这期内容当中小编将会给大家带来有关如何实现Elasticsearch环境搭建,文章内容丰富且以专业的角度为大家分析和叙述,阅读完这篇文章希望大家可以有所收获。
Elasticsearch:7.9.3
JDK: 15.1(虽然ES自带的有JDK,但是还是建议使用自己安装的)
Kibana:7.9.3(最好跟es对应)
CentOS: 7(内存2GB,CPU两核心),三台虚拟机器(买不起云服务)
elasticsearch-head(可选)
Elasticsearch 对应的JDK版本可以在这查看https://www.elastic.co/cn/support/matrix#matrix_jvm ,7.9.3对应JDK已经支持到JDK15了,所以这里选择使用最新的JDK15;配置好JDK以后可以查看一下默认使用的垃圾回收器
java -XX:+PrintCommandLineFlags -version

sysctl.conf
vm.max_map_count配置过小es可能起不来,需要根据实际情况修改
修改完毕需要执行
sysctl -p使之生效, 可以通过sysctl -a|grep vm.max_map_count命令查看是否生效
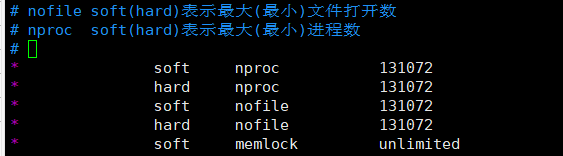
/etc/security/limits.conf
elasticsearch.yml
# 集群名称
cluster.name: Bellamy-cluster
# 节点名称
node.name: bellamy-${HOSTNAME}
# 配置数据及日志的存储地址,默认在应用目录下
#path.data: /path/to/data
#path.logs: /path/to/logs
#
network.host: 你的IP
# Set a custom port for HTTP:
#
http.port: 9200
transport.port: 9300
# 集群有几台,填写几台,两个配置相同即可
discovery.seed_hosts: ["ip1:9300", "ip2:9300","ip3:9300"]
cluster.initial_master_nodes: ["ip1:9300", "ip2:9300","ip3:9300"]jvm.options
# 内存没那么大,就配置512m, 小于或等于主机的1/2,最大不要超过或等于32GB -Xms512m -Xmx512m # 14以上的版本默认支持的垃圾回收器是G1 14-:-XX:+UseG1GC 14-:-XX:G1ReservePercent=25 14-:-XX:InitiatingHeapOccupancyPercent=30
为es创建一个单独的账号,并切换到当前用户(必须)
需要为es创建一个单独的账号才行,如果在root账户下运行的话启动会报错,而且会生成一些文件,并且需要删除才行,最好配置完毕提前切换账户
执行 ./elasticsearch(可执行文件在bin目录下)
可以使用后台模式:./elasticsearch -d, 这里为了方便查看启动日志,使用 ./elasticsearch即可
可能还会有其他的报错,根据日志提示做修改即可
kibana.yml
# port server.port: 5601 server.name: "bellamy" # es地址 elasticsearch.hosts: ["http://ip1:9200", "http://ip2:9200", "http://ip3:9200"] # kibana本身不存储数据,他的元数据信息是放到es上的,尽量不要改动,可以加个后缀,如下 kibana.index: ".kibana-bellamy"
./kibana
kibana是node写的,所以想要后台模式需要使用nohup命令
Stack Monitoring 菜单下可以看到我们的配置信息 
# 下载 https://github.com/mobz/elasticsearch-head.git # 执行npm安装命令 npm install # 启动 npm run start #访问 http://localhost:9100/ # 在操作界面任意连接一台es地址即可
上述就是小编为大家分享的如何实现Elasticsearch环境搭建了,如果刚好有类似的疑惑,不妨参照上述分析进行理解。如果想知道更多相关知识,欢迎关注亿速云行业资讯频道。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。






