә§з”ҹжқЎд»¶
жӯ»й”ҒеҸ‘з”ҹзҡ„еҝ…иҰҒжқЎд»¶
дә’ж–ҘжқЎд»¶пјҡжҢҮзәҝзЁӢеҜ№жүҖеҲҶй…ҚеҲ°зҡ„иө„жәҗиҝӣиЎҢжҺ’е®ғжҖ§дҪҝз”ЁпјҢеҚіеңЁдёҖж®өж—¶й—ҙеҶ…жҹҗиө„жәҗеҸӘз”ұдёҖдёӘиҝӣзЁӢеҚ з”ЁгҖӮеҰӮжһңжӯӨж—¶иҝҳжңүе…¶е®ғиҝӣзЁӢиҜ·жұӮиө„жәҗпјҢеҲҷиҜ·жұӮиҖ…еҸӘиғҪзӯүеҫ…пјҢзӣҙиҮіеҚ жңүиө„жәҗзҡ„иҝӣзЁӢз”ЁжҜ•йҮҠж”ҫгҖӮ
иҜ·жұӮе’ҢдҝқжҢҒжқЎд»¶пјҡжҢҮзәҝзЁӢе·Із»ҸдҝқжҢҒиҮіе°‘дёҖдёӘиө„жәҗпјҢдҪҶеҸҲжҸҗеҮәдәҶж–°зҡ„иө„жәҗиҜ·жұӮпјҢиҖҢиҜҘиө„жәҗе·Іиў«е…¶е®ғиҝӣзЁӢеҚ жңүпјҢжӯӨж—¶иҜ·жұӮзәҝзЁӢйҳ»еЎһпјҢдҪҶеҸҲеҜ№иҮӘе·ұе·ІиҺ·еҫ—зҡ„е…¶е®ғиө„жәҗдҝқжҢҒдёҚж”ҫгҖӮ
дёҚеүҘеӨәжқЎд»¶пјҡжҢҮзәҝзЁӢе·ІиҺ·еҫ—зҡ„иө„жәҗпјҢеңЁжңӘдҪҝз”Ёе®Ңд№ӢеүҚпјҢдёҚиғҪиў«еүҘеӨәпјҢеҸӘиғҪеңЁдҪҝз”Ёе®Ңж—¶з”ұиҮӘе·ұйҮҠж”ҫ,йҖҡеёёCPUеҶ…еӯҳиө„жәҗжҳҜеҸҜд»Ҙиў«зі»з»ҹејәиЎҢи°ғй…ҚеүҘеӨәзҡ„гҖӮ
зҺҜи·Ҝзӯүеҫ…жқЎд»¶пјҡжҢҮеңЁеҸ‘з”ҹжӯ»й”Ғж—¶пјҢеҝ…然еӯҳеңЁдёҖдёӘзәҝзЁӢвҖ”вҖ”иө„жәҗзҡ„зҺҜеҪўй“ҫпјҢеҚіиҝӣзЁӢйӣҶеҗҲ{T0пјҢT1пјҢT2пјҢВ·В·В·пјҢTn}дёӯзҡ„T0жӯЈеңЁзӯүеҫ…дёҖдёӘT1еҚ з”Ёзҡ„иө„жәҗпјӣT1жӯЈеңЁзӯүеҫ…T2еҚ з”Ёзҡ„иө„жәҗпјҢвҖҰвҖҰпјҢTnжӯЈеңЁзӯүеҫ…е·Іиў«T0еҚ з”Ёзҡ„иө„жәҗгҖӮ
жӯ»й”Ғзҡ„дә§з”ҹеҺҹеӣ
з®ҖеҚ•жқҘиҜҙйҖ жҲҗжӯ»й”Ғзҡ„еҺҹеӣ еҸҜд»ҘжҰӮжӢ¬жҲҗдёүеҸҘиҜқпјҡ
еҪ“еүҚзәҝзЁӢжӢҘжңүе…¶д»–зәҝзЁӢйңҖиҰҒзҡ„иө„жәҗ
еҪ“еүҚзәҝзЁӢзӯүеҫ…е…¶д»–зәҝзЁӢе·ІжӢҘжңүзҡ„иө„жәҗ
йғҪдёҚж”ҫејғиҮӘе·ұжӢҘжңүзҡ„иө„жәҗ
еҰӮдҪ•йҒҝе…Қжӯ»й”Ғ
жӯ»й”ҒжҳҜжҲ‘们йқһеёёдёҚж„ҝж„ҸзңӢеҲ°зҡ„дёҖз§ҚзҺ°иұЎпјҢжҲ‘们иҰҒе°ҪеҸҜиғҪйҒҝе…Қжӯ»й”Ғзҡ„жғ…еҶөеҸ‘з”ҹгҖӮйҖҡиҝҮи®ҫзҪ®жҹҗдәӣйҷҗеҲ¶жқЎд»¶пјҢеҺ»з ҙеқҸдә§з”ҹжӯ»й”Ғзҡ„еӣӣдёӘеҝ…иҰҒжқЎд»¶дёӯзҡ„дёҖдёӘжҲ–иҖ…еҮ дёӘпјҢжқҘйў„йҳІеҸ‘з”ҹжӯ»й”ҒгҖӮйў„йҳІжӯ»й”ҒжҳҜдёҖз§Қиҫғжҳ“е®һзҺ°зҡ„ж–№жі•гҖӮдҪҶжҳҜз”ұдәҺжүҖж–ҪеҠ зҡ„йҷҗеҲ¶жқЎд»¶еҫҖеҫҖеӨӘдёҘж јпјҢеҸҜиғҪдјҡеҜјиҮҙзі»з»ҹиө„жәҗеҲ©з”ЁзҺҮгҖӮ
4.жӯ»й”Ғд»Јз Ғжј”зӨә
from time import sleep
from threading import Thread, Lock
# дәӨжҳ“зұ»
class Account:
def __init__(self, _id, balance, lock):
# з”ЁжҲ·
self._id = _id
# еӯҳж¬ҫ
self.balance = balance
# й”Ғ
self.lock = lock
# еҸ–й’ұ
def withdraw(self, amount):
self.balance -= amount
# еӯҳй’ұ
def deposit(self, amount):
self.balance += amount
# дҪҷйўқ
def get_balance(self):
return self.balance
Tom = Account('Tom', 5000, Lock())
Alex = Account('Alex', 8000, Lock())
def transfer(from_, to, amount):
# й”ҒдҪҸиҮӘе·ұиҙҰжҲ·
if from_.lock.acquire():
# иҙҰжҲ·еҮҸе°‘
from_.withdraw(amount)
sleep(0.5)
if to.lock.acquire():
to.deposit(amount)
to.lock.release()
from_.lock.release()
print('иҪ¬иҙҰе®ҢжҲҗ %sз»ҷ%sиҪ¬иҙҰ%d' % (from_._id, to._id, amount))
# transfer(Tom, Alex, 1000)
t1 = Thread(target=transfer, args=(Tom, Alex, 2000))
t2 = Thread(target=transfer, args=(Alex, Tom, 3500))
t1.start()
t2.start()
t1.join()
t2.join()
print('зЁӢеәҸз»“жқҹ')pythonзәҝзЁӢGIL
1.pythonзәҝзЁӢзҡ„GILй—®йўҳ пјҲе…ЁеұҖи§ЈйҮҠеҷЁй”Ғпјү
д»Җд№ҲжҳҜGIL пјҡз”ұдәҺpythonи§ЈйҮҠеҷЁи®ҫи®ЎдёӯеҠ е…ҘдәҶи§ЈйҮҠеҷЁй”ҒпјҢеҜјиҮҙpythonи§ЈйҮҠеҷЁеҗҢдёҖж—¶еҲ»еҸӘиғҪи§ЈйҮҠжү§иЎҢдёҖдёӘзәҝзЁӢпјҢеӨ§еӨ§йҷҚдҪҺдәҶзәҝзЁӢзҡ„жү§иЎҢж•ҲзҺҮгҖӮ
еҜјиҮҙеҗҺжһңпјҡ еӣ дёәйҒҮеҲ°йҳ»еЎһж—¶зәҝзЁӢдјҡдё»еҠЁи®©еҮәи§ЈйҮҠеҷЁпјҢеҺ»и§ЈйҮҠе…¶д»–зәҝзЁӢгҖӮжүҖд»ҘpythonеӨҡзәҝзЁӢеңЁжү§иЎҢеӨҡйҳ»еЎһй«ҳ延иҝҹIOж—¶еҸҜд»ҘжҸҗеҚҮзЁӢеәҸж•ҲзҺҮпјҢе…¶д»–жғ…еҶө并дёҚиғҪеҜ№ж•ҲзҺҮжңүжүҖжҸҗеҚҮгҖӮ
GILй—®йўҳе»әи®®
еңЁж— йҳ»еЎһзҠ¶жҖҒдёӢпјҢеӨҡзәҝзЁӢзЁӢеәҸе’ҢеҚ•зәҝзЁӢзЁӢеәҸжү§иЎҢж•ҲзҺҮеҮ д№Һе·®дёҚеӨҡпјҢз”ҡиҮіиҝҳдёҚеҰӮеҚ•зәҝзЁӢж•ҲзҺҮгҖӮдҪҶжҳҜеӨҡиҝӣзЁӢиҝҗиЎҢзӣёеҗҢеҶ…е®№еҚҙеҸҜд»ҘжңүжҳҺжҳҫзҡ„ж•ҲзҺҮжҸҗеҚҮгҖӮ
е…ідәҺPythonзәҝзЁӢзј–зЁӢдёӯзҡ„ThreadиҜҘеҰӮдҪ•зҗҶи§Јй—®йўҳзҡ„и§Јзӯ”е°ұеҲҶдә«еҲ°иҝҷйҮҢдәҶпјҢеёҢжңӣд»ҘдёҠеҶ…е®№еҸҜд»ҘеҜ№еӨ§е®¶жңүдёҖе®ҡзҡ„её®еҠ©пјҢеҰӮжһңдҪ иҝҳжңүеҫҲеӨҡз–‘жғ‘жІЎжңүи§ЈејҖпјҢеҸҜд»Ҙе…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“дәҶи§ЈжӣҙеӨҡзӣёе…ізҹҘиҜҶгҖӮ





