博文结构
什么是正则表达式
基础正则表达式
延伸正则表达式
文件的格式化与相关处理
正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种过滤逻辑。
由于系统如果在繁忙的情况之下,每天产生的讯息信息会多到你无法想像的地步,而我们也都知道,系统的“错误讯息登录文件”的内容记载了系统产生的所有讯息,当然,这包含你的系统是否被“***”的记录数据
在编写处理字符串的程序时,经常会有查找符合某些复杂规则的字符串的需要。正则表达式就是用于描述这些规则的工具。换句话说,正则表达式就是记录文本规则的代码。
正则表达式与shell在linux当中的角色定位
不论是对于系统的认识与系统的管理部分
正则表达式的字串表示方式依照不同的严谨度而分为:基础正则表达式与延伸正则表达式。延伸型正则表达式除了简单的一组字串处理之外,还可以作群组的字串处理
1.语系对正则表达式的影响
zh_TW.big5 及 C 这两种语系的输出结果分别如下:
LANG=C 时:0 1 2 3 4 ... A B C D ... Z a b c d ...z
LANG=zh_TW 时:0 1 2 3 4 ... a A b B c C d D ... z Z
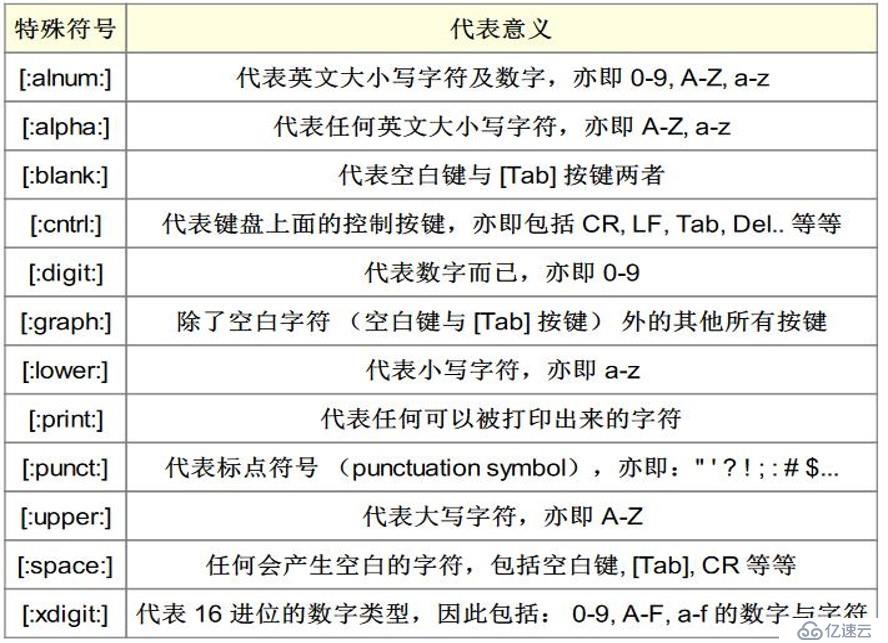
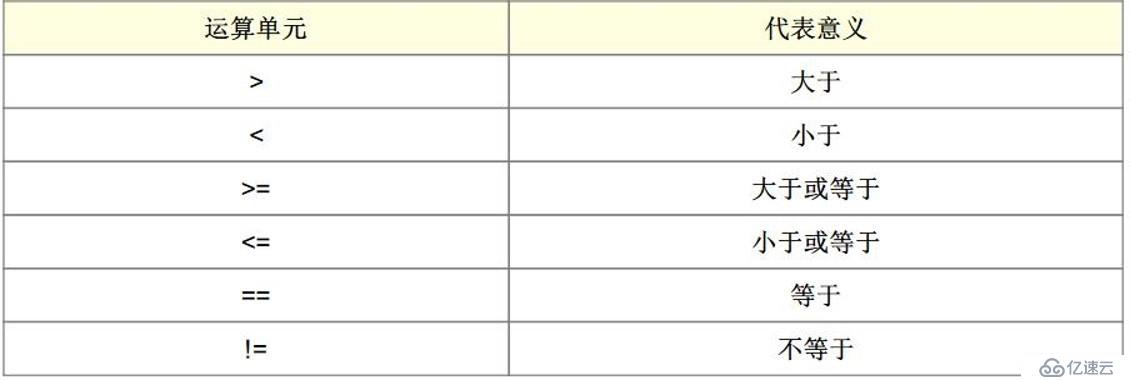
2.正则表达式有三部分组成:
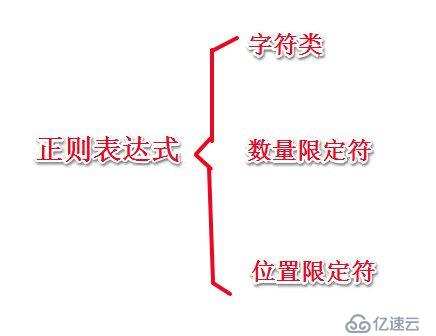
案例如下:
[root@localhost ~]# grep -n "the" /etc/man_db.conf
\\-n 显示行号 搜寻特定字符串
[root@localhost ~]# grep -vn 'the' /etc/man_db.conf
\\反转查找 意思就是查找不是‘the’的行显示出来
[root@localhost ~]# grep -in 'the' /etc/man_db.conf
\\取得不论大小写的 the 这个字串
[root@localhost ~]# grep -n 't[ae]se' /etc/man_db.conf
\\想要搜寻 test 或 tast 这两个单字时,可以发现到
[root@localhost ~]# grep -n '[^g]oo' /etc/man_db.conf
\\利用中括号【】来搜寻集合字符
\\^开头 $结束
[root@localhost ~]# grep -n '[0-9]' /etc/man_db.conf
\\取得有数字的那一行
[root@localhost ~]# grep -n '^the' /etc/man_db.conf
\\行首与行尾字符^ $
中括号内的^表示反向搜寻
中括号外的^表示以……开头
[root@localhost ~]# grep -n '^[a-z]' /etc/man_db.conf
\\查找开头为小写字母
[root@localhost ~]# grep -n '^[[:lower:]]' /etc/man_db.conf
\\这和上面一条一样都是显示小写字母,可以看上面那个图
[root@localhost ~]# grep -n '^[^a-zA-Z]' /etc/man_db.conf
\\不想要开头是英文字母
[root@localhost ~]# grep -n '\.$' /etc/man_db.conf
\\找出来,行尾结束为小数点(.)的那一行特别注意到,因为小数点具有其他意义所以必须要使用跳脱字符(\)来加以解除其特殊意义
Windows的断行字符。 (.^M$)
Linux的断行字符 . (.$)
**. (小数点):代表“一定有一个任意字符”的意思;
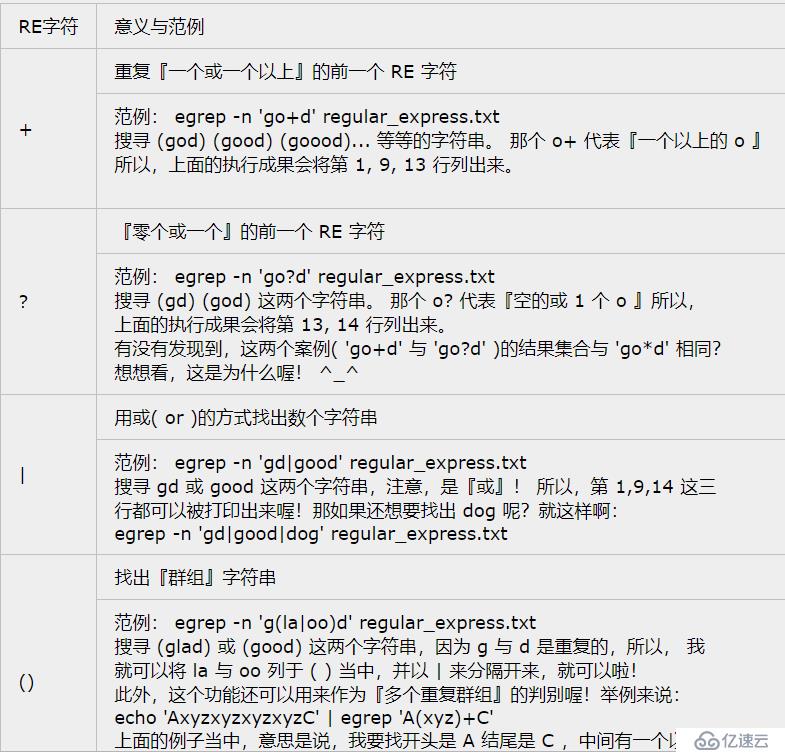
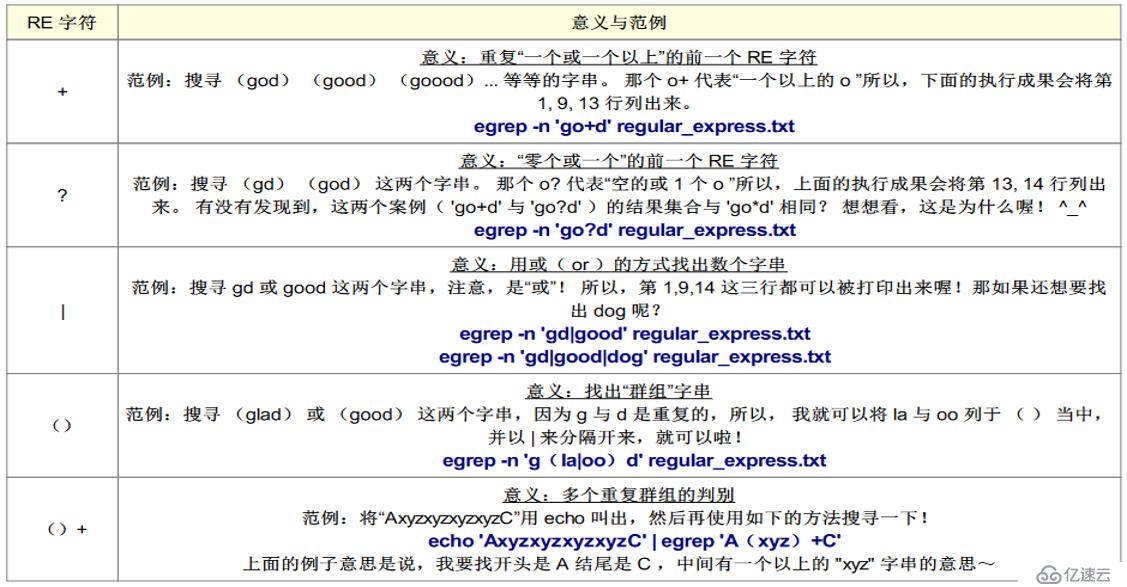
*(星星号):代表“重复前一个字符, 0 到无穷多次”的意思,为组合形态
**
[root@localhost ~]# grep -n 'g..d' /etc/man_db.conf
\\查找g??d共有四个字符开头为g,结尾为d
[root@localhost ~]# grep -n 'ooo*' /etc/man_db.conf
\\查找至少两个 o 以上的字串
\\注意,o*为一个单位,*代表重复前面的字母无限次
[root@localhost ~]# grep -n 'goo*g' /etc/man_db.conf
\\字串开头与结尾都是 g,但是两个 g 之间仅能存在至少一个 o
[root@localhost ~]# grep -n '[]0-9[0-9]*' /etc/man_db.conf
\\找出“任意数字”的行列[root@localhost ~]# grep -n 'go\{2,5\}g' /etc/man_db.conf
\\找出 g 后面接 2 到 5 个 o ,然后再接一个 g 的字串
[root@localhost ~]# grep -n 'go\{2,\}g' /etc/man_db.conf
\\找出2 个 o 以上的 goooo....g

注:“正则表达式的特殊字符”与一般在命令行输入指令的“万用字符”并不相同,例如,在万用字符当中的 代表的是“ 0 ~ 无限多个字符”的意思,但是在正则表达式当中, 则是“重复 0 到无穷多个的前一个 RE 字符”的意思~使用的意义并不相同,不要混了
语法如下:
[root@localhost ~]# ]sed [-nefr] [动作 ]选项与参数如下:
-n :使用安静(silent)模式。在一般sed的用法中,所有来自STDIN 的数据一般都会被列出到屏幕上。但如果加上-n参数后,则只有经过sed特殊处理的那一行(或者动作)才会被列出来。
-e :直接在命令行界面上进行sed的动作编辑;
-f :直接将sed的动作写在一一个文件内, -f filename 则可以执行filename 内的sed动作;
-r:sed的动作支持的是延伸型正则表达式的语法。(默认是基础正则表达式语法)
-i:直接修改读取的文件内容,而不是由屏幕输出。案例:
[root@localhost ~]# nl /etc/passwd | sed '2,5'd
\\删除2到5行内容
[root@localhost ~]# nl /etc/passwd | sed 'asd'
\\在所有后面行加上asd
[root@localhost ~]# nl /etc/passwd | sed '2a da ....\
aaa'
\\增将两行以上
[root@localhost ~]# nl /etc/passwd | sed '2,5c ccccccccccccc'
\\第2-5行的内容取代成为ccccccccc
[root@localhost ~]# nl /etc/passwd | sed -n '5,7p'
\\仅列出5到7行的内容部分数据的搜寻与取代的功能
sed 's/要被取代的字串/新的字串/g'
sed 的“ -i ”选项可以直接修改文件内容,
awk是一个强大的工具,相对于grep的查找,sed的编辑,awk在其对数据分析并生成报告时,显得尤为强大。简单来说awk就是把文件逐行的读入,以空格为默认分隔符将每行切片,切开的部分再进行各种分析处理。
语法如下:
[root@localhost ~]# awk '条 件类型1{动作1}条件类型2{动作2} .. ' filenamne[root@localhost ~]# last -n 5 | awk '{print $1 "\t" $3}'
\\取出帐号与登陆者的 IP ,且帐号与 IP 之间以 [tab] 隔开
**整个 awk 的处理流程是:
[root@localhost ~]# last -n 5 | awk '{print $1 "\t lines: "NR"\t columns: "NF}'
root lines: 1 columns: 10
root lines: 2 columns: 10
(unknown lines: 3 columns: 10
reboot lines: 4 columns: 11
root lines: 5 columns: 10
lines: 6 columns: 0
wtmp lines: 7 columns: 7
[root@localhost ~]#
\\在awk内的NR,NF等变量要用大写,且不需要$!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



