这篇“Python Pandas中DataFrame.drop_duplicates()怎么删除重复值”文章的知识点大部分人都不太理解,所以小编给大家总结了以下内容,内容详细,步骤清晰,具有一定的借鉴价值,希望大家阅读完这篇文章能有所收获,下面我们一起来看看这篇“Python Pandas中DataFrame.drop_duplicates()怎么删除重复值”文章吧。
df.drop_duplicates(subset = None,
keep = 'first',
inplace = False,
ignore_index = False)1.subset:指定的标签或标签序列,仅删除这些列重复值,默认情况为所有列
2.keep:确定要保留的重复值,有以下可选项:
first:保留第一次出现的重复值,默认
last:保留最后一次出现的重复值
False:删除所有重复值
3.inplace:是否生效
4.ignore_index:如果为True,则重新分配自然索引(0,1,…,n - 1)
# 删除重复值 DataFrame.drop_duplicates()
import pandas as pd
df = pd.DataFrame([['x','x',1],['x','x',1],['z','x',2]], columns = ['A','B','C'])
# 删除重复行
res1 = df.drop_duplicates()
# 删除指定列
res2 = df.drop_duplicates(subset = ['A'])
# 保留最后一个
res3 = df.drop_duplicates(subset = ['A'], keep = 'last')df
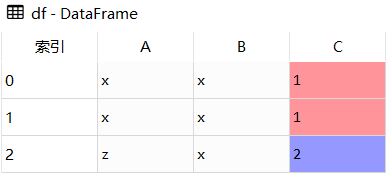
res1
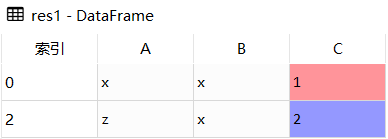
res2
res3

import pandas as pd
df = pd.DataFrame({
'studentID':['A001','A002','A003','A004','A005','A006','A006'],
'score':[100,93,94,96,93,95,95]})
# 识别重复值
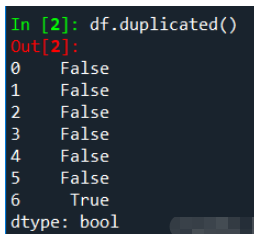
duplicate_value = df[df.duplicated()]df
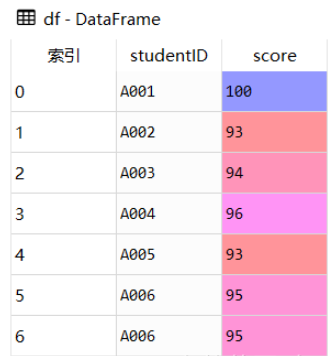
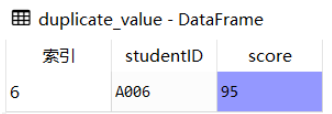
由上图可知studentID为'A006'的记录有两条,我们可以使用duplicated()方法识别重复值,它返回的是布尔值结果(True:有重复值,False:无重复值)
duplicate_value
以上就是关于“Python Pandas中DataFrame.drop_duplicates()怎么删除重复值”这篇文章的内容,相信大家都有了一定的了解,希望小编分享的内容对大家有帮助,若想了解更多相关的知识内容,请关注亿速云行业资讯频道。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



