1.在终端输入scrapy命令可以查看可用命令
Usage:
scrapy <command> [options] [args]
Available commands:
bench Run quick benchmark test
fetch Fetch a URL using the Scrapy downloader
genspider Generate new spider using pre-defined templates
runspider Run a self-contained spider (without creating a project)
settings Get settings values
shell Interactive scraping console
startproject Create new project
version Print Scrapy version
view Open URL in browser, as seen by Scrapyscrapy架构
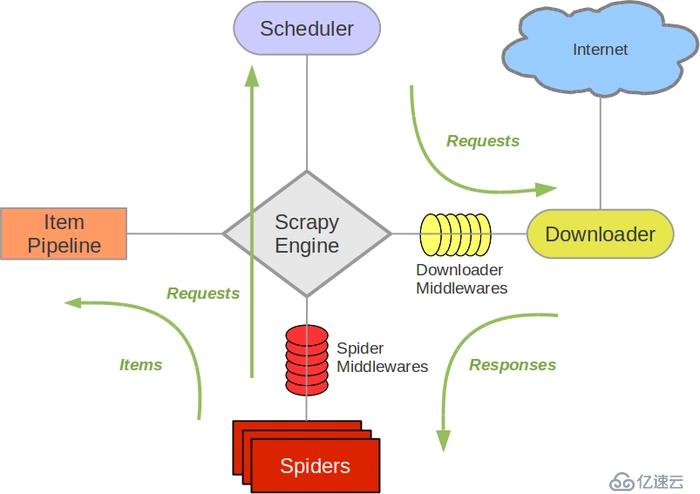
爬虫概念流程
概念:亦可以称为网络蜘蛛或网络机器人,是一个模拟浏览器请求网站行为的程序,可以自动请求网页,把数据抓取下来,然后使用一定规则提取有价值的数据。
基本流程:
发起请求-->获取响应内容-->解析内容-->保存处理

import scrapy
class DoubanItem(scrapy.Item):
#序号
serial_number=scrapy.Field()
#名称
movie_name=scrapy.Field()
#介绍
introduce=scrapy.Field()
#星级
star=scrapy.Field()
#评论
evalute=scrapy.Field()
#描述
desc=scrapy.Field()3.编写Spider文件,爬虫主要是该文件实现
进到根目录,执行命令:scrapy genspider spider_name "domains" : spider_name为爬虫名称唯一,"domains",指定爬取域范围,即可创建spider文件,当然这个文件可以自己手动创建。
进程scrapy.Spider类,里面的方法可以覆盖。
import scrapy
from ..items import DoubanItem
class DoubanSpider(scrapy.Spider):
name='douban_mv'
allowed_domains=['movie.douban.com']
start_urls=['https://movie.douban.com/top250']
def parse(self, response):
movie_list=response.xpath("//div[@class='article']//ol[@class='grid_view']//li//div[@class='item']")
for movie in movie_list:
items=DoubanItem()
items['serial_number']=movie.xpath('.//div[@class="pic"]/em/text()').extract_first()
items['movie_name']=movie.xpath('.//div[@class="hd"]/a/span/text()').extract_first()
introduce=movie.xpath('.//div[@class="bd"]/p/text()').extract()
items['introduce']=";".join(introduce).replace(' ','').replace('\n','').strip(';')
items['star']=movie.xpath('.//div[@class="star"]/span[@class="rating_num"]/text()').extract_first()
items['evalute']=movie.xpath('.//div[@class="star"]/span[4]/text()').extract_first()
items['desc']=movie.xpath('.//p[@class="quote"]/span[@class="inq"]/text()').extract_first()
yield items
"next-page"实现翻页操作
link=response.xpath('//span[@class="next"]/link/@href').extract_first()
if link:
yield response.follow(link,callback=self.parse) 4.编写pipelines.py文件
清理html数据、验证爬虫数据,去重并丢弃,文件保存csv,json,db.,每个item pipeline组件生效需要在setting中开启才生效,且要调用process_item(self,item,spider)方法。
open_spider(self,spider) :当spider被开启时,这个方法被调用
close_spider(self, spider) :当spider被关闭时,这个方法被调用
# -*- coding: utf-8 -*-
# Define your item pipelines here
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
import json
import csv
class TutorialPipeline(object):
def open_spider(self,spider):
pass
def __init__(self):
self.file=open('item.json','w',encoding='utf-8')
def process_item(self, item, spider):
line=json.dumps(dict(item),ensure_ascii=False)+"\n"
self.file.write(line)
return item
class DoubanPipeline(object):
def open_spider(self,spider):
self.csv_file=open('movies.csv','w',encoding='utf8',newline='')
self.writer=csv.writer(self.csv_file)
self.writer.writerow(["serial_number","movie_name","introduce","star","evalute","desc"])
def process_item(self,item,spider):
self.writer.writerow([v for v in item.values()])
def close_spider(self,spider):
self.csv_file.close()5.开始运行爬虫
scrapy crawl "spider_name" 即可爬取在terminal中显示信息,注spider_name为spider文件中name名称。
在命令行也可以直接输出文件并保存,步骤4可以不开启:
scrapy crawl demoz -o items.json
scrapy crawl itcast -o teachers.csv
scrapy crawl itcast -o teachers.xmlscrapy常用设置
修改配置文件:setting.py
每个pipeline后面有一个数值,这个数组的范围是0-1000,这个数值确定了他们的运行顺序,数字越小越优先
DEPTH_LIMIT :爬取网站最大允许的深度(depth)值。如果为0,则没有限制
FEED_EXPORT_ENCODING = 'utf-8' 设置编码
DOWNLOAD_DELAY=1:防止过于频繁,误认为爬虫
USAGE_AGENT:设置代理
LOG_LEVEL = 'INFO':设置日志级别,资源
COOKIES_ENABLED = False:禁止cookie
CONCURRENT_REQUESTS = 32:并发数量
设置请求头:DEFAULT_REQUEST_HEADERS={...}
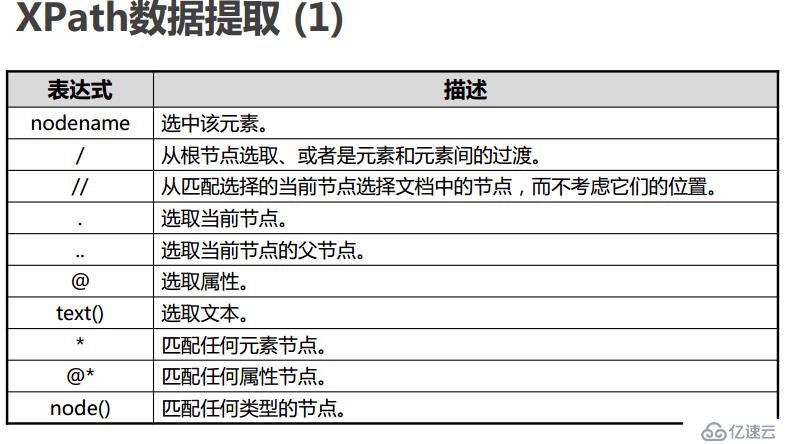
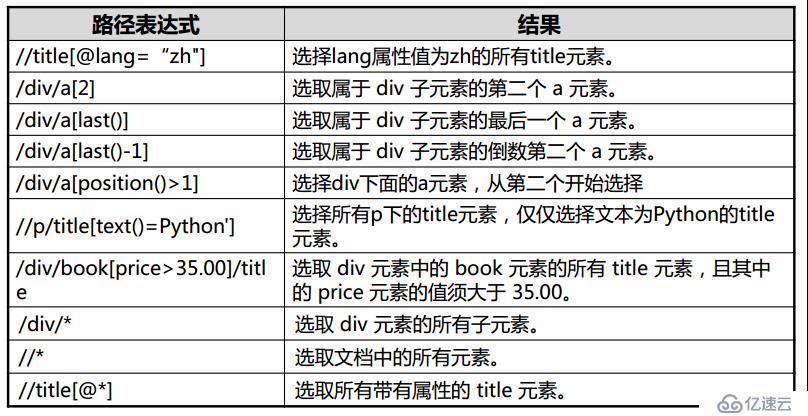
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





