今天小编给大家分享一下go map搬迁怎么实现的相关知识点,内容详细,逻辑清晰,相信大部分人都还太了解这方面的知识,所以分享这篇文章给大家参考一下,希望大家阅读完这篇文章后有所收获,下面我们一起来了解一下吧。
以下代码基于go1.17
桶用太多
go用了一个负载因子loadFactor来衡量。也就是如果数量count大于loadFactor * bucket数,那么就要扩容
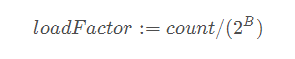
代码如下
const (
// Maximum number of key/elem pairs a bucket can hold.
bucketCntBits = 3
bucketCnt = 1 << bucketCntBits
// Maximum average load of a bucket that triggers growth is 6.5.
// Represent as loadFactorNum/loadFactorDen, to allow integer math.
loadFactorNum = 13
loadFactorDen = 2
)
// 在元素数量大于8且元素数量大于负载因子(6.5)*桶总数,就要进行扩容
func overLoadFactor(count int, B uint8) bool {
return count > bucketCnt && uintptr(count) > loadFactorNum*(bucketShift(B)/loadFactorDen)
}overflow太多
overflow太多在go中分两种情况
bucket数量小于1<<15时,overflow超过桶总数
bucket数量大于1<<15时,overflow超过1<<15
// overflow buckets 太多
func tooManyOverflowBuckets(noverflow uint16, B uint8) bool {
if B > 15 {
B = 15
}
return noverflow >= uint16(1)<<(B&15)
}准备搬迁工作是由hashGrow方法完成的,他主要就是进行申请新buckets空间、初始化搬迁进度为0、将原桶标记为旧桶等
func hashGrow(t *maptype, h *hmap) {
// 判断是bucket多还是overflow多,然后根据这两种情况去申请新buckets空间
bigger := uint8(1)
if !overLoadFactor(h.count+1, h.B) {
bigger = 0
h.flags |= sameSizeGrow
}
oldbuckets := h.buckets
newbuckets, nextOverflow := makeBucketArray(t, h.B+bigger, nil)
flags := h.flags &^ (iterator | oldIterator)
if h.flags&iterator != 0 {
flags |= oldIterator
}
// commit the grow (atomic wrt gc)
// 更新最新的bucket总数、将原桶标记为旧桶(后面判断是否在搬迁就是通过这个进行判断的)
h.B += bigger
h.flags = flags
h.oldbuckets = oldbuckets
h.buckets = newbuckets
// 初始化搬迁进度为0
h.nevacuate = 0
// 初始化新桶overflow数量为0
h.noverflow = 0
// 将原来extra的overflow挂载到old overflow,代表这已经是旧的了
if h.extra != nil && h.extra.overflow != nil {
// Promote current overflow buckets to the old generation.
if h.extra.oldoverflow != nil {
throw("oldoverflow is not nil")
}
h.extra.oldoverflow = h.extra.overflow
h.extra.overflow = nil
}
// extra指向下一块空闲的overflow空间
if nextOverflow != nil {
if h.extra == nil {
h.extra = new(mapextra)
}
h.extra.nextOverflow = nextOverflow
}
}正式搬迁其实是在添加、删除元素的时候顺便干的。在发现搬迁的时候,就可能会做一到两次的搬迁,每次搬迁一个bucket。具体是一次还是两次就是下面的逻辑决定的
搬迁正在使用的bucket对应old bucket(如果没有搬迁过的话)
若还正在搬迁就再搬一个以加快搬迁
func growWork(t *maptype, h *hmap, bucket uintptr) {
// make sure we evacuate the oldbucket corresponding
// to the bucket we're about to use
evacuate(t, h, bucket&h.oldbucketmask())
// evacuate one more oldbucket to make progress on growing
if h.growing() {
evacuate(t, h, h.nevacuate)
}
}对于不扩容的情况,可能只有一个——就是原来序号对应的桶(就是下面的x)。
对于扩容2倍的情况,显然既有可能是在原来序号对应桶,也有可能是原来序号加上扩容的桶数的序号
比如B由2变成了3,那么就要看hash第3bit到底是0还是1了,如果是001,那么和原来的一样,是序号为1的桶;如果是101,那么就是原来序号1+22 (扩容桶数)=序号为5的桶
// xy contains the x and y (low and high) evacuation destinations.
var xy [2]evacDst
x := &xy[0]
x.b = (*bmap)(add(h.buckets, oldbucket*uintptr(t.bucketsize)))
x.k = add(unsafe.Pointer(x.b), dataOffset)
x.e = add(x.k, bucketCnt*uintptr(t.keysize))
if !h.sameSizeGrow() {
// Only calculate y pointers if we're growing bigger.
// Otherwise GC can see bad pointers.
y := &xy[1]
// newBit在扩容的情况下等于1<<(B-1)
y.b = (*bmap)(add(h.buckets, (oldbucket+newbit)*uintptr(t.bucketsize)))
y.k = add(unsafe.Pointer(y.b), dataOffset)
y.e = add(y.k, bucketCnt*uintptr(t.keysize))
}每一个bucket在溢出之后都会附接overflow桶,每个bucket包括overflow储存着8个元素
若元素tophash为空,则表示被搬迁过,继续下一个
计算hash值
若超出当前bucket容量,就新建一个overflow bucket
将原来的key、value复制到新bucket新位置
定位到下一个元素
在上面的步骤计算hash值在overflow用太多的情况下是不用的
此外,在桶用太多的情况下,计算hash
for ; b != nil; b = b.overflow(t) {
// 找到key开始位置k,和value开始位置e
k := add(unsafe.Pointer(b), dataOffset)
e := add(k, bucketCnt*uintptr(t.keysize))
// 遍历bucket中元素进行搬迁
for i := 0; i < bucketCnt; i, k, e = i+1, add(k, uintptr(t.keysize)), add(e, uintptr(t.elemsize)) {
// 获取tophash,若发现是空,说明已经搬迁过。并标记为空且已搬迁
top := b.tophash[i]
if isEmpty(top) {
b.tophash[i] = evacuatedEmpty
continue
}
if top < minTopHash {
throw("bad map state")
}
k2 := k
// 若key为引用类型就解引用
if t.indirectkey() {
k2 = *((*unsafe.Pointer)(k2))
}
// X指的就是原序号桶
// Y指的就是扩容情况下,新的最高位为1的时候应该去的桶
var useY uint8
if !h.sameSizeGrow() {
// Compute hash to make our evacuation decision (whether we need
// to send this key/elem to bucket x or bucket y).
hash := t.hasher(k2, uintptr(h.hash0))
// 若正在迭代,且key为NaNs。是不是使用Y就取决最低位是不是1了
if h.flags&iterator != 0 && !t.reflexivekey() && !t.key.equal(k2, k2) {
useY = top & 1
top = tophash(hash)
} else {
// 如果最高位为1,那么就应该选Y桶
if hash&newbit != 0 {
useY = 1
}
}
}
if evacuatedX+1 != evacuatedY || evacuatedX^1 != evacuatedY {
throw("bad evacuatedN")
}
// 标记X还是Y搬迁,并依此获取到搬迁目标桶
b.tophash[i] = evacuatedX + useY
dst := &xy[useY]
// 若目标桶已经超出桶容量,就分配新overflow
if dst.i == bucketCnt {
dst.b = h.newoverflow(t, dst.b)
dst.i = 0
dst.k = add(unsafe.Pointer(dst.b), dataOffset)
dst.e = add(dst.k, bucketCnt*uintptr(t.keysize))
}
// 更新元素目标桶对应的tophash
// 采用与而非取模,应该是出于性能目的
dst.b.tophash[dst.i&(bucketCnt-1)] = top
// 复制key到目标桶
if t.indirectkey() {
*(*unsafe.Pointer)(dst.k) = k2 // copy pointer
} else {
typedmemmove(t.key, dst.k, k) // copy elem
}
// 复制value到目标桶
if t.indirectelem() {
*(*unsafe.Pointer)(dst.e) = *(*unsafe.Pointer)(e)
} else {
typedmemmove(t.elem, dst.e, e)
}
// 更新目标桶元素数量、key、value位置
dst.i++
// These updates might push these pointers past the end of the key or elem arrays.
// That's ok, as we have the overflow pointer at the end of the bucket to protect against pointing past the end of the bucket.
dst.k = add(dst.k, uintptr(t.keysize))
dst.e = add(dst.e, uintptr(t.elemsize))
}
}如果发现没有在使用旧buckets的就把原buckets中的key-value清理掉吧(tophash还是保留用来搬迁时判断状态)
// Unlink the overflow buckets & clear key/elem to help GC.
if h.flags&oldIterator == 0 && t.bucket.ptrdata != 0 {
// 计算当前原bucket所在的开始位置b
b := add(h.oldbuckets, oldbucket*uintptr(t.bucketsize))
// Preserve b.tophash because the evacuation
// state is maintained there.
// 从开始位置加上key-value的偏移量,那么ptr所在的位置就是实际key-value的开始位置
ptr := add(b, dataOffset)
// n是总bucket大小减去key-value的偏移量,就key-value占用空间的大小
n := uintptr(t.bucketsize) - dataOffset
// 清理从ptr开始的n个字节
memclrHasPointers(ptr, n)
}在本次搬迁进度是最新进度的情况下(不是最新就让最新的去干吧)
更新进度
尝试往后看1024个bucket,如果发现有搬迁完的,但是没更新进度就顺便帮别人更新了
若是全部bucket都完成搬迁了,那就直接将原buckets释放掉
func advanceEvacuationMark(h *hmap, t *maptype, newbit uintptr) {
// 更新进度
h.nevacuate++
// Experiments suggest that 1024 is overkill by at least an order of magnitude.
// Put it in there as a safeguard anyway, to ensure O(1) behavior.
// 向后看,更新已经完成的进度
stop := h.nevacuate + 1024
if stop > newbit {
stop = newbit
}
for h.nevacuate != stop && bucketEvacuated(t, h, h.nevacuate) {
h.nevacuate++
}
// 若是完成搬迁,就释放掉old buckets、重置搬迁状态、释放原bucket挂载到extra的overflow指针
if h.nevacuate == newbit { // newbit == # of oldbuckets
// Growing is all done. Free old main bucket array.
h.oldbuckets = nil
// Can discard old overflow buckets as well.
// If they are still referenced by an iterator,
// then the iterator holds a pointers to the slice.
if h.extra != nil {
h.extra.oldoverflow = nil
}
h.flags &^= sameSizeGrow
}
}以上就是“go map搬迁怎么实现”这篇文章的所有内容,感谢各位的阅读!相信大家阅读完这篇文章都有很大的收获,小编每天都会为大家更新不同的知识,如果还想学习更多的知识,请关注亿速云行业资讯频道。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://blog.csdn.net/iUcool/article/details/130161460



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



