еҰӮдҪ•иҝӣиЎҢkafka connector зӣ‘еҗ¬sqlserverзҡ„е°қиҜ•
еҰӮдҪ•иҝӣиЎҢkafka connector зӣ‘еҗ¬sqlserverзҡ„е°қиҜ•пјҢй’ҲеҜ№иҝҷдёӘй—®йўҳпјҢиҝҷзҜҮж–Үз« иҜҰз»Ҷд»Ӣз»ҚдәҶзӣёеҜ№еә”зҡ„еҲҶжһҗе’Ңи§Јзӯ”пјҢеёҢжңӣеҸҜд»Ҙеё®еҠ©жӣҙеӨҡжғіи§ЈеҶіиҝҷдёӘй—®йўҳзҡ„е°ҸдјҷдјҙжүҫеҲ°жӣҙз®ҖеҚ•жҳ“иЎҢзҡ„ж–№жі•гҖӮ
д№ӢеүҚжӢҝcanalзӣ‘еҗ¬mysqlзҡ„binlog并е°Ҷж¶ҲжҒҜйҖ’з»ҷkafka topic,дҪҶжҳҜcanalеҸӘиғҪзӣ‘еҗ¬mysql,еҒҮеҰӮж•°жҚ®еә“жҳҜsqlserver\orcale\mongodbйӮЈд№Ҳе®Ңе…Ёж— иғҪдёәеҠӣ.зңӢдәҶдёҖдёӢзҪ‘дёҠзҡ„иө„ж–ҷ,дё»жөҒжҳҜз”Ёkafka connectжқҘзӣ‘еҗ¬sqlserver,дёӢйқўеҲҶдә«дёҖдёӢжҲ‘е°қиҜ•зҡ„иҝҮзЁӢ.
зҺ°еңЁз®ҖеҚ•иҜҙиҜҙ,й…ҚзҪ®иҝҮзЁӢдёӯж¶үеҸҠеҲ°kafka connector,confluent,kafka. kafka connectorжҳҜkafkaиҮӘеёҰзү№жҖ§,з”ЁжқҘеҲӣе»әе’Ңз®ЎзҗҶж•°жҚ®жөҒз®ЎйҒ“,жҳҜдёӘе’Ңе…¶е®ғзі»з»ҹдәӨжҚўж•°жҚ®зҡ„з®ҖеҚ•жЁЎеһӢ;
confluentжҳҜдёҖ家еӣҙз»•kafkaеҒҡдә§е“Ғзҡ„е…¬еҸё,дёҚдҪҶжҸҗдҫӣж•°жҚ®дј иҫ“зҡ„зі»з»ҹ,д№ҹжҸҗдҫӣж•°жҚ®дј иҫ“зҡ„е·Ҙе…·,еҶ…йғЁе°ҒиЈ…дәҶkafka.еңЁиҝҷйҮҢжҲ‘们еҸӘз”Ёе®ғдёӢиҪҪkafkaй“ҫжҺҘsqlserverзҡ„connector组件.
жҲ‘дҪҝз”Ёзҡ„kafkaжҳҜз”ЁCDH cloudera managerе®үиЈ…зҡ„,еӣ жӯӨkafkaзҡ„binзӣ®еҪ•\й…ҚзҪ®зӣ®еҪ•\ж—Ҙеҝ—д»Җд№Ҳзҡ„йғҪдёҚеңЁдёҖиө·,д№ҹжІЎжңү$KAFKA_HOME.иҷҪ然иҝҷж¬ЎжҳҜжөӢиҜ•еҠҹиғҪ,дҪҶжҳҜдёәдәҶд»ҘеҗҺдёӢиҪҪжӣҙеӨҡconnector组件иҖғиҷ‘,жҲ‘иҝҳжҳҜдёӢиҪҪдәҶconfluent.е»әи®®еңЁе®ҳзҪ‘дёӢиҪҪ,жІЎзҝ»&еўҷ,зҪ‘йҖҹиҝҳеҸҜд»Ҙ.
confluentдёӢиҪҪең°еқҖ https://www.confluent.io/download/ йҖүжӢ©дёӢйқўзҡ„Download Confluent Platform,еЎ«еҶҷйӮ®д»¶ең°еқҖе’Ңз”ЁйҖ”дёӢиҪҪ.
5.2зүҲжң¬дёӢиҪҪең°еқҖ: http://packages.confluent.io/archive/5.2/
еңЁеҮҶеӨҮдёӢиҪҪе’Ңи§ЈеҺӢзҡ„дҪҚзҪ®,ејҖе§ӢдёӢиҪҪе’Ңи§ЈеҺӢ:
wget http://packages.confluent.io/archive/5.2/confluent-5.2.3-2.11.zip
tar -zxvf confluent-5.2.3-2.11.zip confluent-5.2.3-2.11
и§ЈеҺӢеҮәжқҘеә”иҜҘжҳҜжңүдёҖдёӢеҮ дёӘж–Ү件еӨ№(usrжҳҜжҲ‘иҮӘе·ұеҲӣе»әзҡ„,з”ЁжқҘеӯҳеӮЁз”ЁжҲ·зҡ„й…ҚзҪ®ж–Ү件е’ҢиҜӯеҸҘ):

е°ҶCONFLUENT_HOMEй…ҚзҪ®иҝӣзҺҜеўғеҸҳйҮҸйҮҢ:
vi /etc/profile
export CONFLUENT_HOME=/usr/software/confluent-5.2.3
export PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME:$CONFLUENT_HOME/bin
и·Ҝеҫ„жҳҜжҲ‘иҮӘе·ұзҡ„,еӨ§е®¶ж”№жҲҗиҮӘе·ұзҡ„ж–Ү件и·Ҝеҫ„.
дёӢиҪҪconnectorиҝһжҺҘеҷЁз»„件,жҜҸдёӘ组件иҝһжҺҘjdbcзҡ„й…ҚзҪ®ж–Ү件йғҪеҸҜиғҪдёҚдёҖж ·,жіЁж„ҸзңӢе®ҳж–№ж–ҮжЎЈ.жҲ‘йҖүжӢ©зҡ„жҳҜ debezium-connector-sqlserver .е…Ҳиҝӣе…Ҙbinзӣ®еҪ•,иғҪеӨҹзңӢеҲ°жңүconfluent-hub жҢҮд»Ө,жҲ‘们йқ е®ғжқҘдёӢиҪҪ组件.
[root@centos04 bin]# confluent-hub install debezium/debezium-connector-sqlserver:latest
The component can be installed in any of the following Confluent Platform installations:
1. /usr/software/confluent-5.2.3 (based on $CONFLUENT_HOME)
2. /usr/software/confluent-5.2.3 (where this tool is installed)
Choose one of these to continue the installation (1-2): 2
Do you want to install this into /usr/software/confluent-5.2.3/share/confluent-hub-components? (yN) y^H
Do you want to install this into /usr/software/confluent-5.2.3/share/confluent-hub-components? (yN) y
Component's license:
Apache 2.0
https://github.com/debezium/debezium/blob/master/LICENSE.txt
I agree to the software license agreement (yN) y
иҫ“е…ҘжҢҮд»ӨеҗҺе…Ҳй—®дҪ е®ү装组件дҪҚзҪ®,жҳҜ$CONFLUENT_HOMEзӣ®еҪ•дёӢиҝҳжҳҜconfluentзӣ®еҪ•дёӢ,еҶҚй—®дҪ 组件жҳҜеҗҰе®үиЈ…еңЁ{$confluent}/share/confluent-hub-componentsиҝҷдёӘй»ҳи®ӨдҪҚзҪ®,йҖүжӢ©nзҡ„иҜқеҸҜд»ҘиҮӘе·ұиҫ“е…Ҙж–Ү件дҪҚзҪ®,еҶҚй—®жҳҜеҗҰеҗҢж„Ҹи®ёеҸҜ,д»ҘеҸҠжҳҜеҗҰжӣҙ新组件.еҒҮеҰӮжІЎжңүзү№еҲ«йңҖжұӮзҡ„иҜқ,зӣҙжҺҘйҖүжӢ©yе°ұеҸҜд»ҘдәҶ.
е…¶е®ғ组件еҸҜд»ҘеңЁhttps://www.confluent.io/hub/йҮҢйқўжҢ‘йҖү,иҝҳжңүе®ҳж–№ж–ҮжЎЈж•ҷдҪ еҰӮдҪ•й…ҚзҪ®,еҫҲйҮҚиҰҒ.е…үзңӢзҪ‘дёҠж•ҷзЁӢжҖҺд№ҲеҒҡжІЎжңүзҗҶи§Јдёәд»Җд№Ҳиҝҷд№ҲеҒҡеҫҲе®№жҳ“иө°ејҜи·Ҝ,ж №жң¬дёҚзҹҘйҒ“е“ӘйҮҢеҒҡй”ҷдәҶ.жҲ‘зңӢдәҶеҫҲеӨҡзҜҮйғҪжҳҜдёҖжЁЎдёҖж ·,з”Ёзҡ„组件жҳҜ Confluent MSSQL Connector .дҪҶжҳҜиҝҷдёӘ组件已з»ҸжІЎжңүдәҶ,жҚўе…¶е®ғ组件зҡ„иҜқй…ҚзҪ®йңҖиҰҒжӣҙж”№.жҲ‘е°ұеңЁиҝҷйҮҢиҠұиҙ№дәҶеҫҲй•ҝж—¶й—ҙ.жіЁж„ҸзңӢе®ҳж–№ж–ҮжЎЈ.
Debezium SQL Serverзҡ„иҜҙжҳҺж–ҮжЎЈең°еқҖ:https://docs.confluent.io/current/connect/debezium-connect-sqlserver/index.html#sqlserver-source-connector
дёӢиҪҪе®ҢжҲҗеҗҺе°ұеҸҜд»ҘеңЁ{$confluent}/share/confluent-hub-componentsзӣ®еҪ•дёӢйқўзңӢи§ҒдёӢиҪҪеҘҪзҡ„组件дәҶ.жҺҘдёӢжқҘй…ҚзҪ®kafka.
иҝӣе…Ҙkafkaзҡ„й…ҚзҪ®зӣ®еҪ•,kafkaеҚ•зӢ¬е®үиЈ…зҡ„иҜқдҪҚзҪ®жҳҜ$KAFKA_HOME/config,CDHзүҲжң¬зҡ„й…ҚзҪ®ж–Ү件еңЁ/opt/cloudera/parcels/CDH-6.3.0-1.cdh7.3.0.p0.1279813/etc/kafka/conf.distдёӢйқў.дёҚзҹҘйҒ“е®үиЈ…дҪҚзҪ®зҡ„иҜқзӣҙжҺҘжҗңж–Ү件еҗҚconnect-distributed.properties.еҒҮеҰӮиҝҷйғҪжІЎжңүйӮЈиҜҙжҳҺдҪ зҡ„kafkaеҸҜиғҪзүҲжң¬еӨӘдҪҺ,жІЎжңүиҝҷдёӘзү№жҖ§.
дҝ®ж”№е…¶дёӯзҡ„connect-distributed.propertiesж–Ү件.
##
# Licensed to the Apache Software Foundation (ASF) under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License, Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
##
# This file contains some of the configurations for the Kafka Connect distributed worker. This file is intended
# to be used with the examples, and some settings may differ from those used in a production system, especially
# the `bootstrap.servers` and those specifying replication factors.
# A list of host/port pairs to use for establishing the initial connection to the Kafka cluster.
#kafkaйӣҶзҫӨдҪҚзҪ®,йңҖиҰҒй…ҚзҪ®
bootstrap.servers=centos04:9092,centos05:9092,centos06:9092
# unique name for the cluster, used in forming the Connect cluster group. Note that this must not conflict with consumer group IDs
#group.id,й»ҳи®ӨйғҪжҳҜconnect-cluster,дҝқжҢҒдёҖиҮҙе°ұиЎҢ
group.id=connect-cluster
# The converters specify the format of data in Kafka and how to translate it into Connect data. Every Connect user will
# need to configure these based on the format they want their data in when loaded from or stored into Kafka
key.converter=org.apache.kafka.connect.json.JsonConverter
value.converter=org.apache.kafka.connect.json.JsonConverter
# Converter-specific settings can be passed in by prefixing the Converter's setting with the converter we want to apply
# it to
key.converter.schemas.enable=true
value.converter.schemas.enable=true
# Topic to use for storing offsets. This topic should have many partitions and be replicated and compacted.
# Kafka Connect will attempt to create the topic automatically when needed, but you can always manually create
# the topic before starting Kafka Connect if a specific topic configuration is needed.
# Most users will want to use the built-in default replication factor of 3 or in some cases even specify a larger value.
# Since this means there must be at least as many brokers as the maximum replication factor used, we'd like to be able
# to run this example on a single-broker cluster and so here we instead set the replication factor to 1.
offset.storage.topic=connect-offsets
offset.storage.replication.factor=3
offset.storage.partitions=1
# Topic to use for storing connector and task configurations; note that this should be a single partition, highly replicated,
# and compacted topic. Kafka Connect will attempt to create the topic automatically when needed, but you can always manually create
# the topic before starting Kafka Connect if a specific topic configuration is needed.
# Most users will want to use the built-in default replication factor of 3 or in some cases even specify a larger value.
# Since this means there must be at least as many brokers as the maximum replication factor used, we'd like to be able
# to run this example on a single-broker cluster and so here we instead set the replication factor to 1.
config.storage.topic=connect-configs
config.storage.replication.factor=3
# Topic to use for storing statuses. This topic can have multiple partitions and should be replicated and compacted.
# Kafka Connect will attempt to create the topic automatically when needed, but you can always manually create
# the topic before starting Kafka Connect if a specific topic configuration is needed.
# Most users will want to use the built-in default replication factor of 3 or in some cases even specify a larger value.
# Since this means there must be at least as many brokers as the maximum replication factor used, we'd like to be able
# to run this example on a single-broker cluster and so here we instead set the replication factor to 1.
status.storage.topic=connect-status
status.storage.replication.factor=3
#status.storage.partitions=1
offset.storage.file.filename=/var/log/confluent/offset-storage-file
# Flush much faster than normal, which is useful for testing/debugging
offset.flush.interval.ms=10000
# These are provided to inform the user about the presence of the REST host and port configs
# Hostname & Port for the REST API to listen on. If this is set, it will bind to the interface used to listen to requests.
#rest.host.name=
#kafka connectorз«ҜеҸЈеҸ·,еҸҜд»Ҙдҝ®ж”№
rest.port=8083
# The Hostname & Port that will be given out to other workers to connect to i.e. URLs that are routable from other servers.
#rest.advertised.host.name=
#rest.advertised.port=
# Set to a list of filesystem paths separated by commas (,) to enable class loading isolation for plugins
# (connectors, converters, transformations). The list should consist of top level directories that include
# any combination of:
# a) directories immediately containing jars with plugins and their dependencies
# b) uber-jars with plugins and their dependencies
# c) directories immediately containing the package directory structure of classes of plugins and their dependencies
# Examples:
# plugin.path=/usr/local/share/java,/usr/local/share/kafka/plugins,/opt/connectors,
# Replace the relative path below with an absolute path if you are planning to start Kafka Connect from within a
# directory other than the home directory of Confluent Platform.
#组件дҪҚзҪ®,жҠҠconfluent组件дёӢиҪҪдҪҚзҪ®еҠ дёҠеҺ»
plugin.path=/usr/software/confluent-5.2.3/share/java/confluent-hub-client,,/usr/software/confluent-5.2.3/share/confluent-hub-client,/usr/software/confluent-5.2.3/share/confluent-hub-components
е…ҲеҲӣе»әдҪҝз”ЁconnectorиҰҒз”ЁеҲ°зҡ„зү№ж®Ҡtopic,йҒҝе…ҚеңЁеҗҜеҠЁkafka connectorзҡ„ж—¶еҖҷеҲӣе»әеӨұиҙҘеҜјиҮҙkafka connectorеҗҜеҠЁеӨұиҙҘ.зү№ж®ҠtopicжңүдёүдёӘ:
kafka-topics --create --zookeeper 192.168.49.104:2181 --topic connect-offsets --replication-factor 3 --partitions 1
kafka-topics --create --zookeeper 192.168.49.104:2181 --topic connect-configs --replication-factor 3 --partitions 1
kafka-topics --create --zookeeper 192.168.49.104:2181 --topic connect-status --replication-factor 3 --partitions 1
еҶҚиҝӣе…Ҙkafkaзҡ„binзӣ®еҪ•,CDHзүҲжң¬зҡ„жҳҜ/opt/cloudera/parcels/CDH-6.3.0-1.cdh7.3.0.p0.1279813/lib/kafka/bin.
жү§иЎҢconnect-distributed.shжҢҮд»Ө:
sh connect-distributed.sh /opt/cloudera/parcels/CDH-6.3.0-1.cdh7.3.0.p0.1279813/etc/kafka/conf.dist/connect-distributed.properties
иҜҙдёҖзӮ№,CDHе®үиЈ…зҡ„kafkaеңЁжү§иЎҢжҢҮд»Өзҡ„ж—¶еҖҷдјҡжҠҘй”ҷжүҫдёҚеҲ°ж—Ҙеҝ—ж–Ү件,еҺҹеӣ жҳҜCDHе®үиЈ…зҡ„kafkaеҗ„дёӘйғЁеҲҶйғҪдёҚеңЁдёҖиө·.зӣҙжҺҘдҝ®ж”№connect-distributed.sh ,жҠҠйҮҢйқўзҡ„ең°еқҖеҶҷжӯ»е°ұеҘҪдәҶ.
vi connect-distributed.sh
#дҝ®ж”№зҡ„ең°ж–№
base_dir=$(dirname $0)
if [ "x$KAFKA_LOG4J_OPTS" = "x" ]; then
export KAFKA_LOG4J_OPTS="-Dlog4j.configuration=file:/opt/cloudera/parcels/CDH-6.3.0-1.cdh7.3.0.p0.1279813/etc/kafka/conf.dist/connect-log4j.properties"
fi
иҝҷж ·жү§иЎҢиө·жқҘе°ұжІЎжңүй—®йўҳдәҶ.
д»ҘдёҠжү§иЎҢзҡ„ж—¶еҖҷжҳҜеңЁеүҚеҸ°жү§иЎҢ,еүҚеҸ°еҒңжӯўйҖҖеҮәзҡ„иҜқkafka connectorд№ҹе°ұеҒңжӯўдәҶ,иҝҷз§Қжғ…еҶөйҖӮеҗҲи°ғиҜ•.еңЁеҗҺеҸ°иҝҗиЎҢйңҖиҰҒеҠ дёҠ -daemon еҸӮж•°.
sh connect-distributed.sh -daemon /opt/cloudera/parcels/CDH-6.3.0-1.cdh7.3.0.p0.1279813/etc/kafka/conf.dist/connect-distributed.properties
дҪҝз”ЁDebezium SQL ServerжқҘзӣ‘еҗ¬зҡ„иҜқйңҖиҰҒејҖеҗҜsqlserverзҡ„CDCеҠҹиғҪ.CDCеҠҹиғҪиҰҒе…ҲејҖеҗҜеә“зҡ„жҚ•иҺ·,еҶҚејҖеҗҜиЎЁзҡ„жҚ•иҺ·,жүҚиғҪзӣ‘еҗ¬еҲ°иЎЁзҡ„еҸҳеҢ–.
жҲ‘дҪҝз”Ёзҡ„жҳҜnavicatжқҘиҝһжҺҘж•°жҚ®еә“,еӨ§е®¶з”ЁиҮӘе·ұеҗҲйҖӮзҡ„е·Ҙе…·жқҘе°ұеҸҜд»ҘдәҶ.
ејҖеҗҜеә“зҡ„жҚ•иҺ·:
use database;
EXEC sys.sp_cdc_enable_db
иҝҷдёҖжӯҘеҗҺж•°жҚ®еә“дјҡеӨҡеҮәдёҖдёӘеҸ«cdcзҡ„жЁЎејҸ,дёӢйқўжңү5еј иЎЁ.
жҹҘиҜўе“Әдәӣж•°жҚ®еә“ејҖеҗҜдәҶCDCеҠҹиғҪ:
select * from sys.databases where is_cdc_enabled = 1
еҗҜз”ЁиЎЁзҡ„CDCеҠҹиғҪ:
use database;
EXEC sys.sp_cdc_enable_table
@source_schema = 'dbo',
@source_name = 'table_name',
@role_name = null;
жҹҘзңӢе“ӘдәӣиЎЁеҗҜз”ЁдәҶCDCеҠҹиғҪ:
use database;
select name, is_tracked_by_cdc from sys.tables where is_tracked_by_cdc = 1
д»ҘдёҠе°ұејҖеҗҜдәҶеҜ№иЎЁзӣ‘еҗ¬зҡ„CDCеҠҹиғҪ.
еҪ“жҲ‘们еҗҜеҠЁKafkaConnectorеҗҺ,е°ұиғҪеӨҹйҖҡиҝҮжҺҘеҸЈзҡ„еҪўејҸжқҘи®ҝй—®е’ҢжҸҗдәӨдҝЎжҒҜ.
жҹҘзңӢkafka connectorдҝЎжҒҜ:
[root@centos04 huishui]# curl -s centos04:8083 | jq
{
"version": "2.2.1-cdh7.3.0",
"commit": "unknown",
"kafka_cluster_id": "GwdoyDpbT5uP4k2CN6zbrw"
}8083жҳҜдёҠйқўй…ҚзҪ®зҡ„з«ҜеҸЈеҸ·,еҗҢж ·д№ҹеҸҜд»ҘйҖҡиҝҮwebйЎөйқўжқҘи®ҝй—®.

жҹҘзңӢе®үиЈ…дәҶе“ӘдәӣconnectorиҝһжҺҘеҷЁ:
[root@centos04 huishui]# curl -s centos04:8083 | jq
{
"version": "2.2.1-cdh7.3.0",
"commit": "unknown",
"kafka_cluster_id": "GwdoyDpbT5uP4k2CN6zbrw"
}
[root@centos04 huishui]# curl -s centos04:8083/connector-plugins | jq
[
{
"class": "io.confluent.connect.elasticsearch.ElasticsearchSinkConnector",
"type": "sink",
"version": "10.0.2"
},
{
"class": "io.confluent.connect.jdbc.JdbcSinkConnector",
"type": "sink",
"version": "5.5.1"
},
{
"class": "io.confluent.connect.jdbc.JdbcSourceConnector",
"type": "source",
"version": "5.5.1"
},
{
"class": "io.debezium.connector.sqlserver.SqlServerConnector",
"type": "source",
"version": "1.2.2.Final"
},
{
"class": "org.apache.kafka.connect.file.FileStreamSinkConnector",
"type": "sink",
"version": "2.2.1-cdh7.3.0"
},
{
"class": "org.apache.kafka.connect.file.FileStreamSourceConnector",
"type": "source",
"version": "2.2.1-cdh7.3.0"
}
]жҲ‘е®үиЈ…дәҶеҫҲеӨҡ,жңүio.debezium.connector.sqlserver.SqlServerConnectorе°ұиҜҙжҳҺжІЎй—®йўҳ.
жҹҘзңӢеҪ“еүҚиҝҗиЎҢзҡ„д»»еҠЎ/Task:
[root@centos04 huishui]# curl -s centos04:8083/connectors | jq
[]
з”ұдәҺжҲ‘们иҝҳжІЎжңүжҸҗдәӨд»»дҪ•з”ЁжҲ·й…ҚзҪ®,жүҖд»Ҙд№ҹе°ұжІЎжңүд»»еҠЎ,иҝ”еӣһе°ұжҳҜдёҖдёӘз©әзҡ„json.еҲ°иҝҷйҮҢиҜҙжҳҺkafka connectorеҗҜеҠЁжҲҗеҠҹ,иғҪеӨҹжӯЈеёёиҝӣиЎҢз”ЁжҲ·й…ҚзҪ®.жҺҘдёӢжқҘжүҚжҳҜжңүе…ідёҡеҠЎзҡ„ж“ҚдҪң,зј–еҶҷдёҖдёӘз”ЁжҲ·й…ҚзҪ®зҡ„json,йҖҡиҝҮжҺҘеҸЈиҝӣиЎҢжҸҗдәӨ:
#жҲ‘йҖүжӢ©жҠҠз”ЁжҲ·й…ҚзҪ®дҝқеӯҳдёӢжқҘ.з”ұдәҺжҲ‘зҡ„kafkaйғҪдёҚеңЁдёҖдёӘж–Ү件еӨ№дёӢйқў,жүҖд»ҘжҲ‘жҠҠй…ҚзҪ®ж–Ү件йғҪеӯҳеңЁconfluent/usrдёӯ.е…¶е®һеӯҳдёҚеӯҳйғҪж— жүҖи°“зҡ„.жҢүз…§е®ҳж–№ж–ҮжЎЈ,жҲ‘йҖүжӢ©еӯҳдёӢжқҘ.
#еҪ“еҲӣе»әеҘҪkafka connectorд№ӢеҗҺ,дјҡиҮӘеҠЁеҲӣе»әkafka topic.еҗҚз§°дёә ${server.name}.$tableName.debeziumдёҚиғҪзӣ‘еҗ¬еҚ•зӢ¬дёҖеј иЎЁ,жүҖжңүиЎЁйғҪдјҡжңүеҜ№еә”зҡ„topic.
cd $CONFLUENT
mkdir usr
cd usr
vi register-sqlserver.json
{
"name": "inventory-connector",
"config": {
"connector.class" : "io.debezium.connector.sqlserver.SqlServerConnector",
"tasks.max" : "1",
"database.server.name" : "server.name",
"database.hostname" : "localhost",
"database.port" : "1433",
"database.user" : "sa",
"database.password" : "password!",
"database.dbname" : "rcscounty_quannan",
"database.history.kafka.bootstrap.servers" : "centos04:9092",
"database.history.kafka.topic": "schema-changes.inventory"
}
}
curl -i -X POST -H "Accept:application/json" -H "Content-Type:application/json" http://centos04:8083/connectors/ -d @register-sqlserver.jsonжҸҗдәӨеӨұиҙҘдјҡжңүй”ҷиҜҜдҝЎжҒҜ.зңӢзңӢй”ҷиҜҜдҝЎжҒҜжҳҜд»Җд№Ҳ然еҗҺи·ҹзқҖж”№е°ұеҸҜд»ҘдәҶ.еҪ“жҸҗдәӨжҲҗеҠҹеҗҺ,еҶҚжҹҘзңӢеҪ“еүҚиҝҗиЎҢзҡ„Task,е°ұдјҡеҮәзҺ°жңүдёҖдёӘconnector:
[root@centos04 huishui]# curl -s centos04:8083/connectors | jq
[
"inventory-connector"
]
жҹҘзңӢkafka topic:
kafka-topics --list --zookeeper centos04:2181
дјҡзңӢи§ҒkafkaеҲӣе»әеҘҪдәҶtopic,еҒҮеҰӮжІЎжңүеҜ№еә”зҡ„topic,йӮЈд№ҲеҸҜиғҪжҳҜconnectorеңЁиҝҗиЎҢж—¶еҮәзҺ°дәҶй—®йўҳ.жҹҘзңӢеҪ“ж—¶еҲӣе»әзҡ„connectorзҠ¶жҖҒ:
[root@centos04 usr]# curl -s centos04:8083/connectors/inventory-connector/status | jq
{
"name": "inventory-connector",
"connector": {
"state": "RUNNING",
"worker_id": "192.168.49.104:8083"
},
"tasks": [
{
"id": 0,
"state": "RUNNING",
"worker_id": "192.168.49.104:8083"
}
],
"type": "source"
}жҲ‘иҝҷдёӘжҳҜиҝҗиЎҢиүҜеҘҪзҡ„зҠ¶жҖҒ.иҝҗиЎҢжІЎжңүй—®йўҳ,е°ұејҖе§Ӣзӣ‘еҗ¬ејҖеҗҜдәҶCDCеҠҹиғҪзҡ„иЎЁеҜ№еә”зҡ„topic,зңӢзңӢжҳҜеҗҰиғҪеӨҹжҲҗеҠҹзӣ‘еҗ¬иЎЁзҡ„ж”№еҠЁ:
kafka-console-consumer --bootstrap-server centos04:9092 --topic server.name.tableName
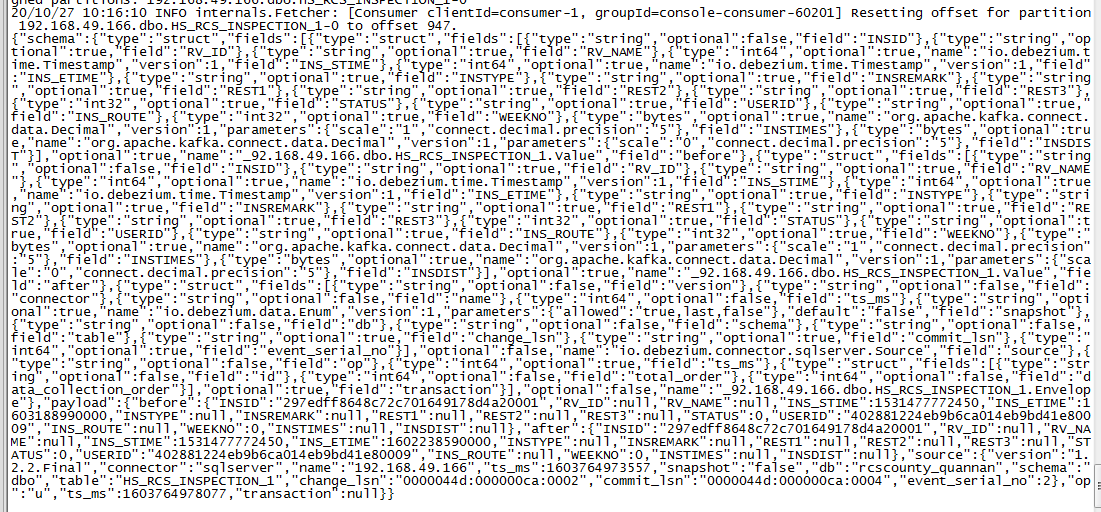
еҸҜд»ҘзңӢеҲ°дёҖж¬ЎDebezium connector еҲӣе»әзҡ„topicдј йҖ’зҡ„ж¶ҲжҒҜйқһеёёеӨҡ,еҸҜиғҪйңҖиҰҒдҝ®ж”№kafkaжңҖеӨ§ж¶ҲжҒҜдҪ“.жҲ‘д№ӢеүҚи®ҫзҪ®зҡ„жҳҜ9M,жүҖд»ҘиҝҷйҮҢжІЎйҒҮеҲ°й—®йўҳ.
Debezium дј йҖ’зҡ„ж•°жҚ®еә“еҸҳеҠЁ,ж–°еўһ\дҝ®ж”№\еҲ йҷӨ\жЁЎејҸжӣҙж”№зҡ„jsonйғҪжңүжүҖдёҚеҗҢ,е…·дҪ“иҜҰжғ…иҜ·зңӢз”ЁдәҺSQL Serverзҡ„DebeziumиҝһжҺҘеҷЁ.
жҖ»д№ӢиғҪзңӢеҲ°еҸҳеҠЁе°ұиҜҙжҳҺи°ғиҜ•жҲҗеҠҹгҖӮ
е…ідәҺеҰӮдҪ•иҝӣиЎҢkafka connector зӣ‘еҗ¬sqlserverзҡ„е°қиҜ•й—®йўҳзҡ„и§Јзӯ”е°ұеҲҶдә«еҲ°иҝҷйҮҢдәҶпјҢеёҢжңӣд»ҘдёҠеҶ…е®№еҸҜд»ҘеҜ№еӨ§е®¶жңүдёҖе®ҡзҡ„её®еҠ©пјҢеҰӮжһңдҪ иҝҳжңүеҫҲеӨҡз–‘жғ‘жІЎжңүи§ЈејҖпјҢеҸҜд»Ҙе…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“дәҶи§ЈжӣҙеӨҡзӣёе…ізҹҘиҜҶгҖӮ





