结构化文本是很常见的文件格式,对结构化文本的计算也是很常见的需求。在实现这种计算时,一种很容易想到的办法是将文件导入数据库后再计算,但这会消耗大量时间以及昂贵的数据库资源,而且有的场合下并没有合适的数据库可用。这样一来,我们就会有一个自然的想法,如果能够直接计算就会方便多了。可惜的是,一般高级语言都没有提供针对结构化文本的基本运算类库,而想要通过硬编码完成这些运算又非常繁琐,不仅代码复杂,可维护性还很差。
作为专业的结构化数据计算类库,集算器SPL封装了丰富的结构化计算函数,支持集合运算、关联运算、有序运算,因此可轻松实现结构化文本的运算。此外,SPL还可以通过JDBC调用接口向Java应用提供运算结果(可参考【Java 如何调用 SPL 脚本】),极大地方便集成工作。
下面我们就来看一下常见的结构化文本计算案例,以及SPL对应的解法。
在sales.txt的第2行插入1条记录。源文件如下:
| OrderID | Client | SellerId | Amount | OrderDate |
| 26 | TAS | 1 | 2142.4 | 2009-08-05 |
| 33 | DSGC | 1 | 613.2 | 2009-08-14 |
| 84 | GC | 1 | 88.5 | 2009-10-16 |
| 133 | HU | 1 | 1419.8 | 2010-12-12 |
| 32 | JFS | 3 | 468 | 2009-08-13 |
| 39 | NR | 3 | 3016 | 2010-08-21 |
| 43 | KT | 3 | 2169 | 2009-08-27 |
代码
| A | |
| 1 | =file("D:\\sales.txt").import@t() |
| 2 | =A1.insert(2,200,"MS",20,2000,date("2015-02-02")) |
| 3 | =file("D:\\sales.txt").export@t(A1) |
结果
| OrderID | Client | SellerId | Amount | OrderDate |
| 26 | TAS | 1 | 2142.4 | 2009-08-05 |
| 200 | MS | 20 | 2000 | 2015-02-02 |
| 33 | DSGC | 1 | 613.2 | 2009-08-14 |
| 84 | GC | 1 | 88.5 | 2009-10-16 |
| 133 | HU | 1 | 1419.8 | 2010-12-12 |
| 32 | JFS | 3 | 468 | 2009-08-13 |
| 39 | NR | 3 | 3016 | 2010-08-21 |
| 43 | KT | 3 | 2169 | 2009-08-27 |
函数insert插入记录,第1个参数是插入位置,当该参数为0时,表示追加记录。
如果只是向文件追加记录,那么不必读入文件,只需用函数export@a,代码如下:
| A | |
| 1 | =create(OrderID,Client,SellerId,Amount,OrderDate).record([200,"MS",20,2000,date("2015-02-02")]) |
| 2 | =file("D:\\sales.txt").export@a(A1) |
函数create新建二维表,函数record向二维表追加记录。
另外,可以通过insert@r批量插入记录,代码如下:
| A | |
| 1 | =file("D:\\sales.txt").import@t() |
| 2 | =create(OrderID,Client,SellerId,Amount,OrderDate) |
| 3 | =A2.record([200,"MS",20,2000,date("2015-02-02"), 300,"Ora",30,3000,date("2015-03-03")]) |
| 4 | =A1.insert@r(2:A2) |
为节省篇幅起见,下文都将省略导出文件的代码。
删除sales.txt中的第2条记录。代码如下:
| A | |
| 1 | =file("D:\\sales.txt").import@t() |
| 2 | =A1.delete(2) |
函数delete支持批量删除,比如删除第2,3,5,6,7条记录:A1.delete([2,3]|to(5,7))
也可以按条件删除,比如删除Amount小于1000的记录:A1.delete(A1.select(Amount<1000))
修改sales.txt的第2条记录,将SellerId改为100,Amount改为1000,代码如下:
| A | |
| 1 | =file("D:\\sales.txt").import@t() |
| 2 | =A1.modify(2,100:SellerId,1000:Amount) |
也可以批量修改,比如将前10条记录的Amount增加10:
A1.modify(1:10,Amount+10:Amount)
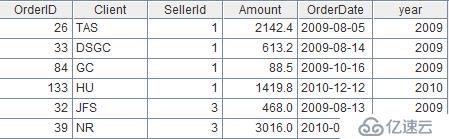
在sales.txt增加列year,填入订单日期OrerDate中的年份。代码:
| A | |
| 1 | =file("D:\\sales.txt").import@t() |
| 2 | =A1.derive(year(OrderDate):year) |
结果:
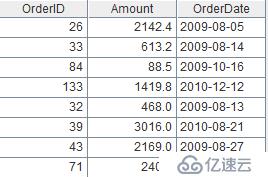
物理上删除列效率较低,通常用“取出保留列”来代替。比如sales.txt中删除Client、SellerId,相当于保留OrderID、Amount、OrderDate,代码如下:
| A | |
| 1 | =file("D:\\sales.txt").import@t() |
| 2 | =A1.new(OrderID,Amount,OrderDate) |
结果:
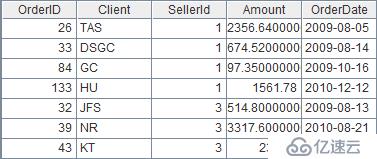
将sales.txt的Amount列增加10%,代码如下:
| A | |
| 1 | =file("D:\\sales.txt").import@t() |
| 2 | =A1.run(Amount*1.1:Amount) |
结果:
注意函数run跟函数modify的区别:修改整列(所有记录的对应字段)需要用run,只修改指定记录的某列(特定字段)用modify。
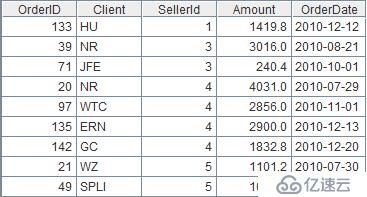
指定时间段,按参数查询sales.txt。代码:
| A | |
| 1 | =file("D:\\sales.txt").import@t() |
| 2 | =A1.select(OrderDate>=startDate && OrderDate<=endDate) |
startDate和endDate是输入参数,比如2010-01-01至2010-12-31。结果:
针对sales.txt,按照客户代码(Client)降序排序,按照订单日期(OrderDate)升序排序。
代码:
| A | |
| 1 | =file("D:\\sales.txt").import@t() |
| 2 | =A1.sort(-Client,OrderDate) |
注意:降序时在字段前面使用英文的减号来表示,即“-”,默认按照升序。
结果:
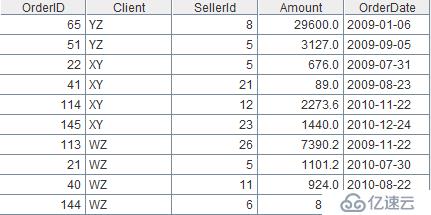
计算出每个销售员每年的销售额和订单数,即按照销售员分组,对销售额求和,对记录计数。
代码:
| A | |
| 1 | =file("D:\\sales.txt").import@t() |
| 2 | =A1.groups(SellerId,year(OrderDate);sum(Amount),count(~)) |
函数groups可在分组的同时进行汇总,其中,~表示每组或当前组,count(~)等于count(OrderID)。
结果:
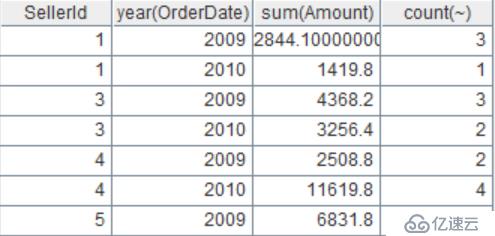
列出sales.txt中的客户名单,即获取所有Client的唯一值。
代码:
| A | |
| 1 | =file("D:\\sales.txt").import@t() |
| 2 | =A1.id(Client) |
结果:
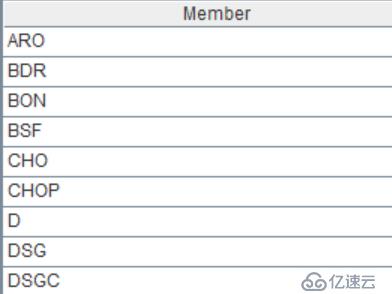
保留sales.txt中每个客户每个销售员的第一条记录。获取唯一值也是一种去重,这里是另外一种通过分组来去除重复的方式。
代码:
| A | |
| 1 | =file("D:\\sales.txt").import@t() |
| 2 | =A1.group@1(Client,SellerId) |
通过函数group进行分组(和groups不同,这里可以不汇总),@1表示取每组第1条记录。
结果:
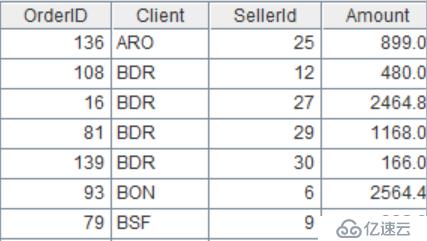
找到每个销售员销售额最大的3笔订单。
代码:
| A | |
| 1 | =file("D:\\sales.txt").import@t() |
| 2 | =A1.group(SellerId;~.top(3;-Amount):t).conj(t) |
函数top过滤出TopN,”-”表示逆序,函数conj用于合并结果。
计算结果:
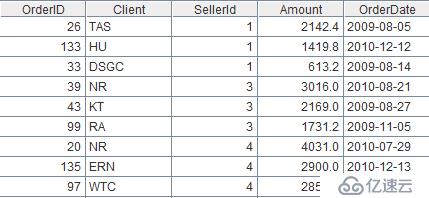
如果只取最大的一笔订单,还可以用maxp函数,不过 maxp直接返回表达式描述的最大记录,因此不用再加符号”-”来描述排序方式。由于分组后的字段t的内容是记录,因此不能用conj(t)来合并,而是需要使用A.(t)方式直接取出t字段。所以取每个销售的最大一笔订单表达式为:=A1.group(SellerId;~.maxp(Amount):t).(t)
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





