这篇文章主要介绍了victoriaMetrics代理性能优化问题怎么解决的相关知识,内容详细易懂,操作简单快捷,具有一定借鉴价值,相信大家阅读完这篇victoriaMetrics代理性能优化问题怎么解决文章都会有所收获,下面我们一起来看看吧。
最近有做一个Prometheus metrics代理的一个小项目,暂称为prom-proxy,目的是为了解析特定的指标(如容器、traefik、istio等指标),然后在原始指标中加入应用ID(当然还有其他指标操作,暂且不表)。经过简单的本地验证,就发布到联调环境,跑了几个礼拜一切正常,以为相安无事。但自以为没事不代表真的没事。
昨天突然老环境和新上prom-proxy的环境都出现了数据丢失的情况,如下图:
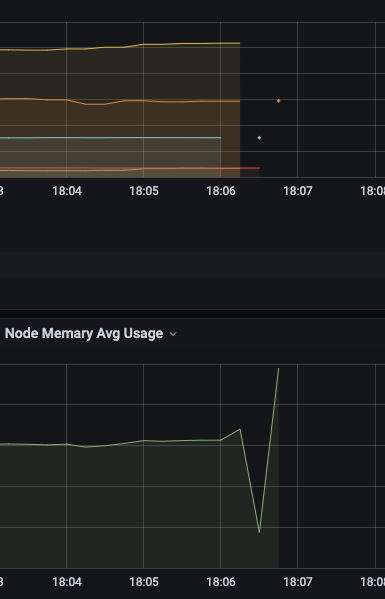
prom-proxy有一个自服务指标request_total,经观察发现,该指标增长极慢,因而一开始怀疑是发送端的问题(这是一个误区,后面会讲为何要增加缓存功能)。
进一步排查,发现上游发送端(使用的是victoriaMetrics的vmagent组件)出现了如下错误,说明是prom-proxy消费的数据跟不上vmagent产生的数据:
2022-03-24T09:55:49.945Z warn VictoriaMetrics/app/vmagent/remotewrite/client.go:277 couldn't send a block with size 370113 bytes to "1:secret-url": Post "xxxx": context deadline exceeded (Client.Timeout exceeded while awaiting headers); re-sending the block in 16.000 seconds
出现这种问题,首先想到的是增加并发处理功能。当前的并发处理数为8(即后台的goroutine数目),考虑到线上宿主机的core有30+,因此直接将并发处理数拉到30。经验证发现毫无改善。
另外想到的一种方式是缓存,如使用kafka或使用golang自带的缓存chan。但使用缓存也有问题,如果下游消费能力一直跟不上,缓存中将会产生大量积压的数据,且Prometheus监控指标具有时效性,积压过久的数据,可用性并不高又浪费存储空间。
下面是使用了缓存chan的例子,s.reqChan的初始大小设置为5000,并使用cacheTotal指标观察缓存的变更。这种方式下,数据接收和处理变为了异步(但并不完全异步)。
上面一开始有讲到使用request_total查看上游的请求是个误区,是因为请求统计和请求处理是同步的,因此如果请求没有处理完,就无法接收下一个请求,request_total也就无法增加。
func (s *Server) injectLabels(w http.ResponseWriter, r *http.Request) {
data, _ := DecodeWriteRequest(r.Body)
s.reqChan <- data
cacheTotal.Inc()
w.WriteHeader(http.StatusNoContent)
}
func (s *Server) Start() {
go func() {
for data := range s.reqChan {
cacheTotal.Dec()
processor := s.pool.GetWorkRequest()
go func() {
processor.JobChan <- data
res := <-processor.RetChan
if 0 != len(res.errStr) {
log.Errorf("err msg:%s,err.code:%d", res.errStr, res.statusCode)
return
}
}()
}
}()
}上线后观察发现cacheTotal的统计增加很快,说明之前就是因为处理能力不足导致request_total统计慢。
至此似乎陷入了一个死胡同。多goroutine和缓存都是不可取的。
回顾一下,prom-proxy中处理了cadvisor、kube-state-metrics、istio和traefik的指标,同时在处理的时候做了自监控,统计了各个类型的指标。例如:
prom-proxy_metrics_total{kind="container"} 1.0396728e+07
prom-proxy_metrics_total{kind="istio"} 620414
prom-proxy_metrics_total{kind="total"} 2.6840415e+07在cacheTotal迅猛增加的同时,发现request_total增长极慢(表示已处理的请求),且istio类型的指标处理速率很慢,,而container类型的指标处理速度则非常快。这是一个疑点。
vmagent的一个请求中可能包含上千个指标,可能会混合各类指标,如容器指标、网关指标、中间件指标等等。
通过排查istio指标处理的相关代码,发现有三处可以优化:
更精确地匹配需要处理的指标:之前是通过前缀通配符匹配的,经过精确匹配之后,相比之前处理的指标数下降了一半。
代码中有重复写入指标的bug:这一处IO操作耗时极大
将写入指标操作放到独立的goroutine pool中,独立于标签处理
经过上述优化,上线后发现缓存为0,性能达标!
一开始在开发完prom-proxy之后也做了简单的benchmark测试,但考虑到是在办公网验证的,网速本来就慢,因此注释掉了写入指标的代码,初步验证性能还算可以就结束了,没想到埋了一个深坑。
所以所有功能都需要覆盖验证,未验证的功能点都有可能是坑!
服务中必须增加必要的自监控指标:对于高频率请求的服务,增加请求缓存机制,即便不能削峰填谷,也可以作为一个监控指标(通过Prometheus metric暴露的),用于观察是否有请求积压;此外由于很多线上环境并不能直接到宿主机进行操作,像获取火焰图之类的方式往往不可行,此时指标就可以作为一个参考模型。
进行多维度度、全面的benchmark:代码性能分为计算型和IO型。前者是算法问题,后者则涉及的问题比较多,如网络问题、并发不足的问题、使用了阻塞IO等。在进行benchmark的时候可以将其分开验证,即注释掉可能耗时的IO操作,首先验证计算型的性能,在计算型性能达标时启用IO操作,进一步做全面的benchmark验证。
喜闻乐见的后续来了。。。
由于公司有两个大的线上集群,暂称为more集群和less集群,很不幸,性能达标的就是less集群的,其指标数据相比more集群来说非常less,大概是前者的十分之一。上到more集群之后服务内存直接达到50G,多个副本一起吃内存,直接将节点搞挂了。
迫不得已(又是那句话,感觉对了的点往往不对),重新做了pprof压力测试,发现内存黑洞就是下面这个函数(来自Prometheus),即便在办公电脑下进行压测,其内存使用仍然达到好几百M。该函数主要是读取vmagent传来的请求,首先进行snappy.Decode解码,然后unmarshal到临时变量wr中。低流量下完全没有问题,但高流量下完全无法应对:
func DecodeWriteRequest(r io.Reader) (*ReqData, error) {
compressed, err := ioutil.ReadAll(r)
if err != nil {
return nil, err
}
reqBuf, err := snappy.Decode(nil, compressed)
if err != nil {
return nil, err
}
var wr prompb.WriteRequest
if err := proto.Unmarshal(reqBuf, &wr); err != nil {
return nil, err
}
return &ReqData{
reqBuf: reqBuf,
wr: &wr,
}, nil
}解决办法就是拿出sync.pool大杀器,下面方式参考了victoriaMetrics的byteutil库(代码路径lib/byteutil),有兴趣的可以去看下,经过压测,相同测试情况下内存降到了不足100M。
func DecodeWriteRequest(r io.Reader, callback func(*prompb.WriteRequest)) error {
ctx := getPushCtx(r)
defer putPushCtx(ctx)
if err := ctx.Read(); err != nil {
return err
}
bb := bodyBufferPool.Get()
defer bodyBufferPool.Put(bb)
var err error
bb.B, err = snappy.Decode(bb.B[:cap(bb.B)], ctx.reqBuf.B)
if err != nil {
return err
}
wr := getWriteRequest()
defer putWriteRequest(wr)
if err := wr.Unmarshal(bb.B); err != nil {
return err
}
callback(wr)
return nil
}这样一来性能完全达标,10core下单pod每秒可以处理250w个指标!
重新发布线上,自然又出问题了,这次prom-proxy服务一切正常,但导致后端vmstorage(victoriametrics的存储服务)内存爆满。经过初步定位,是由于出现了slow insert,即出现大量 active time series导致缓存miss,进而导致内存暴增(prom-proxy服务会在原始指标中增加标签,并创建其他新的指标,这两类指标数目非常庞大,都属于active time series)。
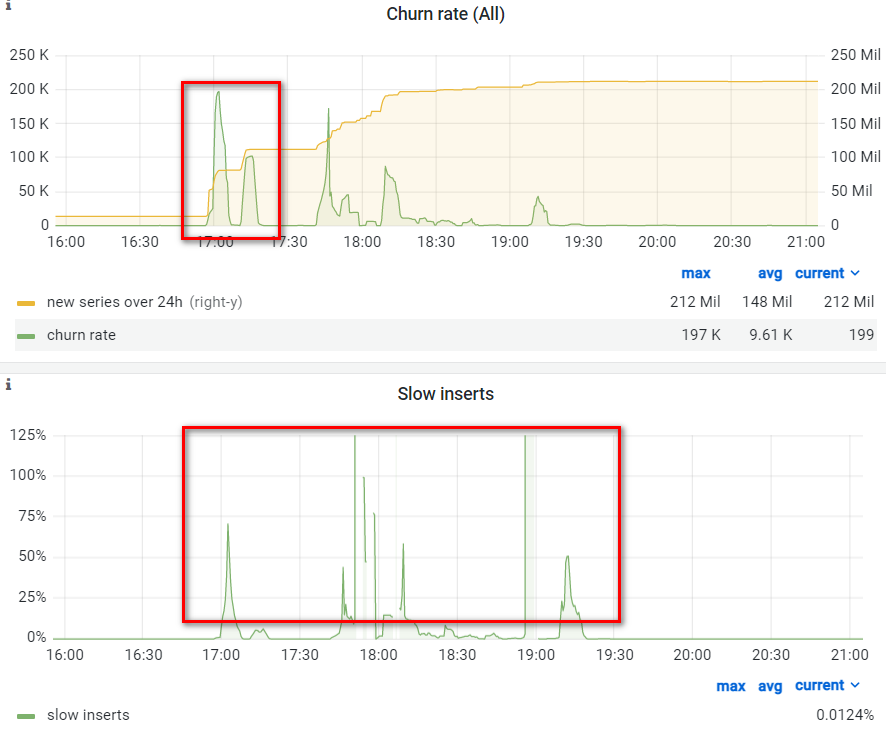
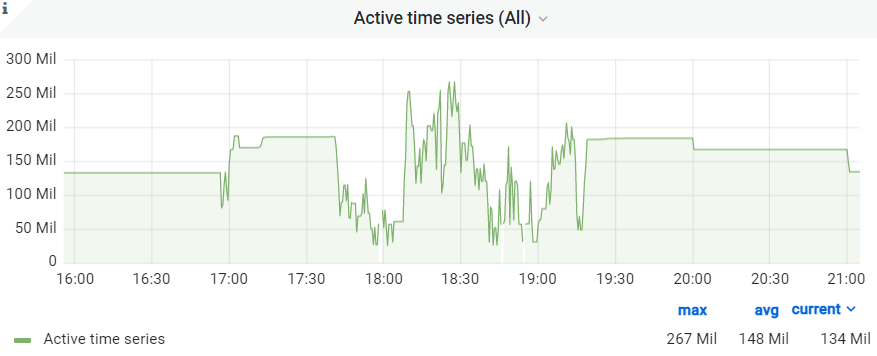
最终的解决方式是将修改的指标作分类,并支持配置化启用,即如果修改的指标类型有:A、B、C、D四类。首先上线A,然后上线B,以此类推,让vmstorage逐步处理active time series,以此减少对后端存储的瞬时压力。
vmstorage有一个参数:--storage.maxDailySeries,它可以限制active time series的数目。但环境中正常情况下就有大量active time serials,如果设置了这个参数,新增的active time serials极有可能会挤掉老的active time serials,造成老数据丢失。
关于“victoriaMetrics代理性能优化问题怎么解决”这篇文章的内容就介绍到这里,感谢各位的阅读!相信大家对“victoriaMetrics代理性能优化问题怎么解决”知识都有一定的了解,大家如果还想学习更多知识,欢迎关注亿速云行业资讯频道。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





