这篇文章主要讲解了“什么是扩展Spark SQL解析”,文中的讲解内容简单清晰,易于学习与理解,下面请大家跟着小编的思路慢慢深入,一起来研究和学习“什么是扩展Spark SQL解析”吧!

ANTLR
Antlr4是一款开源的语法分析器生成工具,能够根据语法规则文件生成对应的语法分析器。现在很多流行的应用和开源项目里都有使用,比如Hadoop、Hive以及Spark等都在使用ANTLR来做语法分析。
ANTLR 语法识别一般分为二个阶段:
1.词法分析阶段 (lexical analysis)
对应的分析程序叫做 lexer ,负责将符号(token)分组成符号类(token class or token type)
2.解析阶段
根据词法,构建出一棵分析树(parse tree)或叫语法树(syntax tree)
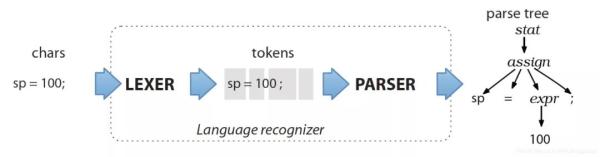
ANTLR的语法文件,非常像电路图,从入口到出口,每个Token就像电阻,连接线就是短路点。
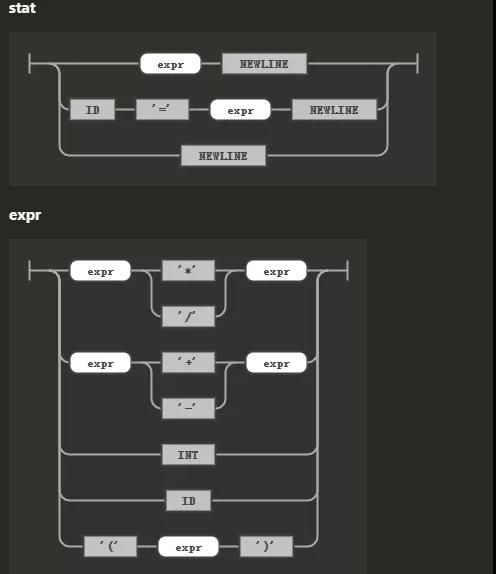
上面截图对应的语法文件片段,定义了两部分语法,一部分是显示表达式和赋值,另外一部分是运算和表达式定义。
stat: expr NEWLINE # printExpr | ID '=' expr NEWLINE # assign | NEWLINE # blank ; expr: expr op=('*'|'/') expr # MulDiv | expr op=('+'|'-') expr # AddSub | INT # int | ID # id | '(' expr ')' # parens ;接下来,加上定义词法部分,就能形成完整的语法文件。
完整语法文件:
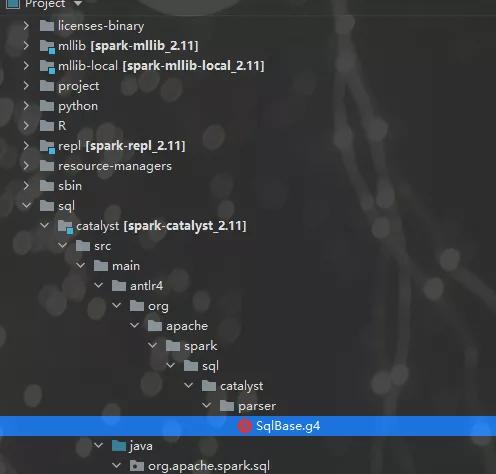
grammar LabeledExpr; // rename to distinguish from Expr.g4 prog: stat+ ; stat: expr NEWLINE # printExpr | ID '=' expr NEWLINE # assign | NEWLINE # blank ; expr: expr op=('*'|'/') expr # MulDiv | expr op=('+'|'-') expr # AddSub | INT # int | ID # id | '(' expr ')' # parens ; MUL : '*' ; // assigns token name to '*' used above in grammar DIV : '/' ; ADD : '+' ; SUB : '-' ; ID : [a-zA-Z]+ ; // match identifiers INT : [0-9]+ ; // match integers NEWLINE:'\r'? '\n' ; // return newlines to parser (is end-statement signal) WS : [ \t]+ -> skip ; // toss out whitespaceSpark的语法文件,在sql下的catalyst模块里,如下图:
一条正常SQL,例如 Select t.id,t.name from t , 现在我们为其添加一个 JACKY表达式,令其出现在 Select 后面 ,形成一条语句
Select t.id,t.name JACKY(2) from t
我们先看一下正常的语法规则:

现在我们添加一个 jackyExpression
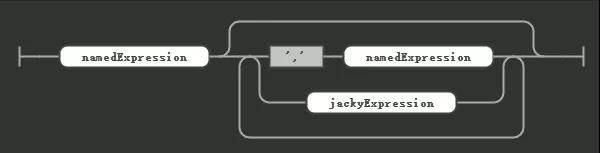
jackExpression 本身的规则就是 JACKY加上括号包裹的一个数字

将 JACKY 添加为token

修改语法文件 如下:
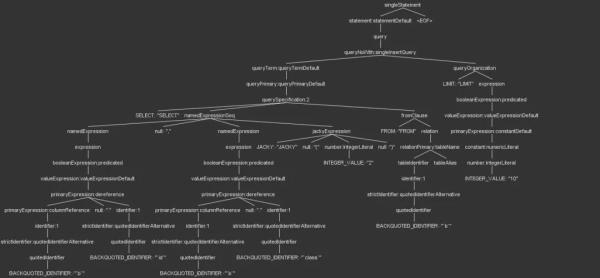
jackyExpression : JACKY'(' number ')' //expression ; namedExpression : expression (AS? (identifier | identifierList))? ; namedExpressionSeq : namedExpression (',' namedExpression | jackyExpression )* ;经过上面的修改,就可以测试语法规则,是不是符合预期了,下面是一颗解析树,我们可以看到jackyExpression已经可以正常解析了。
这里引用一张经典的Spark SQL架构图
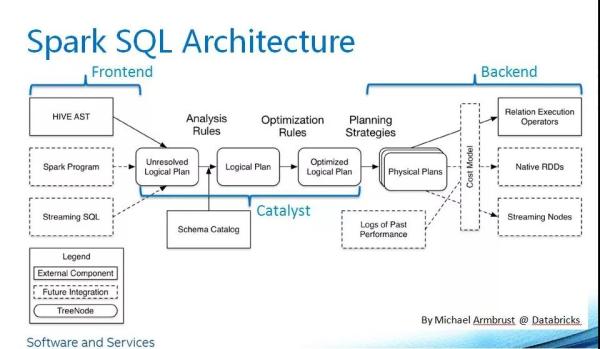
我们输入的 SQL语句 首先被解析成 Unresolved Logical Pan ,对应的是
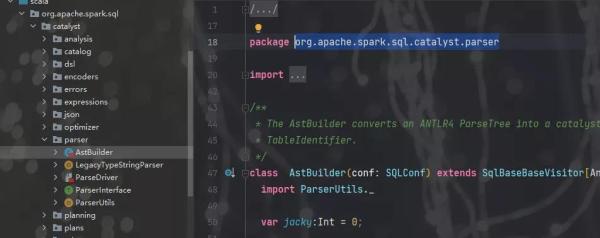
给逻辑计划添加遍历方法:
override def visitJackyExpression(ctx: JackyExpressionContext): String = withOrigin(ctx) { println("this is astbuilder jacky = "+ctx.number().getText) this.jacky = ctx.number().getText.toInt ctx.number().getText }再处理namedExpression的时候,添加jackyExpression处理
// Expressions. val expressions = Option(namedExpressionSeq).toSeq .flatMap(_.namedExpression.asScala) .map(typedVisit[Expression]) //jackyExpression 处理 if(namedExpressionSeq().jackyExpression()!=null && namedExpressionSeq().jackyExpression().size() > 0){ visitJackyExpression(namedExpressionSeq().jackyExpression().get(0)) }好了,到这里从逻辑计划处理就完成了,有了逻辑计划,就可以在后续物理计划中添加相应的处理逻辑就可以了(还没研究明白... Orz)。
测试用例
public class Case4 { public static void main(String[] args) { CharStream ca = CharStreams.fromString("SELECT `b`.`id`,`b`.`class` JACKY(2) FROM `b` LIMIT 10"); SqlBaseLexer lexer = new SqlBaseLexer(ca); SqlBaseParser sqlBaseParser = new SqlBaseParser(new CommonTokenStream(lexer)); ParseTree parseTree = sqlBaseParser.singleStatement(); AstBuilder astBuilder = new AstBuilder(); astBuilder.visit(parseTree); System.out.println(parseTree.toStringTree(sqlBaseParser)); System.out.println(astBuilder.jacky()); } }执行结果

感谢各位的阅读,以上就是“什么是扩展Spark SQL解析”的内容了,经过本文的学习后,相信大家对什么是扩展Spark SQL解析这一问题有了更深刻的体会,具体使用情况还需要大家实践验证。这里是亿速云,小编将为大家推送更多相关知识点的文章,欢迎关注!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





