今天就跟大家聊聊有关如何利用pytorch自定义一个数据集,可能很多人都不太了解,为了让大家更加了解,小编给大家总结了以下内容,希望大家根据这篇文章可以有所收获。
自定义数据集
在训练深度学习模型之前,样本集的制作非常重要。在pytorch中,提供了一些接口和类,方便我们定义自己的数据集合,下面完整的试验自定义样本集的整个流程。
开发环境
实验目的
实验过程
1.收集图像样本
以简单的猫狗二分类为例,可以在网上下载一些猫狗图片。创建以下目录:

在test/train/val之下在校分别创建2个文件夹,dog, cat
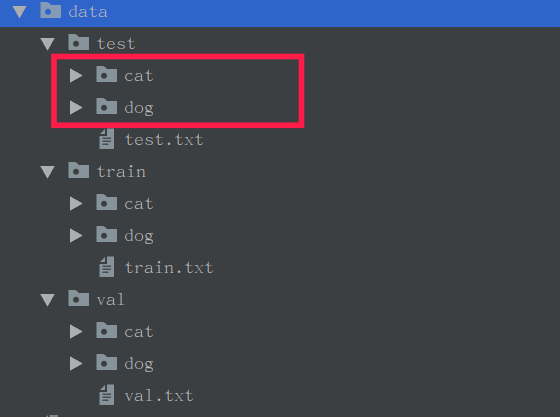
cat, dog文件夹下分别存放2类图像:

标签
| 种类 | 标签 |
|---|---|
| cat | 0 |
| dog | 1 |
之后写一个简单的python脚本,生成txt文件,用于指明每个图像和标签的对应关系。
格式: /cat/1.jpg 0 \n dog/1.jpg 1 \n .....
如图:
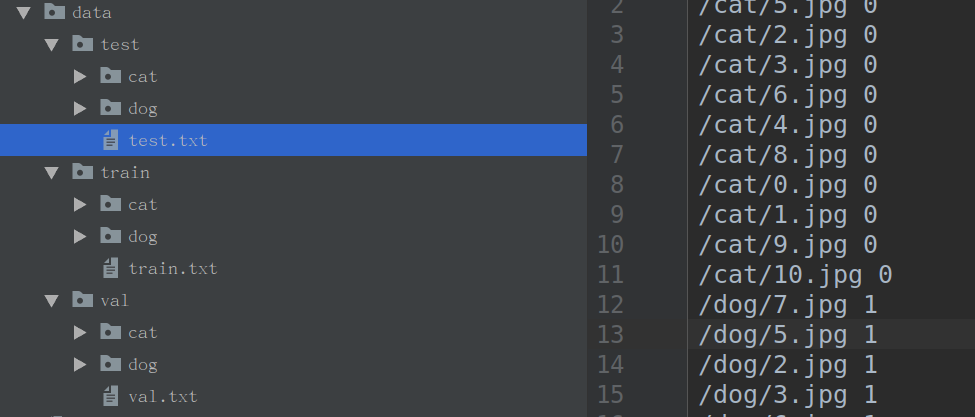
至此,样本集的收集以及简单归类完成,下面将开始采用pytorch的数据集相关API和类。
2. 使用pytorch相关类,API对数据集进行封装
2.1 pytorch中数据集相关的类,接口
pytorch中数据集相关的类位于torch.utils.data package中。
https://pytorch.org/docs/stable/data.html
本次实验,主要使用以下类:
torch.utils.data.Dataset
torch.utils.data.DataLoader
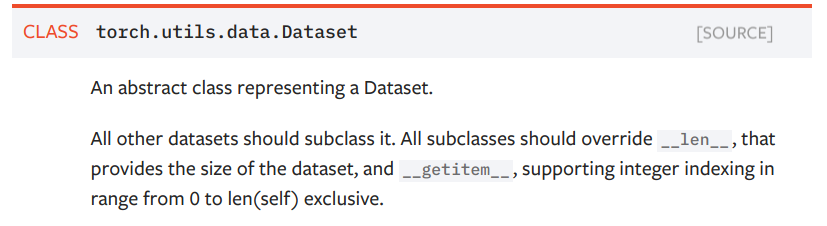
Dataset类的使用: 所有的类都应该是此类的子类(也就是说应该继承该类)。 所有的子类都要重写(override) __len()__, __getitem()__ 这两个方法。
| 方法 | 作用 |
|---|---|
| __len()__ | 此方法应该提供数据集的大小(容量) |
| __getitem()__ | 此方法应该提供支持下标索方式引访问数据集 |
这里和Java抽象类很相似,在抽象类abstract class中,一般会定义一些抽象方法abstract method,抽象方法:只有方法名没有方法的具体实现。如果一个子类继承于该抽象类,要重写(overrode)父类的抽象方法。
DataLoader类的使用:

2.2 实现
使用到的python package
| python package | 目的 |
|---|---|
| numpy | 矩阵操作,对图像进行转置 |
| skimage | 图像处理,图像I/O,图像变换 |
| matplotlib | 图像的显示,可视化 |
| os | 一些文件查找操作 |
| torch | pytorch |
| torvision | pytorch |
源码
导入python包
import numpy as np from skimage import io from skimage import transform import matplotlib.pyplot as plt import os import torch import torchvision from torch.utils.data import Dataset, DataLoader from torchvision.transforms import transforms from torchvision.utils import make_grid
第一步:
定义一个子类,继承Dataset类, 重写 __len()__, __getitem()__ 方法。
细节:
1.数据集中一个一样的表示:采用字典的形式sample = {'image': image, 'label': label}。
2.图像的读取:采用skimage.io进行读取,读取之后的结果为numpy.ndarray形式。
3.图像变换:transform参数
# step1: 定义MyDataset类, 继承Dataset, 重写抽象方法:__len()__, __getitem()__
class MyDataset(Dataset):
def __init__(self, root_dir, names_file, transform=None):
self.root_dir = root_dir
self.names_file = names_file
self.transform = transform
self.size = 0
self.names_list = []
if not os.path.isfile(self.names_file):
print(self.names_file + 'does not exist!')
file = open(self.names_file)
for f in file:
self.names_list.append(f)
self.size += 1
def __len__(self):
return self.size
def __getitem__(self, idx):
image_path = self.root_dir + self.names_list[idx].split(' ')[0]
if not os.path.isfile(image_path):
print(image_path + 'does not exist!')
return None
image = io.imread(image_path) # use skitimage
label = int(self.names_list[idx].split(' ')[1])
sample = {'image': image, 'label': label}
if self.transform:
sample = self.transform(sample)
return sample第二步
实例化一个对象,并读取和显示数据集
train_dataset = MyDataset(root_dir='./data/train',
names_file='./data/train/train.txt',
transform=None)
plt.figure()
for (cnt,i) in enumerate(train_dataset):
image = i['image']
label = i['label']
ax = plt.subplot(4, 4, cnt+1)
ax.axis('off')
ax.imshow(image)
ax.set_title('label {}'.format(label))
plt.pause(0.001)
if cnt == 15:
break只显示了部分数据,前部分全是cat

第三步(可选 optional)
对数据集进行变换:一般收集到的图像大小尺寸,亮度等存在差异,变换的目的就是使得数据归一化。另一方面,可以通过变换进行数据增加data argument
关于pytorch中的变换transforms,请参考该系列之前的文章
由于数据集中样本采用字典dicts形式表示。 因此不能直接调用torchvision.transofrms中的方法。
本实验只进行尺寸归一化Resize, 数据类型变换ToTensor操作。
Resize
# # 变换Resize
class Resize(object):
def __init__(self, output_size: tuple):
self.output_size = output_size
def __call__(self, sample):
# 图像
image = sample['image']
# 使用skitimage.transform对图像进行缩放
image_new = transform.resize(image, self.output_size)
return {'image': image_new, 'label': sample['label']}ToTensor
# # 变换ToTensor
class ToTensor(object):
def __call__(self, sample):
image = sample['image']
image_new = np.transpose(image, (2, 0, 1))
return {'image': torch.from_numpy(image_new),
'label': sample['label']}第四步: 对整个数据集应用变换
细节: transformers.Compose() 将不同的几个组合起来。先进行Resize, 再进行ToTensor
# 对原始的训练数据集进行变换
transformed_trainset = MyDataset(root_dir='./data/train',
names_file='./data/train/train.txt',
transform=transforms.Compose(
[Resize((224,224)),
ToTensor()]
))第五步: 使用DataLoader进行包装
为何要使用DataLoader?
① 深度学习的输入是mini_batch形式
② 样本加载时候可能需要随机打乱顺序,shuffle操作
③ 样本加载需要采用多线程
pytorch提供的DataLoader封装了上述的功能,这样使用起来更方便。
# 使用DataLoader可以利用多线程,batch,shuffle等
trainset_dataloader = DataLoader(dataset=transformed_trainset,
batch_size=4,
shuffle=True,
num_workers=4)可视化:
def show_images_batch(sample_batched):
images_batch, labels_batch = \
sample_batched['image'], sample_batched['label']
grid = make_grid(images_batch)
plt.imshow(grid.numpy().transpose(1, 2, 0))
# sample_batch: Tensor , NxCxHxW
plt.figure()
for i_batch, sample_batch in enumerate(trainset_dataloader):
show_images_batch(sample_batch)
plt.axis('off')
plt.ioff()
plt.show()
plt.show()通过DataLoader包装之后,样本以min_batch形式输出,而且进行了随机打乱顺序。




至此,自定义数据集的完整流程已实现,test, val集只需要改路径即可。
补充
更简单的方法
上述继承Dataset, 重写 __len()__, __getitem() 是通用的方法,过程相对繁琐。对于简单的分类数据集,pytorch中提供了更简便的方式——ImageFolder。
如果每种类别的样本放在各自的文件夹中,则可以直接使用ImageFolder。
仍然以cat, dog 二分类数据集为例:
文件结构:

Code
import torch
from torch.utils.data import DataLoader
from torchvision import transforms, datasets
import matplotlib.pyplot as plt
import numpy as np
# https://pytorch.org/tutorials/beginner/data_loading_tutorial.html
# data_transform = transforms.Compose([
# transforms.RandomResizedCrop(224),
# transforms.RandomHorizontalFlip(),
# transforms.ToTensor(),
# transforms.Normalize(mean=[0.485, 0.456, 0.406],
# std=[0.229, 0.224, 0.225])
# ])
data_transform = transforms.Compose([
transforms.Resize((224,224)),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
])
train_dataset = datasets.ImageFolder(root='./data/train',transform=data_transform)
train_dataloader = DataLoader(dataset=train_dataset,
batch_size=4,
shuffle=True,
num_workers=4)
def show_batch_images(sample_batch):
labels_batch = sample_batch[1]
images_batch = sample_batch[0]
for i in range(4):
label_ = labels_batch[i].item()
image_ = np.transpose(images_batch[i], (1, 2, 0))
ax = plt.subplot(1, 4, i + 1)
ax.imshow(image_)
ax.set_title(str(label_))
ax.axis('off')
plt.pause(0.01)
plt.figure()
for i_batch, sample_batch in enumerate(train_dataloader):
show_batch_images(sample_batch)
plt.show()由于 train 目录下只有2个文件夹,分别为cat, dog, 因此ImageFolder安装顺序对cat使用标签0, dog使用标签1。



看完上述内容,你们对如何利用pytorch自定义一个数据集有进一步的了解吗?如果还想了解更多知识或者相关内容,请关注亿速云行业资讯频道,感谢大家的支持。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





