这篇“python怎么实现多线程并得到返回值”文章的知识点大部分人都不太理解,所以小编给大家总结了以下内容,内容详细,步骤清晰,具有一定的借鉴价值,希望大家阅读完这篇文章能有所收获,下面我们一起来看看这篇“python怎么实现多线程并得到返回值”文章吧。
# -*- coding:utf-8 -*-
"""
作者:wyt
日期:2022年04月21日
"""
import threading
import requests
import time
urls = [
f'https://www.cnblogs.com/#p{page}' # 待爬地址
for page in range(1, 10) # 爬取1-10页
]
def craw(url):
r = requests.get(url)
num = len(r.text) # 爬取博客园当页的文字数
return num # 返回当页文字数
def sigle(): # 单线程
res = []
for i in urls:
res.append(craw(i))
return res
class MyThread(threading.Thread): # 重写threading.Thread类,加入获取返回值的函数
def __init__(self, url):
threading.Thread.__init__(self)
self.url = url # 初始化传入的url
def run(self): # 新加入的函数,该函数目的:
self.result = craw(self.url) # ①。调craw(arg)函数,并将初试化的url以参数传递——实现爬虫功能
# ②。并获取craw(arg)函数的返回值存入本类的定义的值result中
def get_result(self): #新加入函数,该函数目的:返回run()函数得到的result
return self.result
def multi_thread():
print("start")
threads = [] # 定义一个线程组
for url in urls:
threads.append( # 线程组中加入赋值后的MyThread类
MyThread(url) # 将每一个url传到重写的MyThread类中
)
for thread in threads: # 每个线程组start
thread.start()
for thread in threads: # 每个线程组join
thread.join()
list = []
for thread in threads:
list.append(thread.get_result()) # 每个线程返回结果(result)加入列表中
print("end")
return list # 返回多线程返回的结果组成的列表
if __name__ == '__main__':
start_time = time.time()
result_multi = multi_thread()
print(result_multi) # 输出返回值-列表
# result_sig = sigle()
# print(result_sig)
end_time = time.time()
print('用时:', end_time - start_time)单线程:
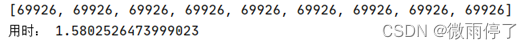
多线程:
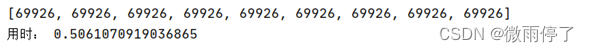
加速效果明显。
import threading
import requests
import time
urls = [
f'https://www.cnblogs.com/#p{page}' # 待爬地址
for page in range(1, 10) # 爬取1-10页
]
def craw(url):
r = requests.get(url)
num = len(r.text) # 爬取博客园当页的文字数
print(num)
def sigle(): # 单线程
res = []
for i in urls:
res.append(craw(i))
return res
def multi_thread():
print("start")
threads = [] # 定义一个线程组
for url in urls:
threads.append(
threading.Thread(target=craw,args=(url,)) # 注意args=(url,),元组
)
for thread in threads: # 每个线程组start
thread.start()
for thread in threads: # 每个线程组join
thread.join()
print("end")
if __name__ == '__main__':
start_time = time.time()
result_multi = multi_thread()
# result_sig = sigle()
# print(result_sig)
end_time = time.time()
print('用时:', end_time - start_time)返回:
start
69915
69915
69915
69915
69915
69915
69915
69915
69915
end
用时: 0.316709041595459
import time
from threading import Thread
def foo(number):
time.sleep(1)
return number
class MyThread(Thread):
def __init__(self, number):
Thread.__init__(self)
self.number = number
def run(self):
self.result = foo(self.number)
def get_result(self):
return self.result
if __name__ == '__main__':
thd1 = MyThread(3)
thd2 = MyThread(5)
thd1.start()
thd2.start()
thd1.join()
thd2.join()
print(thd1.get_result())
print(thd2.get_result())返回:
3
5
多线程入口
threading.Thread(target=craw,args=(url,)) # 注意args=(url,),元组多线程传参
需要重写一下threading.Thread类,加一个接收返回值的函数。 三、代码实战
使用这种带返回值的多线程技术重写了一下之前发布过的一个爬取子域名的代码,原始代码在这里:https://blog.csdn.net/qq_45859826/article/details/124030119
import threading
import requests
from bs4 import BeautifulSoup
from static.plugs.headers import get_ua
#https://cn.bing.com/search?q=site%3Abaidu.com&go=Search&qs=ds&first=20&FORM=PERE
def search_1(url):
Subdomain = []
html = requests.get(url, stream=True, headers=get_ua())
soup = BeautifulSoup(html.content, 'html.parser')
job_bt = soup.findAll('h3')
for i in job_bt:
link = i.a.get('href')
# print(link)
if link not in Subdomain:
Subdomain.append(link)
return Subdomain
class MyThread(threading.Thread):
def __init__(self, url):
threading.Thread.__init__(self)
self.url = url
def run(self):
self.result = search_1(self.url)
def get_result(self):
return self.result
def Bing_multi_thread(site):
print("start")
threads = []
for i in range(1, 30):
url = "https://cn.bing.com/search?q=site%3A" + site + "&go=Search&qs=ds&first=" + str(
(int(i) - 1) * 10) + "&FORM=PERE"
threads.append(
MyThread(url)
)
for thread in threads:
thread.start()
for thread in threads:
thread.join()
res_list = []
for thread in threads:
res_list.extend(thread.get_result())
res_list = list(set(res_list)) #列表去重
number = 1
for i in res_list:
number += 1
number_list = list(range(1, number + 1))
dict_res = dict(zip(number_list, res_list))
print("end")
return dict_res
if __name__ == '__main__':
print(Bing_multi_thread("qq.com"))返回:
{
1:'https://transmart.qq.com/index',
2:'https://wpa.qq.com/msgrd?v=3&uin=448388692&site=qq&menu=yes',
3:'https://en.exmail.qq.com/',
4:'https://jiazhang.qq.com/wap/com/v1/dist/unbind_login_qq.shtml?source=h6_wx',
5:'http://imgcache.qq.com/',
6:'https://new.qq.com/rain/a/20220109A040B600',
7:'http://cp.music.qq.com/index.html',
8:'http://s.syzs.qq.com/',
9:'https://new.qq.com/rain/a/20220321A0CF1X00',
10:'https://join.qq.com/about.html',
11:'https://live.qq.com/10016675',
12:'http://uni.mp.qq.com/',
13:'https://new.qq.com/omn/TWF20220/TWF2022042400147500.html',
14:'https://wj.qq.com/?from=exur#!',
15:'https://wj.qq.com/answer_group.html',
16:'https://view.inews.qq.com/a/20220330A00HTS00',
17:'https://browser.qq.com/mac/en/index.html',
18:'https://windows.weixin.qq.com/?lang=en_US',
19:'https://cc.v.qq.com/upload',
20:'https://xiaowei.weixin.qq.com/skill',
21:'http://wpa.qq.com/msgrd?v=3&uin=286771835&site=qq&menu=yes',
22:'http://huifu.qq.com/',
23:'https://uni.weixiao.qq.com/',
24:'http://join.qq.com/',
25:'https://cqtx.qq.com/',
26:'http://id.qq.com/',
27:'http://m.qq.com/',
28:'https://jq.qq.com/?_wv=1027&k=pevCjRtJ',
29:'https://v.qq.com/x/page/z0678c3ys6i.html',
30:'https://live.qq.com/10018921',
31:'https://m.campus.qq.com/manage/manage.html',
32:'https://101.qq.com/',
33:'https://new.qq.com/rain/a/20211012A0A3L000',
34:'https://live.qq.com/10021593',
35:'https://pc.weixin.qq.com/?t=win_weixin&lang=en',
36:'https://sports.qq.com/lottery/09fucai/cqssc.htm'
}
非常非常非常能感受到速度快了超级多,用这种方式爆破子域名也比较爽。没有多线程,我的项目里可能缺少了好几个功能:因为之前写过的一些程序都因执行时间过长被我砍掉。这个功能还是很实用的。
以上就是关于“python怎么实现多线程并得到返回值”这篇文章的内容,相信大家都有了一定的了解,希望小编分享的内容对大家有帮助,若想了解更多相关的知识内容,请关注亿速云行业资讯频道。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



