DataFrameж“ҚдҪңж–№жі•жңүе“Әдәӣ
иҝҷзҜҮж–Үз« дё»иҰҒд»Ӣз»ҚвҖңDataFrameж“ҚдҪңж–№жі•жңүе“ӘдәӣвҖқпјҢеңЁж—Ҙеёёж“ҚдҪңдёӯпјҢзӣёдҝЎеҫҲеӨҡдәәеңЁDataFrameж“ҚдҪңж–№жі•жңүе“Әдәӣй—®йўҳдёҠеӯҳеңЁз–‘жғ‘пјҢе°Ҹзј–жҹҘйҳ…дәҶеҗ„ејҸиө„ж–ҷпјҢж•ҙзҗҶеҮәз®ҖеҚ•еҘҪз”Ёзҡ„ж“ҚдҪңж–№жі•пјҢеёҢжңӣеҜ№еӨ§е®¶и§Јзӯ”вҖқDataFrameж“ҚдҪңж–№жі•жңүе“ӘдәӣвҖқзҡ„з–‘жғ‘жңүжүҖеё®еҠ©пјҒжҺҘдёӢжқҘпјҢиҜ·и·ҹзқҖе°Ҹзј–дёҖиө·жқҘеӯҰд№ еҗ§пјҒ
PandasжҸҗдҫӣдәҶеҗ„з§Қеҗ„ж ·зҡ„DataFrameж“ҚдҪңпјҢдҪҶжҳҜе…¶дёӯи®ёеӨҡж“ҚдҪңеҫҲеӨҚжқӮпјҢиҖҢдё”дјјд№ҺдёҚеӨӘе№іжҳ“иҝ‘дәәгҖӮameж“ҚдҪңж–№жі•пјҢе®ғ们ж¶өзӣ–дәҶж•°жҚ®з§‘еӯҰ家йңҖиҰҒзҹҘйҒ“зҡ„еҮ д№ҺжүҖжңүж“ҚдҪңеҠҹиғҪгҖӮжҜҸз§Қж–№жі•йғҪе°ҶеҢ…жӢ¬иҜҙжҳҺпјҢеҸҜи§ҶеҢ–пјҢд»Јз Ғд»ҘеҸҠи®°дҪҸе®ғзҡ„жҠҖе·§гҖӮ
Pivot
йҖҸи§ҶиЎЁе°ҶеҲӣе»әдёҖдёӘж–°зҡ„вҖңйҖҸи§ҶиЎЁвҖқпјҢиҜҘйҖҸи§ҶиЎЁе°Ҷж•°жҚ®дёӯзҡ„зҺ°жңүеҲ—жҠ•еҪұдёәж–°иЎЁзҡ„е…ғзҙ пјҢеҢ…жӢ¬зҙўеј•пјҢеҲ—е’ҢеҖјгҖӮеҲқе§ӢDataFrameдёӯе°ҶжҲҗдёәзҙўеј•зҡ„еҲ—пјҢ并且иҝҷдәӣеҲ—жҳҫзӨәдёәе”ҜдёҖеҖјпјҢиҖҢиҝҷдёӨеҲ—зҡ„з»„еҗҲе°ҶжҳҫзӨәдёәеҖјгҖӮиҝҷж„Ҹе‘ізқҖPivotж— жі•еӨ„зҗҶйҮҚеӨҚзҡ„еҖјгҖӮ
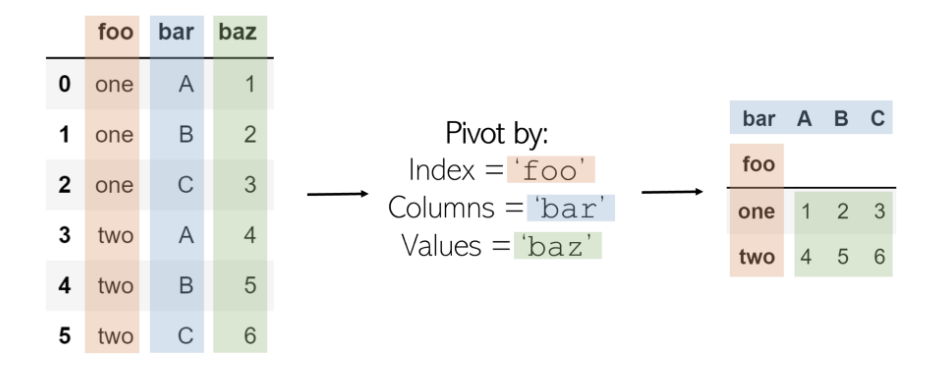
ж—ӢиҪ¬еҗҚдёәdf зҡ„DataFrameзҡ„д»Јз Ғ еҰӮдёӢпјҡ
и®°дҪҸпјҡPivotвҖ”вҖ”жҳҜеңЁж•°жҚ®еӨ„зҗҶйўҶеҹҹд№ӢеӨ–вҖ”вҖ”еӣҙз»•жҹҗз§ҚеҜ№иұЎзҡ„иҪ¬еҗ‘гҖӮеңЁдҪ“иӮІиҝҗеҠЁдёӯпјҢдәә们еҸҜд»Ҙз»•зқҖи„ҡвҖңж—ӢиҪ¬вҖқж—ӢиҪ¬пјҡеӨ§зҶҠзҢ«зҡ„ж—ӢиҪ¬зұ»дјјдәҺгҖӮеҺҹе§ӢDataFrameзҡ„зҠ¶жҖҒеӣҙз»•DataFrameзҡ„дёӯеҝғе…ғзҙ ж—ӢиҪ¬еҲ°дёҖдёӘж–°е…ғзҙ гҖӮжңүдәӣе…ғзҙ е®һйҷ…дёҠжҳҜеңЁж—ӢиҪ¬жҲ–еҸҳжҚўзҡ„пјҲдҫӢеҰӮпјҢеҲ—вҖң bar вҖқпјүпјҢеӣ жӯӨеҫҲйҮҚиҰҒгҖӮ
Melt
MeltеҸҜд»Ҙиў«и®ӨдёәжҳҜвҖңдёҚеҸҜйҖҸи§Ҷзҡ„вҖқпјҢеӣ дёәе®ғе°ҶеҹәдәҺзҹ©йҳөзҡ„ж•°жҚ®пјҲе…·жңүдәҢз»ҙпјүиҪ¬жҚўдёәеҹәдәҺеҲ—иЎЁзҡ„ж•°жҚ®пјҲеҲ—иЎЁзӨәеҖјпјҢиЎҢиЎЁзӨәе”ҜдёҖзҡ„ж•°жҚ®зӮ№пјүпјҢиҖҢжһўиҪҙеҲҷзӣёеҸҚгҖӮиҖғиҷ‘дёҖдёӘдәҢз»ҙзҹ©йҳөпјҢе…¶дёҖз»ҙдёәвҖң B вҖқе’ҢвҖң C вҖқпјҲеҲ—еҗҚпјүпјҢеҸҰдёҖз»ҙдёәвҖң aвҖқпјҢвҖң b вҖқе’ҢвҖң c вҖқпјҲиЎҢзҙўеј•пјүгҖӮ
жҲ‘们йҖүжӢ©дёҖдёӘIDпјҢдёҖдёӘз»ҙеәҰе’ҢдёҖдёӘеҢ…еҗ«еҖјзҡ„еҲ—/еҲ—гҖӮеҢ…еҗ«еҖјзҡ„еҲ—е°ҶиҪ¬жҚўдёәдёӨеҲ—пјҡдёҖеҲ—з”ЁдәҺеҸҳйҮҸпјҲеҖјеҲ—зҡ„еҗҚз§°пјүпјҢеҸҰдёҖеҲ—з”ЁдәҺеҖјпјҲеҸҳйҮҸдёӯеҢ…еҗ«зҡ„ж•°еӯ—пјүгҖӮ
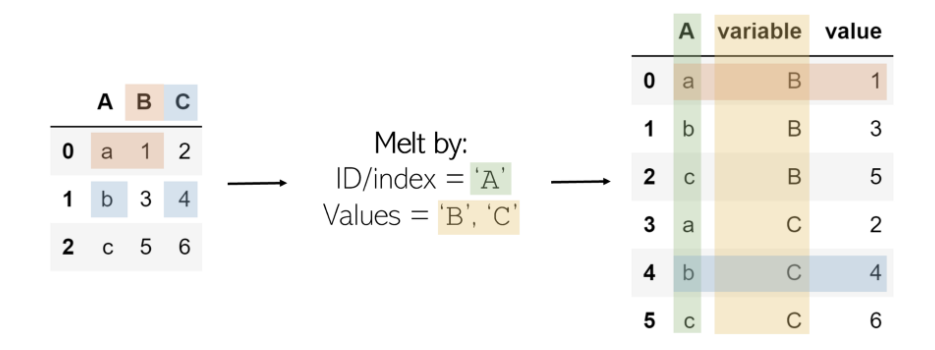
з»“жһңжҳҜIDеҲ—зҡ„еҖјпјҲaпјҢbпјҢcпјүе’ҢеҖјеҲ—пјҲBпјҢCпјүеҸҠе…¶еҜ№еә”еҖјзҡ„жҜҸз§Қз»„еҗҲпјҢд»ҘеҲ—иЎЁж јејҸз»„з»ҮгҖӮ
еҸҜд»ҘеғҸеңЁDataFrame dfдёҠдёҖж ·жү§иЎҢMelsж“ҚдҪң пјҡ
и®°дҪҸпјҡеғҸиңЎзғӣдёҖж ·иһҚеҢ–(Melt)е°ұжҳҜе°ҶеҮқеӣәзҡ„еӨҚеҗҲзү©дҪ“еҸҳжҲҗеҮ дёӘжӣҙе°Ҹзҡ„еҚ•дёӘе…ғзҙ пјҲиңЎж»ҙпјүгҖӮиһҚеҗҲдәҢз»ҙDataFrameеҸҜд»Ҙи§ЈеҺӢзј©е…¶еӣәеҢ–зҡ„з»“жһ„并е°Ҷе…¶зүҮж®өи®°еҪ•дёәеҲ—иЎЁдёӯзҡ„еҗ„дёӘжқЎзӣ®гҖӮ
ExplodeжҳҜдёҖз§Қж‘Ҷи„ұж•°жҚ®еҲ—иЎЁзҡ„жңүз”Ёж–№жі•гҖӮеҪ“дёҖеҲ—зҲҶзӮёж—¶пјҢе…¶дёӯзҡ„жүҖжңүеҲ—иЎЁе°ҶдҪңдёәж–°иЎҢеҲ—еңЁеҗҢдёҖзҙўеј•дёӢпјҲдёәйҳІжӯўеҸ‘з”ҹиҝҷз§Қжғ…еҶөпјҢ жӯӨеҗҺеҸӘйңҖи°ғз”Ё .reset_indexпјҲпјүеҚіеҸҜпјүгҖӮиҜёеҰӮеӯ—з¬ҰдёІжҲ–ж•°еӯ—д№Ӣзұ»зҡ„йқһеҲ—иЎЁйЎ№дёҚеҸ—еҪұе“ҚпјҢз©әеҲ—иЎЁжҳҜNaNеҖјпјҲжӮЁеҸҜд»ҘдҪҝз”Ё.dropnaпјҲпјүжё…йҷӨе®ғ们 пјүгҖӮ
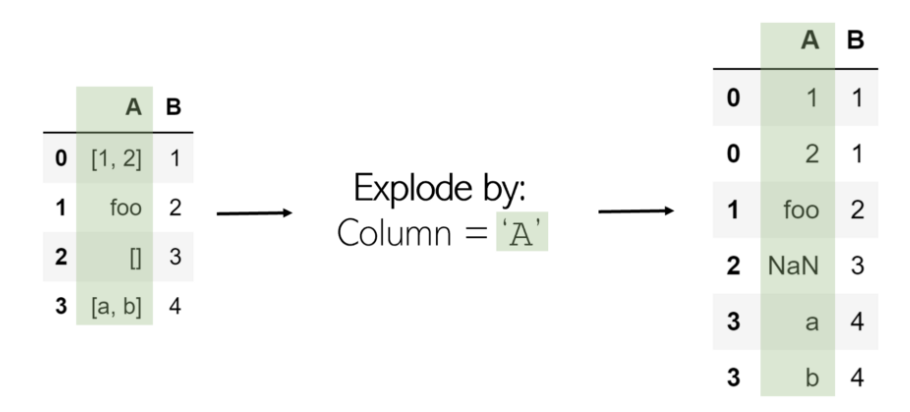
еңЁDataFrame dfдёӯExplodeеҲ—вҖң A вҖқ йқһеёёз®ҖеҚ•пјҡ

иҰҒи®°дҪҸпјҡExplodeжҹҗзү©дјҡйҮҠж”ҫе…¶жүҖжңүеҶ…йғЁеҶ…е®№-ExplodeеҲ—иЎЁдјҡеҲҶйҡ”е…¶е…ғзҙ гҖӮ
Stack
е ҶеҸ йҮҮз”Ёд»»ж„ҸеӨ§е°Ҹзҡ„DataFrameпјҢ并е°ҶеҲ—вҖңе ҶеҸ вҖқдёәзҺ°жңүзҙўеј•зҡ„еӯҗзҙўеј•гҖӮеӣ жӯӨпјҢжүҖеҫ—зҡ„DataFrameд»…е…·жңүдёҖеҲ—е’ҢдёӨзә§зҙўеј•гҖӮ
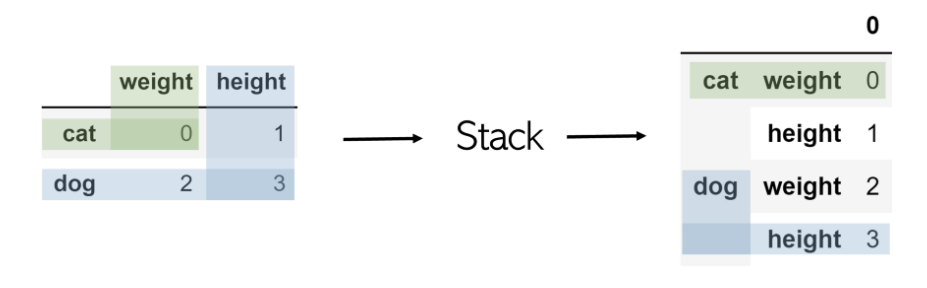
е ҶеҸ еҗҚдёәdfзҡ„иЎЁе°ұеғҸdf.stackпјҲпјүдёҖж ·з®ҖеҚ• гҖӮ
дёәдәҶи®ҝй—®зӢ—зҡ„иә«й«ҳеҖјпјҢеҸӘйңҖдёӨж¬Ўи°ғз”ЁеҹәдәҺзҙўеј•зҡ„жЈҖзҙўпјҢдҫӢеҰӮ df.loc ['dog']гҖӮloc ['height']гҖӮ
иҰҒи®°дҪҸпјҡд»ҺеӨ–и§ӮдёҠзңӢпјҢе Ҷж ҲйҮҮз”ЁиЎЁзҡ„дәҢз»ҙжҖ§е№¶е°ҶеҲ—е Ҷж ҲдёәеӨҡзә§зҙўеј•гҖӮ
Unstack
еҸ–ж¶Ҳе ҶеҸ е°ҶиҺ·еҸ–еӨҡзҙўеј•DataFrame并еҜ№е…¶иҝӣиЎҢе ҶеҸ пјҢе°ҶжҢҮе®ҡзә§еҲ«зҡ„зҙўеј•иҪ¬жҚўдёәе…·жңүзӣёеә”еҖјзҡ„ж–°DataFrameзҡ„еҲ—гҖӮеңЁиЎЁдёҠи°ғз”Ёе Ҷж ҲеҗҺеҶҚи°ғз”Ёе Ҷж ҲдёҚдјҡжӣҙж”№иҜҘе Ҷж ҲпјҲеҺҹеӣ жҳҜеӯҳеңЁвҖң 0 вҖқпјүгҖӮ
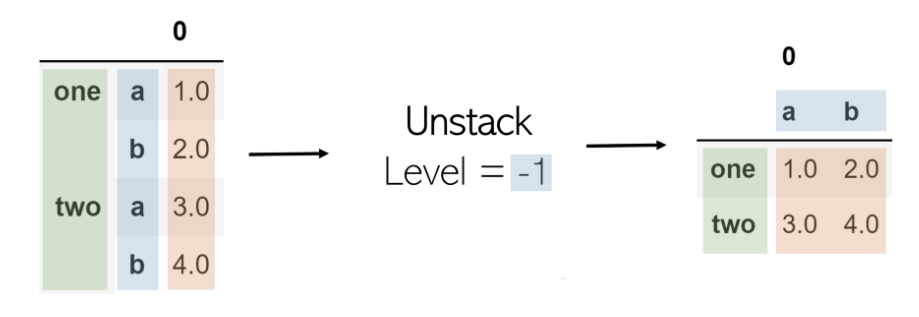
е ҶеҸ дёӯзҡ„еҸӮж•°жҳҜе…¶зә§еҲ«гҖӮеңЁеҲ—иЎЁзҙўеј•дёӯпјҢзҙўеј•дёә-1е°Ҷиҝ”еӣһжңҖеҗҺдёҖдёӘе…ғзҙ гҖӮиҝҷдёҺж°ҙе№ізӣёеҗҢгҖӮзә§еҲ«-1иЎЁзӨәе°ҶеҸ–ж¶Ҳе ҶеҸ жңҖеҗҺдёҖдёӘзҙўеј•зә§еҲ«пјҲжңҖеҸіиҫ№зҡ„дёҖдёӘпјүгҖӮдҪңдёәеҸҰдёҖдёӘзӨәдҫӢпјҢеҪ“зә§еҲ«и®ҫзҪ®дёә0пјҲ第дёҖдёӘзҙўеј•зә§еҲ«пјүж—¶пјҢе…¶дёӯзҡ„еҖје°ҶжҲҗдёәеҲ—пјҢиҖҢйҡҸеҗҺзҡ„зҙўеј•зә§еҲ«пјҲ第дәҢдёӘзҙўеј•зә§еҲ«пјүе°ҶжҲҗдёәиҪ¬жҚўеҗҺзҡ„DataFrameзҡ„зҙўеј•гҖӮ
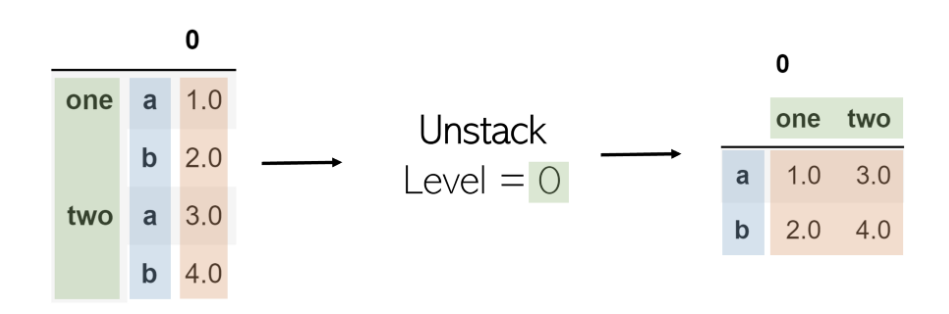
еҸҜд»ҘжҢүз…§дёҺе ҶеҸ зӣёеҗҢзҡ„ж–№ејҸжү§иЎҢе ҶеҸ пјҢдҪҶжҳҜиҰҒдҪҝз”ЁlevelеҸӮж•°пјҡ df.unstackпјҲlevel = -1пјүгҖӮ
Merge
еҗҲ并дёӨдёӘDataFrameжҳҜеңЁе…ұдә«зҡ„вҖңй”®вҖқд№Ӣй—ҙжҢүеҲ—пјҲж°ҙе№іпјүз»„еҗҲе®ғ们гҖӮжӯӨй”®е…Ғи®ёе°ҶиЎЁеҗҲ并пјҢеҚідҪҝе®ғ们зҡ„жҺ’еәҸж–№ејҸдёҚдёҖж ·гҖӮе®ҢжҲҗзҡ„еҗҲ并DataFrame й»ҳи®Өжғ…еҶөдёӢдјҡе°ҶеҗҺзјҖ_x е’Ң _yж·»еҠ еҲ°valueеҲ—гҖӮ
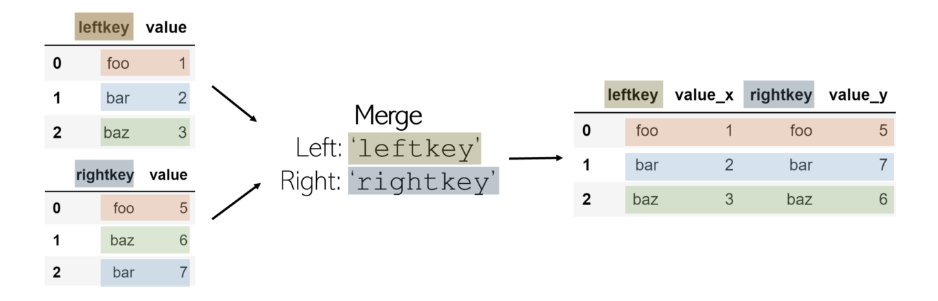
дёәдәҶеҗҲ并дёӨдёӘDataFrame df1 е’Ң df2 пјҲе…¶дёӯ df1 еҢ…еҗ« leftkeyпјҢ иҖҢ df2 еҢ…еҗ« rightkeyпјүпјҢиҜ·и°ғз”Ёпјҡ

еҗҲ并дёҚжҳҜpandasзҡ„еҠҹиғҪпјҢиҖҢжҳҜйҷ„еҠ еҲ°DataFrameгҖӮе§Ӣз»ҲеҒҮе®ҡеҗҲ并жүҖеңЁзҡ„DataFrameжҳҜвҖңе·ҰиЎЁвҖқпјҢеңЁеҮҪж•°дёӯдҪңдёәеҸӮж•°и°ғз”Ёзҡ„DataFrameжҳҜвҖңеҸіиЎЁвҖқпјҢ并еёҰжңүзӣёеә”зҡ„й”®гҖӮ
й»ҳи®Өжғ…еҶөдёӢпјҢеҗҲ并еҠҹиғҪжү§иЎҢеҶ…йғЁиҒ”жҺҘпјҡеҰӮжһңжҜҸдёӘDataFrameзҡ„й”®еҗҚеқҮжңӘеҲ—еңЁеҸҰдёҖдёӘй”®дёӯпјҢеҲҷиҜҘй”®дёҚеҢ…еҗ«еңЁеҗҲ并зҡ„DataFrameдёӯгҖӮеҸҰдёҖж–№йқўпјҢеҰӮжһңдёҖдёӘй”®еңЁеҗҢдёҖDataFrameдёӯеҲ—еҮәдёӨж¬ЎпјҢеҲҷеңЁеҗҲ并表дёӯе°ҶеҲ—еҮәеҗҢдёҖй”®зҡ„жҜҸдёӘеҖјз»„еҗҲгҖӮдҫӢеҰӮпјҢеҰӮжһң df1 е…·жңү3дёӘй”®foo еҖјпјҢ иҖҢ df2 е…·жңү2дёӘзӣёеҗҢй”®зҡ„еҖјпјҢеҲҷ еңЁжңҖз»ҲDataFrameдёӯе°Ҷжңү6дёӘжқЎзӣ®пјҢе…¶дёӯ leftkey = foo е’Ң rightkey = fooгҖӮ
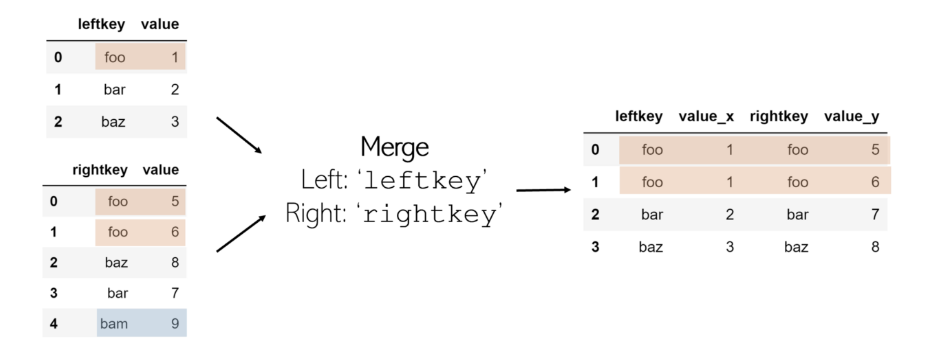
и®°дҪҸпјҡеҗҲ并数жҚ®её§е°ұеғҸеңЁж°ҙе№іиЎҢ驶时еҗҲ并иҪҰйҒ“дёҖж ·гҖӮжғіиұЎдёҖдёӢпјҢжҜҸдёҖеҲ—йғҪжҳҜй«ҳйҖҹе…¬и·ҜдёҠзҡ„дёҖжқЎиҪҰйҒ“гҖӮдёәдәҶеҗҲ并пјҢе®ғ们еҝ…йЎ»ж°ҙе№іеҗҲ并гҖӮ
Join
йҖҡеёёпјҢиҒ”жҺҘжҜ”еҗҲ并жӣҙеҸҜеҸ–пјҢеӣ дёәе®ғе…·жңүжӣҙз®ҖжҙҒзҡ„иҜӯжі•пјҢ并且еңЁж°ҙе№іиҝһжҺҘдёӨдёӘDataFrameж—¶е…·жңүжӣҙеӨ§зҡ„еҸҜиғҪжҖ§гҖӮиҝһжҺҘзҡ„иҜӯжі•еҰӮдёӢпјҡ
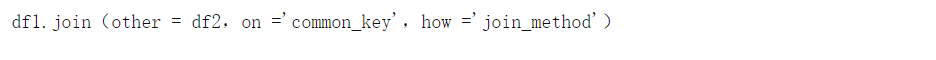
дҪҝз”ЁиҒ”жҺҘж—¶пјҢе…¬е…ұй”®еҲ—пјҲзұ»дјјдәҺ еҗҲ并дёӯзҡ„right_on е’Ң left_onпјүеҝ…йЎ»е‘ҪеҗҚдёәзӣёеҗҢзҡ„еҗҚз§°гҖӮhowеҸӮж•°жҳҜдёҖдёӘеӯ—з¬ҰдёІпјҢе®ғиЎЁзӨәеӣӣз§ҚиҝһжҺҘ ж–№жі•д№ӢдёҖпјҢ еҸҜд»ҘеҗҲ并дёӨдёӘDataFrameпјҡ
' left 'пјҡеҢ…жӢ¬df1зҡ„жүҖжңүе…ғзҙ пјҢ д»…еҪ“е…¶й”®дёәdf1зҡ„й”®ж—¶жүҚ еҢ…еҗ«df2зҡ„е…ғзҙ гҖӮеҗҰеҲҷпјҢdf2зҡ„еҗҲ并DataFrameзҡ„дёўеӨұйғЁеҲҶ е°Ҷиў«ж Үи®°дёәNaNгҖӮ
' right 'пјҡ' left 'пјҢдҪҶеңЁеҸҰдёҖдёӘDataFrameдёҠгҖӮеҢ…жӢ¬df2зҡ„жүҖжңүе…ғзҙ пјҢ д»…еҪ“е…¶й”®жҳҜdf2зҡ„й”®ж—¶жүҚ еҢ…еҗ«df1зҡ„е…ғзҙ гҖӮ
вҖңouterвҖқпјҡеҢ…жӢ¬жқҘиҮӘDataFramesжүҖжңүе…ғзҙ пјҢеҚідҪҝеҜҶй’ҘдёҚеӯҳеңЁдәҺе…¶д»–зҡ„-зјәе°‘зҡ„е…ғзҙ иў«ж Үи®°дёәNaNзҡ„гҖӮ
вҖңinnerвҖқпјҡд»…еҢ…еҗ«е…ғ件зҡ„й”®жҳҜеӯҳеңЁдәҺдёӨдёӘж•°жҚ®её§й”®пјҲдәӨйӣҶпјүгҖӮй»ҳи®ӨеҗҲ并гҖӮ
и®°дҪҸпјҡеҰӮжһңжӮЁдҪҝз”ЁиҝҮSQLпјҢеҲҷеҚ•иҜҚвҖң joinвҖқеә”з«ӢеҚідёҺжҢүеҲ—ж·»еҠ зӣёиҒ”зі»гҖӮеҰӮжһңдёҚжҳҜпјҢеҲҷвҖң joinвҖқе’ҢвҖң mergeвҖқеңЁе®ҡд№үж–№йқўе…·жңүйқһеёёзӣёдјјзҡ„еҗ«д№үгҖӮ
Concat
еҗҲ并е’ҢиҝһжҺҘжҳҜж°ҙе№іе·ҘдҪңпјҢдёІиҒ”жҲ–з®Җз§°дёәconcatпјҢиҖҢDataFrameжҳҜжҢүиЎҢпјҲеһӮзӣҙпјүиҝһжҺҘзҡ„гҖӮдҫӢеҰӮпјҢиҖғиҷ‘дҪҝз”Ёpandas.concatпјҲ[df1пјҢdf2]пјүдёІиҒ”зҡ„е…·жңүзӣёеҗҢеҲ—еҗҚзҡ„ дёӨдёӘDataFrame df1 е’Ң df2 пјҡ
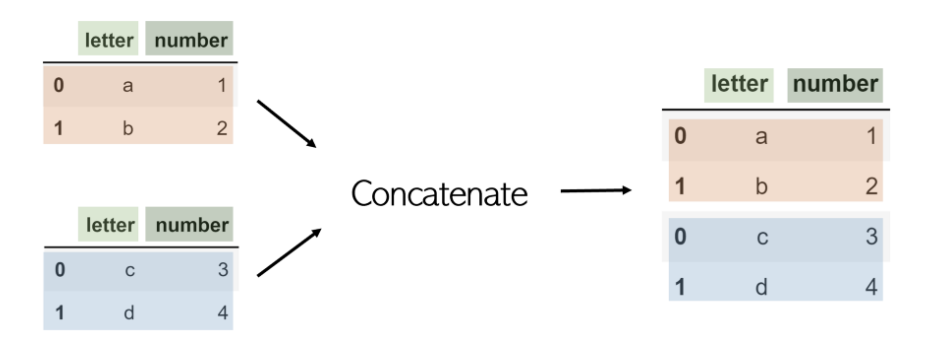
е°Ҫз®ЎеҸҜд»ҘйҖҡиҝҮе°ҶaxisеҸӮж•°и®ҫзҪ®дёә1жқҘдҪҝз”ЁconcatиҝӣиЎҢеҲ—ејҸиҒ”жҺҘпјҢдҪҶжҳҜдҪҝз”ЁиҒ”жҺҘ дјҡжӣҙе®№жҳ“гҖӮ
иҜ·жіЁж„ҸпјҢconcatжҳҜpandasеҮҪж•°пјҢиҖҢдёҚжҳҜDataFrameд№ӢдёҖгҖӮеӣ жӯӨпјҢе®ғжҺҘеҸ—иҰҒиҝһжҺҘзҡ„DataFrameеҲ—иЎЁгҖӮ
еҰӮжһңдёҖдёӘDataFrameзҡ„еҸҰдёҖеҲ—жңӘеҢ…еҗ«пјҢй»ҳи®Өжғ…еҶөдёӢе°ҶеҢ…еҗ«иҜҘеҲ—пјҢзјәеӨұеҖјеҲ—дёәNaNгҖӮдёәдәҶйҳІжӯўиҝҷз§Қжғ…еҶөпјҢиҜ·ж·»еҠ дёҖдёӘйҷ„еҠ еҸӮж•°join ='inner'пјҢиҜҘеҸӮж•° еҸӘдјҡдёІиҒ”дёӨдёӘDataFrameе…ұжңүзҡ„еҲ—гҖӮ

еҲҮи®°пјҡеңЁеҲ—иЎЁе’Ңеӯ—з¬ҰдёІдёӯпјҢеҸҜд»ҘдёІиҒ”е…¶д»–йЎ№гҖӮдёІиҒ”жҳҜе°Ҷйҷ„еҠ е…ғзҙ йҷ„еҠ еҲ°зҺ°жңүдё»дҪ“дёҠпјҢиҖҢдёҚжҳҜж·»еҠ ж–°дҝЎжҒҜпјҲе°ұеғҸйҖҗеҲ—иҒ”жҺҘдёҖж ·пјүгҖӮз”ұдәҺжҜҸдёӘзҙўеј•/иЎҢйғҪжҳҜдёҖдёӘеҚ•зӢ¬зҡ„йЎ№зӣ®пјҢеӣ жӯӨдёІиҒ”е°Ҷе…¶д»–йЎ№зӣ®ж·»еҠ еҲ°DataFrameдёӯпјҢиҝҷеҸҜд»ҘзңӢдҪңжҳҜиЎҢзҡ„еҲ—иЎЁгҖӮ
AppendжҳҜз»„еҗҲдёӨдёӘDataFrameзҡ„еҸҰдёҖз§Қж–№жі•пјҢдҪҶе®ғжү§иЎҢзҡ„еҠҹиғҪдёҺconcatзӣёеҗҢпјҢж•ҲзҺҮиҫғдҪҺдё”з”ЁйҖ”е№ҝжіӣгҖӮ
еҲ°жӯӨпјҢе…ідәҺвҖңDataFrameж“ҚдҪңж–№жі•жңүе“ӘдәӣвҖқзҡ„еӯҰд№ е°ұз»“жқҹдәҶпјҢеёҢжңӣиғҪеӨҹи§ЈеҶіеӨ§е®¶зҡ„з–‘жғ‘гҖӮзҗҶи®әдёҺе®һи·өзҡ„жҗӯй…ҚиғҪжӣҙеҘҪзҡ„её®еҠ©еӨ§е®¶еӯҰд№ пјҢеҝ«еҺ»иҜ•иҜ•еҗ§пјҒиӢҘжғіз»§з»ӯеӯҰд№ жӣҙеӨҡзӣёе…ізҹҘиҜҶпјҢиҜ·з»§з»ӯе…іжіЁдәҝйҖҹдә‘зҪ‘з«ҷпјҢе°Ҹзј–дјҡ继з»ӯеҠӘеҠӣдёәеӨ§е®¶еёҰжқҘжӣҙеӨҡе®һз”Ёзҡ„ж–Үз« пјҒ





