KubernetesеҰӮдҪ•йҖҡиҝҮDevice PluginsжқҘдҪҝз”ЁNVIDIA GPU
жң¬зҜҮж–Үз« дёәеӨ§е®¶еұ•зӨәдәҶKubernetesеҰӮдҪ•йҖҡиҝҮDevice PluginsжқҘдҪҝз”ЁNVIDIA GPUпјҢеҶ…е®№з®ҖжҳҺжүјиҰҒ并且容жҳ“зҗҶи§ЈпјҢз»қеҜ№иғҪдҪҝдҪ зңјеүҚдёҖдә®пјҢйҖҡиҝҮиҝҷзҜҮж–Үз« зҡ„иҜҰз»Ҷд»Ӣз»ҚеёҢжңӣдҪ иғҪжңүжүҖ收иҺ·гҖӮ
Device Plugins
Device PulginsеңЁKubernetes 1.10дёӯжҳҜbetaзү№жҖ§пјҢејҖе§ӢдәҺKubernetes 1.8пјҢз”ЁжқҘз»ҷ第дёүж–№и®ҫеӨҮеҺӮе•ҶйҖҡиҝҮжҸ’件еҢ–зҡ„ж–№ејҸе°Ҷи®ҫеӨҮиө„жәҗеҜ№жҺҘеҲ°KubernetesпјҢз»ҷе®№еҷЁжҸҗдҫӣExtended ResourcesгҖӮ
йҖҡиҝҮDevice Pluginsж–№ејҸпјҢз”ЁжҲ·дёҚйңҖиҰҒж”№Kubernetesзҡ„д»Јз ҒпјҢз”ұ第дёүж–№и®ҫеӨҮеҺӮе•ҶејҖеҸ‘жҸ’件пјҢе®һзҺ°Kubernetes Device Pluginsзҡ„зӣёе…іжҺҘеҸЈеҚіеҸҜгҖӮ
зӣ®еүҚе…іжіЁеәҰжҜ”иҫғй«ҳзҡ„Device Pluginsе®һзҺ°жңүпјҡ
NvidiaжҸҗдҫӣзҡ„GPUжҸ’件пјҡNVIDIA device plugin for Kubernetes
й«ҳжҖ§иғҪдҪҺ延иҝҹRDMAеҚЎжҸ’件пјҡRDMA device plugin for Kubernetes
дҪҺ延иҝҹSolarflareдёҮе…ҶзҪ‘еҚЎй©ұеҠЁпјҡSolarflare Device Plugin
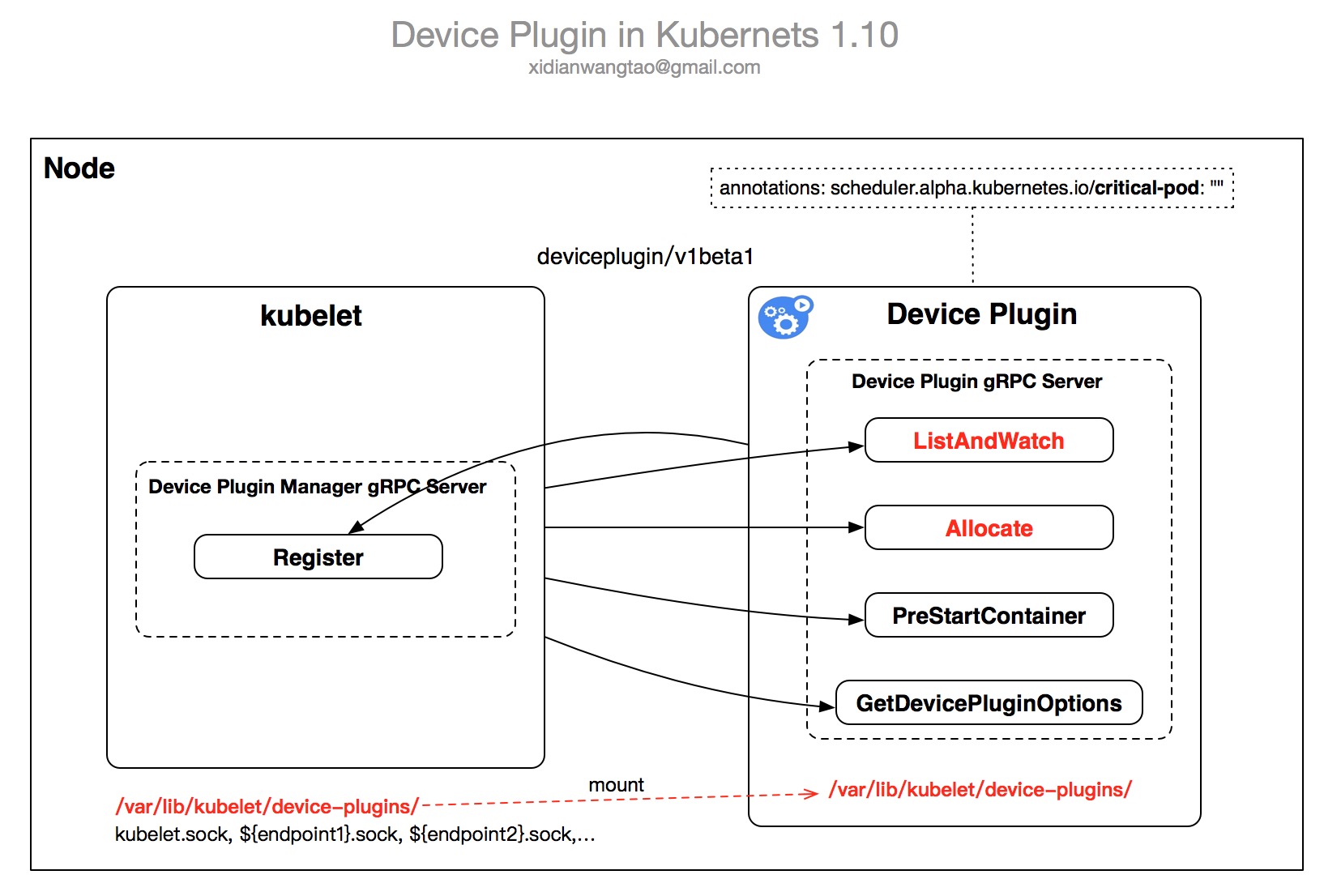
Device pluginsеҗҜеҠЁж—¶пјҢеҜ№еӨ–жҡҙйңІеҮ дёӘgRPC ServiceжҸҗдҫӣжңҚеҠЎпјҢ并йҖҡиҝҮ/var/lib/kubelet/device-plugins/kubelet.sockеҗ‘kubeletиҝӣиЎҢжіЁеҶҢгҖӮ
Device Plugins Registration
еңЁKubernetes 1.10д№ӢеүҚзҡ„зүҲжң¬пјҢй»ҳи®Өdisable DevicePluginsпјҢз”ЁжҲ·йңҖиҰҒеңЁFeature GateдёӯenableгҖӮ
еңЁKubernetes 1.10пјҢй»ҳи®Өenable DevicePluginsпјҢз”ЁжҲ·еҸҜд»ҘеңЁFeature Gateдёӯdisable itгҖӮ
еҪ“DevicePlugins Feature Gate enableпјҢkubeletе°ұдјҡжҡҙйңІдёҖдёӘRegister gRPCжҺҘеҸЈгҖӮDevice PluginsйҖҡиҝҮи°ғз”ЁRegisterжҺҘеҸЈе®ҢжҲҗDeviceзҡ„жіЁеҶҢгҖӮ
RegisterжҺҘеҸЈжҸҸиҝ°еҰӮдёӢпјҡ
pkg/kubelet/apis/deviceplugin/v1beta1/api.pb.go:440
type RegistrationServer interface {
Register(context.Context, *RegisterRequest) (*Empty, error)
}
pkg/kubelet/apis/deviceplugin/v1beta1/api.pb.go:87
type RegisterRequest struct {
// Version of the API the Device Plugin was built against
Version string `protobuf:"bytes,1,opt,name=version,proto3" json:"version,omitempty"`
// Name of the unix socket the device plugin is listening on
// PATH = path.Join(DevicePluginPath, endpoint)
Endpoint string `protobuf:"bytes,2,opt,name=endpoint,proto3" json:"endpoint,omitempty"`
// Schedulable resource name. As of now it's expected to be a DNS Label
ResourceName string `protobuf:"bytes,3,opt,name=resource_name,json=resourceName,proto3" json:"resource_name,omitempty"`
// Options to be communicated with Device Manager
Options *DevicePluginOptions `protobuf:"bytes,4,opt,name=options" json:"options,omitempty"`
}
RegisterRequestиҰҒжұӮзҡ„еҸӮж•°еҰӮдёӢпјҡ
еҜ№дәҺnvidia gpuпјҢеҸӘжңүдёҖдёӘPreStartRequiredйҖүйЎ№пјҢиЎЁзӨәжҜҸдёӘContainerеҗҜеҠЁеүҚжҳҜеҗҰиҰҒи°ғз”ЁDevice Pluginзҡ„PreStartContainerжҺҘеҸЈпјҲжҳҜKubernetes 1.10дёӯDevice Plugin InterfaceжҺҘеҸЈд№ӢдёҖпјүпјҢй»ҳи®ӨдёәfalseгҖӮ
vendor/k8s.io/kubernetes/pkg/kubelet/apis/deviceplugin/v1beta1/api.pb.go:71
func (m *NvidiaDevicePlugin) GetDevicePluginOptions(context.Context, *pluginapi.Empty) (*pluginapi.DevicePluginOptions, error) {
return &pluginapi.DevicePluginOptions{}, nil
}
github.com/NVIDIA/k8s-device-plugin/server.go:80
type DevicePluginOptions struct {
// Indicates if PreStartContainer call is required before each container start
PreStartRequired bool `protobuf:"varint,1,opt,name=pre_start_required,json=preStartRequired,proto3" json:"pre_start_required,omitempty"`
}
Version, зӣ®еүҚжңүv1alpha,v1beta1дёӨдёӘзүҲжң¬гҖӮ
Endpoint, иЎЁзӨәdevice pluginжҡҙйңІзҡ„socketеҗҚз§°пјҢRegisterж—¶дјҡж №жҚ®Endpointз”ҹжҲҗpluginзҡ„socketж”ҫеңЁ/var/lib/kubelet/device-plugins/зӣ®еҪ•дёӢпјҢжҜ”еҰӮNvidia GPU Device PluginеҜ№еә”/var/lib/kubelet/device-plugins/nvidia.sockгҖӮ
ResourceName, йЎ»жҢүз…§Extended Resource Naming Schemeж јејҸvendor-domain/resourceпјҢжҜ”еҰӮnvidia.com/gpu
DevicePluginOptions, дҪңдёәkubeletдёҺdevice pluginйҖҡдҝЎж—¶зҡ„йўқеӨ–еҸӮж•°дј йҖ’гҖӮ
еүҚйқўжҸҗеҲ°Device Plugin Interfaceзӣ®еүҚжңүv1alpha, v1beta1дёӨдёӘзүҲжң¬пјҢжҜҸдёӘзүҲжң¬еҜ№еә”зҡ„жҺҘеҸЈеҰӮдёӢпјҡ
/v1beta1.Registration/Register
/v1beta1.Registration/Register
pkg/kubelet/apis/deviceplugin/v1beta1/api.pb.go:466
var _Registration_serviceDesc = grpc.ServiceDesc{
ServiceName: "v1beta1.Registration",
HandlerType: (*RegistrationServer)(nil),
Methods: []grpc.MethodDesc{
{
MethodName: "Register",
Handler: _Registration_Register_Handler,
},
},
Streams: []grpc.StreamDesc{},
Metadata: "api.proto",
}
/v1beta1.DevicePlugin/ListAndWatch
/v1beta1.DevicePlugin/Allocate
/v1beta1.DevicePlugin/PreStartContainer
/v1beta1.DevicePlugin/GetDevicePluginOptions
pkg/kubelet/apis/deviceplugin/v1beta1/api.pb.go:665
var _DevicePlugin_serviceDesc = grpc.ServiceDesc{
ServiceName: "v1beta1.DevicePlugin",
HandlerType: (*DevicePluginServer)(nil),
Methods: []grpc.MethodDesc{
{
MethodName: "GetDevicePluginOptions",
Handler: _DevicePlugin_GetDevicePluginOptions_Handler,
},
{
MethodName: "Allocate",
Handler: _DevicePlugin_Allocate_Handler,
},
{
MethodName: "PreStartContainer",
Handler: _DevicePlugin_PreStartContainer_Handler,
},
},
Streams: []grpc.StreamDesc{
{
StreamName: "ListAndWatch",
Handler: _DevicePlugin_ListAndWatch_Handler,
ServerStreams: true,
},
},
Metadata: "api.proto",
}
/deviceplugin.Registration/Register
pkg/kubelet/apis/deviceplugin/v1alpha/api.pb.go:374
var _Registration_serviceDesc = grpc.ServiceDesc{
ServiceName: "deviceplugin.Registration",
HandlerType: (*RegistrationServer)(nil),
Methods: []grpc.MethodDesc{
{
MethodName: "Register",
Handler: _Registration_Register_Handler,
},
},
Streams: []grpc.StreamDesc{},
Metadata: "api.proto",
}
/deviceplugin.DevicePlugin/Allocate
/deviceplugin.DevicePlugin/ListAndWatch
pkg/kubelet/apis/deviceplugin/v1alpha/api.pb.go:505
var _DevicePlugin_serviceDesc = grpc.ServiceDesc{
ServiceName: "deviceplugin.DevicePlugin",
HandlerType: (*DevicePluginServer)(nil),
Methods: []grpc.MethodDesc{
{
MethodName: "Allocate",
Handler: _DevicePlugin_Allocate_Handler,
},
},
Streams: []grpc.StreamDesc{
{
StreamName: "ListAndWatch",
Handler: _DevicePlugin_ListAndWatch_Handler,
ServerStreams: true,
},
},
Metadata: "api.proto",
}
v1alpha:
v1beta1:
еҪ“Device PluginжҲҗеҠҹжіЁеҶҢеҗҺпјҢе®ғе°ҶйҖҡиҝҮListAndWatchеҗ‘kubeletеҸ‘йҖҒе®ғз®ЎзҗҶзҡ„deviceеҲ—иЎЁпјҢkubelet收еҲ°ж•°жҚ®еҗҺйҖҡиҝҮAPI Serverжӣҙж–°etcdдёӯеҜ№еә”nodeзҡ„statusдёӯгҖӮ
然еҗҺз”ЁжҲ·е°ұиғҪеңЁContainer Spec requestдёӯиҜ·жұӮеҜ№еә”зҡ„deviceпјҢжіЁж„Ҹд»ҘдёӢйҷҗеҲ¶пјҡ
Extended ResourceеҸӘж”ҜжҢҒиҜ·жұӮж•ҙж•°дёӘdeviceпјҢдёҚж”ҜжҢҒе°Ҹж•°зӮ№гҖӮ
дёҚж”ҜжҢҒи¶…й…ҚпјҢеҚіResource QoSеҸӘиғҪжҳҜGuaranteedгҖӮ
еҗҢдёҖеқ—DeviceдёҚиғҪеӨҡдёӘContainersе…ұдә«гҖӮ
Device Plugins Workflow
Device Pluginsзҡ„е·ҘдҪңжөҒеҰӮдёӢпјҡ
еҲқе§ӢеҢ–пјҡDevice PluginеҗҜеҠЁеҗҺпјҢиҝӣиЎҢдёҖдәӣжҸ’件зү№е®ҡзҡ„еҲқе§ӢеҢ–е·ҘдҪңд»ҘзЎ®е®ҡеҜ№еә”зҡ„DevicesеӨ„дәҺReadyзҠ¶жҖҒпјҢеҜ№дәҺNvidia GPUпјҢе°ұжҳҜеҠ иҪҪNVML LibraryгҖӮ
еҗҜеҠЁgRPCжңҚеҠЎпјҡйҖҡиҝҮ/var/lib/kubelet/device-plugins/${Endpoint}.sockеҜ№еӨ–жҡҙйңІgRPCжңҚеҠЎпјҢдёҚеҗҢзҡ„API VersionеҜ№еә”дёҚеҗҢзҡ„жңҚеҠЎжҺҘеҸЈпјҢеүҚйқўе·Із»ҸжҸҗиҝҮпјҢдёӢйқўжҳҜжҜҸдёӘжҺҘеҸЈзҡ„жҸҸиҝ°гҖӮ
ListAndWatch
Allocate
GetDevicePluginOptions
PreStartContainer
pkg/kubelet/apis/deviceplugin/v1beta1/api.proto
// DevicePlugin is the service advertised by Device Plugins
service DevicePlugin {
// GetDevicePluginOptions returns options to be communicated with Device
// Manager
rpc GetDevicePluginOptions(Empty) returns (DevicePluginOptions) {}
// ListAndWatch returns a stream of List of Devices
// Whenever a Device state change or a Device disapears, ListAndWatch
// returns the new list
rpc ListAndWatch(Empty) returns (stream ListAndWatchResponse) {}
// Allocate is called during container creation so that the Device
// Plugin can run device specific operations and instruct Kubelet
// of the steps to make the Device available in the container
rpc Allocate(AllocateRequest) returns (AllocateResponse) {}
// PreStartContainer is called, if indicated by Device Plugin during registeration phase,
// before each container start. Device plugin can run device specific operations
// such as reseting the device before making devices available to the container
rpc PreStartContainer(PreStartContainerRequest) returns (PreStartContainerResponse) {}
}
ListAndWatch
Allocate
pkg/kubelet/apis/deviceplugin/v1alpha/api.proto
// DevicePlugin is the service advertised by Device Plugins
service DevicePlugin {
// ListAndWatch returns a stream of List of Devices
// Whenever a Device state changes or a Device disappears, ListAndWatch
// returns the new list
rpc ListAndWatch(Empty) returns (stream ListAndWatchResponse) {}
// Allocate is called during container creation so that the Device
// Plugin can run device specific operations and instruct Kubelet
// of the steps to make the Device available in the container
rpc Allocate(AllocateRequest) returns (AllocateResponse) {}
}
v1alphaпјҡ
v1beta1пјҡ
Device PluginйҖҡиҝҮ/var/lib/kubelet/device-plugins/kubelet.sockеҗ‘kubeletиҝӣиЎҢжіЁеҶҢгҖӮ
жіЁеҶҢжҲҗеҠҹеҗҺпјҢDevice Pluginе°ұжӯЈејҸиҝӣе…ҘдәҶServingжЁЎејҸпјҢжҸҗдҫӣеүҚйқўжҸҗеҲ°зҡ„gRPCжҺҘеҸЈи°ғз”ЁжңҚеҠЎпјҢдёӢйқўжҳҜv1beta1зҡ„жҜҸдёӘжҺҘеҸЈеҜ№еә”зҡ„е…·дҪ“еҲҶжһҗпјҡ
дёӢйқўжҳҜstruct Deviceзҡ„GPU Sampleпјҡ
struct Device {
ID: "GPU-fef8089b-4820-abfc-e83e-94318197576e",
State: "Healthy",
}
PreStartContainer is expected to be called before each container start if indicated by plugin during registration phase.
PreStartContainer allows kubelet to pass reinitialized devices to containers.
PreStartContainer allows Device Plugin to run device specific operations on the Devices requested.
type PreStartContainerRequest struct {
DevicesIDs []string `protobuf:"bytes,1,rep,name=devicesIDs" json:"devicesIDs,omitempty"`
}
// PreStartContainerResponse will be send by plugin in response to PreStartContainerRequest
type PreStartContainerResponse struct {
}
Allocate is expected to be called during pod creation since allocation failures for any container would result in pod startup failure.
Allocate allows kubelet to exposes additional artifacts in a pod's environment as directed by the plugin.
Allocate allows Device Plugin to run device specific operations on the Devices requested
type AllocateRequest struct {
ContainerRequests []*ContainerAllocateRequest `protobuf:"bytes,1,rep,name=container_requests,json=containerRequests" json:"container_requests,omitempty"`
}
type ContainerAllocateRequest struct {
DevicesIDs []string `protobuf:"bytes,1,rep,name=devicesIDs" json:"devicesIDs,omitempty"`
}
// AllocateResponse includes the artifacts that needs to be injected into
// a container for accessing 'deviceIDs' that were mentioned as part of
// 'AllocateRequest'.
// Failure Handling:
// if Kubelet sends an allocation request for dev1 and dev2.
// Allocation on dev1 succeeds but allocation on dev2 fails.
// The Device plugin should send a ListAndWatch update and fail the
// Allocation request
type AllocateResponse struct {
ContainerResponses []*ContainerAllocateResponse `protobuf:"bytes,1,rep,name=container_responses,json=containerResponses" json:"container_responses,omitempty"`
}
type ContainerAllocateResponse struct {
// List of environment variable to be set in the container to access one of more devices.
Envs map[string]string `protobuf:"bytes,1,rep,name=envs" json:"envs,omitempty" protobuf_key:"bytes,1,opt,name=key,proto3" protobuf_val:"bytes,2,opt,name=value,proto3"`
// Mounts for the container.
Mounts []*Mount `protobuf:"bytes,2,rep,name=mounts" json:"mounts,omitempty"`
// Devices for the container.
Devices []*DeviceSpec `protobuf:"bytes,3,rep,name=devices" json:"devices,omitempty"`
// Container annotations to pass to the container runtime
Annotations map[string]string `protobuf:"bytes,4,rep,name=annotations" json:"annotations,omitempty" protobuf_key:"bytes,1,opt,name=key,proto3" protobuf_val:"bytes,2,opt,name=value,proto3"`
}
// DeviceSpec specifies a host device to mount into a container.
type DeviceSpec struct {
// Path of the device within the container.
ContainerPath string `protobuf:"bytes,1,opt,name=container_path,json=containerPath,proto3" json:"container_path,omitempty"`
// Path of the device on the host.
HostPath string `protobuf:"bytes,2,opt,name=host_path,json=hostPath,proto3" json:"host_path,omitempty"`
// Cgroups permissions of the device, candidates are one or more of
// * r - allows container to read from the specified device.
// * w - allows container to write to the specified device.
// * m - allows container to create device files that do not yet exist.
Permissions string `protobuf:"bytes,3,opt,name=permissions,proto3" json:"permissions,omitempty"`
}
AllocateRequestе°ұжҳҜDeviceIDеҲ—иЎЁгҖӮ
AllocateResponseеҢ…жӢ¬йңҖиҰҒжіЁе…ҘеҲ°ContainerйҮҢйқўзҡ„EnvsгҖҒDevicesзҡ„жҢӮиҪҪдҝЎжҒҜ(еҢ…жӢ¬deviceзҡ„cgroup permissions)д»ҘеҸҠиҮӘе®ҡд№үзҡ„AnnotationsгҖӮ
AllocateпјҡDevice Pluginжү§иЎҢdevice-specificж“ҚдҪңпјҢиҝ”еӣһAllocateResponseз»ҷkubeletпјҢkubeletеҶҚдј з»ҷdockerd,з”ұdockerd(и°ғз”Ёnvidia-docker)еңЁеҲӣе»әе®№еҷЁж—¶еҲҶй…Қdeviceж—¶дҪҝз”ЁгҖӮдёӢйқўжҳҜиҝҷдёӘжҺҘеҸЈзҡ„Requestе’ҢResponseзҡ„жҸҸиҝ°гҖӮ
PreStartContainerпјҡ
GetDevicePluginOptions: зӣ®еүҚеҸӘжңүPreStartRequiredиҝҷдёҖдёӘfieldгҖӮ
type DevicePluginOptions struct {
// Indicates if PreStartContainer call is required before each container start
PreStartRequired bool `protobuf:"varint,1,opt,name=pre_start_required,json=preStartRequired,proto3" json:"pre_start_required,omitempty"`
}
ListAndWatchпјҡзӣ‘жҺ§еҜ№еә”Devicesзҡ„зҠ¶жҖҒеҸҳжӣҙжҲ–иҖ…DisappearдәӢ件пјҢиҝ”еӣһListAndWatchResponseз»ҷkubelet, ListAndWatchResponseе°ұжҳҜDeviceеҲ—иЎЁгҖӮ
type ListAndWatchResponse struct {
Devices []*Device `protobuf:"bytes,1,rep,name=devices" json:"devices,omitempty"`
}
type Device struct {
// A unique ID assigned by the device plugin used
// to identify devices during the communication
// Max length of this field is 63 characters
ID string `protobuf:"bytes,1,opt,name=ID,json=iD,proto3" json:"ID,omitempty"`
// Health of the device, can be healthy or unhealthy, see constants.go
Health string `protobuf:"bytes,2,opt,name=health,proto3" json:"health,omitempty"`
}
ејӮеёёеӨ„зҗҶ
жҜҸж¬ЎkubeletеҗҜеҠЁ(йҮҚеҗҜ)ж—¶пјҢйғҪдјҡе°Ҷ/var/lib/kubelet/device-pluginsдёӢзҡ„жүҖжңүsocketsж–Ү件еҲ йҷӨгҖӮ
Device PluginиҰҒиҙҹиҙЈзӣ‘жөӢиҮӘе·ұзҡ„socketиў«еҲ йҷӨпјҢ然еҗҺиҝӣиЎҢйҮҚж–°жіЁеҶҢпјҢйҮҚж–°з”ҹжҲҗиҮӘе·ұзҡ„socketгҖӮ
еҪ“plugin socketиў«иҜҜеҲ пјҢDevice PluginиҜҘжҖҺд№ҲеҠһпјҹ
жҲ‘们зңӢзңӢNvidia Device PluginжҳҜжҖҺд№ҲеӨ„зҗҶзҡ„пјҢзӣёе…ізҡ„д»Јз ҒеҰӮдёӢпјҡ
github.com/NVIDIA/k8s-device-plugin/main.go:15
func main() {
...
log.Println("Starting FS watcher.")
watcher, err := newFSWatcher(pluginapi.DevicePluginPath)
...
restart := true
var devicePlugin *NvidiaDevicePlugin
L:
for {
if restart {
if devicePlugin != nil {
devicePlugin.Stop()
}
devicePlugin = NewNvidiaDevicePlugin()
if err := devicePlugin.Serve(); err != nil {
log.Println("Could not contact Kubelet, retrying. Did you enable the device plugin feature gate?")
log.Printf("You can check the prerequisites at: https://github.com/NVIDIA/k8s-device-plugin#prerequisites")
log.Printf("You can learn how to set the runtime at: https://github.com/NVIDIA/k8s-device-plugin#quick-start")
} else {
restart = false
}
}
select {
case event := <-watcher.Events:
if event.Name == pluginapi.KubeletSocket && event.Op&fsnotify.Create == fsnotify.Create {
log.Printf("inotify: %s created, restarting.", pluginapi.KubeletSocket)
restart = true
}
case err := <-watcher.Errors:
log.Printf("inotify: %s", err)
case s := <-sigs:
switch s {
case syscall.SIGHUP:
log.Println("Received SIGHUP, restarting.")
restart = true
default:
log.Printf("Received signal \"%v\", shutting down.", s)
devicePlugin.Stop()
break L
}
}
}
} йҖҡиҝҮfsnotify.Watcherзӣ‘жҺ§/var/lib/kubelet/device-plugins/зӣ®еҪ•гҖӮ
еҰӮжһңfsnotify.Watcherзҡ„Events Channel收еҲ°Create kubelet.sockдәӢ件пјҲиҜҙжҳҺkubeletеҸ‘з”ҹйҮҚеҗҜпјүпјҢеҲҷдјҡи§ҰеҸ‘Nvidia Device Pluginзҡ„йҮҚеҗҜгҖӮ
Nvidia Device PluginйҮҚеҗҜзҡ„йҖ»иҫ‘жҳҜпјҡе…ҲжЈҖжҹҘdevicePluginеҜ№иұЎжҳҜеҗҰдёәз©әпјҲиҜҙжҳҺе®ҢжҲҗдәҶNvidia Device Pluginзҡ„еҲқе§ӢеҢ–пјүпјҡ
еҰӮжһңдёҚдёәз©әпјҢеҲҷе…ҲеҒңжӯўNvidia Device Pluginзҡ„gRPC ServerгҖӮ
然еҗҺи°ғз”ЁNewNvidiaDevicePlugin()йҮҚе»әдёҖдёӘж–°зҡ„DevicePluginе®һдҫӢгҖӮ
и°ғз”ЁServe()еҗҜеҠЁgRPC ServerпјҢ并е…ҲkubeletжіЁеҶҢиҮӘе·ұгҖӮ
еӣ жӯӨпјҢиҝҷе…¶дёӯеҸӘзӣ‘жҺ§дәҶkubelet.sockзҡ„CreateдәӢ件пјҢиғҪеҫҲеҘҪеӨ„зҗҶkubeletйҮҚеҗҜзҡ„й—®йўҳпјҢдҪҶжҳҜ并没жңүзӣ‘жҺ§иҮӘе·ұзҡ„socketжҳҜеҗҰиў«еҲ йҷӨзҡ„дәӢ件гҖӮжүҖд»ҘпјҢеҰӮжһңNvidia Device Pluginзҡ„socketиў«иҜҜеҲ дәҶпјҢйӮЈд№Ҳе°ҶдјҡеҜјиҮҙkubeletж— жі•дёҺиҜҘиҠӮзӮ№зҡ„Nvidia Device PluginиҝӣиЎҢsocketйҖҡдҝЎпјҢеҲҷж„Ҹе‘ізқҖDevice Pluginзҡ„gRPCжҺҘеҸЈйғҪж— жі•и°ғйҖҡпјҡ
еӣ жӯӨпјҢе»әи®®еҠ дёҠеҜ№иҮӘе·ұdevice plugin socketзҡ„еҲ йҷӨдәӢ件зҡ„зӣ‘жҺ§пјҢдёҖж—Ұзӣ‘жҺ§еҲ°еҲ йҷӨпјҢеҲҷеә”иҜҘи§ҰеҸ‘restartгҖӮ
select {
case event := <-watcher.Events:
if event.Name == pluginapi.KubeletSocket && event.Op&fsnotify.Create == fsnotify.Create {
log.Printf("inotify: %s created, restarting.", pluginapi.KubeletSocket)
restart = true
}
// еўһеҠ еҜ№nvidia.sockзҡ„еҲ йҷӨдәӢ件зӣ‘жҺ§
if event.Name == serverSocket && event.Op&fsnotify.Delete == fsnotify.Delete {
log.Printf("inotify: %s deleted, restarting.", serverSocket)
restart = true
}
...
}Extended Resources
Device PluginжҳҜйҖҡиҝҮExtended ResourcesжқҘexposeе®ҝдё»жңәдёҠзҡ„иө„жәҗзҡ„пјҢKubernetesеҶ…зҪ®зҡ„ResourcesйғҪжҳҜйҡ¶еұһдәҺkubernetes.io domainзҡ„пјҢеӣ жӯӨExtended ResourceдёҚе…Ғи®ёadvertiseеңЁkubernetes.io domainдёӢгҖӮ
Node-level Extended Resource
жіЁж„Ҹпјҡ~1 is the encoding for the character / in the patch pathгҖӮ
з»ҷAPI ServerжҸҗдәӨPATCHиҜ·жұӮпјҢз»ҷnodeзҡ„status.capacityж·»еҠ ж–°зҡ„иө„жәҗеҗҚз§°е’Ңж•°йҮҸпјӣ
kubeletйҖҡиҝҮе®ҡжңҹжӣҙж–°node status.allocatableеҲ°API ServerпјҢиҝҷе…¶дёӯе°ұеҢ…жӢ¬дәӢе…Ҳз»ҷnodeжү“PATCHж–°еҠ зҡ„иө„жәҗгҖӮд№ӢеҗҺиҜ·жұӮдәҶж–°еҠ иө„жәҗзҡ„Podе°ұдјҡиў«schedulerж №жҚ®node status.allocatableиҝӣиЎҢFitResources Predicateз”©йҖүnodeгҖӮ
жіЁж„ҸпјҡkubeletйҖҡиҝҮ--node-status-update-frequencyй…ҚзҪ®е®ҡжңҹжӣҙж–°й—ҙйҡ”пјҢй»ҳи®Ө10sгҖӮеӣ жӯӨпјҢеҪ“дҪ жҸҗдәӨе®ҢPATCHеҗҺпјҢжңҖеқҸжғ…еҶөдёӢеҸҜиғҪиҰҒзӯүеҫ…10sе·ҰеҸізҡ„ж—¶й—ҙжүҚиғҪиў«schedulerеҸ‘зҺ°е№¶дҪҝз”ЁиҜҘиө„жәҗгҖӮ
Device pluginз®ЎзҗҶзҡ„иө„жәҗ
е…¶д»–иө„жәҗ
curl --header "Content-Type: application/json-patch+json" \
--request PATCH \
--data '[{"op": "add", "path": "/status/capacity/example.com~1foo", "value": "5"}]' \
http://k8s-master:8080/api/v1/nodes/k8s-node-1/status
Cluster-level Extended Resources
йҖҡеёёйӣҶзҫӨзә§зҡ„Extended ResourcesжҳҜз»ҷscheduler extenderдҪҝз”Ёзҡ„пјҢз”ЁжқҘеҒҡResourcesзҡ„й…Қйўқз®ЎзҗҶгҖӮ
еҪ“PodиҜ·жұӮзҡ„resourceдёӯеҢ…еҗ«иҜҘextended resourcesж—¶пјҢdefault schedulerжүҚдјҡе°ҶиҝҷдёӘPodеҸ‘з»ҷеҜ№еә”зҡ„scheduler extenderиҝӣиЎҢдәҢж¬Ўи°ғеәҰгҖӮ
ignoredByScheduler fieldеҰӮжһңи®ҫзҪ®дёәtrueпјҢеҲҷdefault schedulerе°ҶдёҚдјҡеҜ№иҜҘиө„жәҗиҝӣиЎҢPodFitsResourcesйў„йҖүжЈҖжҹҘпјҢйҖҡеёёйғҪдјҡи®ҫзҪ®дёәtrueпјҢеӣ дёәCluster-levelдёҚжҳҜи·ҹnodeзӣёе…ізҡ„пјҢдёҚйҖӮеҗҲиҝӣиЎҢPodFitResourcesеҜ№Nodeиө„жәҗиҝӣиЎҢжЈҖжҹҘгҖӮ
{
"kind": "Policy",
"apiVersion": "v1",
"extenders": [
{
"urlPrefix":"<extender-endpoint>",
"bindVerb": "bind",
"ManagedResources": [
{
"name": "example.com/foo",
"ignoredByScheduler": true
}
]
}
]
}
API ServerйҷҗеҲ¶дәҶExtender ResourcesеҸӘиғҪдёәж•ҙж•°пјҢжҜ”еҰӮ2,2000m,2KiпјҢдёҚиғҪдёә1.5, 1500mгҖӮ
Contaienr resources filedдёӯеҸӘй…ҚзҪ®зҡ„Extended Resourcesеҝ…йЎ»жҳҜGuaranteed QoSгҖӮеҚіиҰҒд№ҲеҸӘжҳҫзӨәи®ҫзҪ®дәҶlimits(жӯӨж—¶requestsй»ҳи®ӨеҗҢlimits)пјҢиҰҒд№Ҳrequestsе’ҢlimitжҳҫзӨәй…ҚзҪ®дёҖж ·гҖӮ
Scheduler GPU
https://kubernetes.io/docs/tasks/manage-gpus/scheduling-gpus/
иҝҷйҮҢжҲ‘们еҸӘи®Ёи®әKubernetes 1.10дёӯеҰӮдҪ•и°ғеәҰдҪҝз”ЁGPUгҖӮ
еңЁKubernetes 1.8д№ӢеүҚпјҢе®ҳж–№иҝҳжҳҜе»әи®®enable alpha gate feature: AcceleratorsпјҢйҖҡиҝҮиҜ·жұӮresource alpha.kubernetes.io/nvidia-gpuжқҘдҪҝз”ЁgpuпјҢ并且иҰҒжұӮе®№еҷЁжҢӮиҪҪHostдёҠзҡ„nvidia libе’ҢdriverеҲ°е®№еҷЁеҶ…гҖӮиҝҷйғЁеҲҶеҶ…е®№пјҢиҜ·еҸӮиҖғжҲ‘зҡ„еҚҡж–ҮпјҡеҰӮдҪ•еңЁKubernetesйӣҶзҫӨдёӯеҲ©з”ЁGPUиҝӣиЎҢAIи®ӯз»ғгҖӮ
д»ҺKubernetes 1.8ејҖе§ӢпјҢе®ҳж–№жҺЁиҚҗдҪҝз”ЁDevice Pluginsж–№ејҸжқҘдҪҝз”ЁGPUгҖӮ
йңҖиҰҒеңЁNodeдёҠpre-install NVIDIA DriverпјҢ并е»әи®®йҖҡиҝҮDaemonsetйғЁзҪІNVIDIA Device PluginпјҢе®ҢжҲҗеҗҺKubernetesжүҚиғҪеҸ‘зҺ°nvidia.com/gpuгҖӮ
еӣ дёәdevice pluginйҖҡиҝҮextended resourcesжқҘexpose gpu resourceзҡ„пјҢжүҖд»ҘеңЁcontainerиҜ·жұӮgpuиө„жәҗзҡ„ж—¶еҖҷиҰҒжіЁж„Ҹresource QoSдёәGuaranteedгҖӮ
Containersзӣ®еүҚд»Қ然дёҚж”ҜжҢҒе…ұдә«еҗҢдёҖеқ—gpuеҚЎгҖӮжҜҸдёӘContainerеҸҜд»ҘиҜ·жұӮеӨҡеқ—gpuеҚЎпјҢдҪҶжҳҜдёҚж”ҜжҢҒgpu fractionгҖӮ
дҪҝз”Ёе®ҳж–№nvidia driverйҷӨдәҶд»ҘдёҠжіЁж„ҸдәӢйЎ№д№ӢеӨ–пјҢиҝҳйңҖжіЁж„Ҹпјҡ
NodeдёҠйңҖиҰҒpre-install nvidia docker 2.0пјҢ并дҪҝз”Ёnvidia dockerжӣҝжҚўrunCдҪңдёәdockerзҡ„й»ҳи®ӨruntimeгҖӮ
еңЁCentOSдёҠпјҢеҸӮиҖғеҰӮдёӢж–№ејҸе®үиЈ…nvidia docker 2.0 :
# Add the package repositories
distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.repo | \
sudo tee /etc/yum.repos.d/nvidia-docker.repo
# Install nvidia-docker2 and reload the Docker daemon configuration
sudo yum install -y nvidia-docker2
sudo pkill -SIGHUP dockerd
# Test nvidia-smi with the latest official CUDA image
docker run --runtime=nvidia --rm nvidia/cuda nvidia-smi
д»ҘдёҠе·ҘдҪңйғҪе®ҢжҲҗеҗҺпјҢContainerе°ұеҸҜд»ҘеғҸиҜ·жұӮbuit-in resourcesдёҖж ·иҜ·жұӮgpuиө„жәҗдәҶпјҡ
apiVersion: v1
kind: Pod
metadata:
name: cuda-vector-add
spec:
restartPolicy: OnFailure
containers:
- name: cuda-vector-add
# https://github.com/kubernetes/kubernetes/blob/v1.7.11/test/images/nvidia-cuda/Dockerfile
image: "k8s.gcr.io/cuda-vector-add:v0.1"
resources:
limits:
nvidia.com/gpu: 2 # requesting 2 GPU
дҪҝз”ЁNodeSelectorеҢәеҲҶдёҚеҗҢеһӢеҸ·зҡ„GPUжңҚеҠЎеҷЁ
еҰӮжһңдҪ зҡ„йӣҶзҫӨдёӯеӯҳеңЁдёҚеҗҢеһӢеҸ·зҡ„GPUжңҚеҠЎеҷЁпјҢжҜ”еҰӮnvidia tesla k80, p100, v100зӯүпјҢиҖҢдё”дёҚеҗҢзҡ„и®ӯз»ғд»»еҠЎйңҖиҰҒеҢ№й…ҚдёҚеҗҢзҡ„GPUеһӢеҸ·пјҢйӮЈд№Ҳе…Ҳз»ҷNodeжү“дёҠеҜ№еә”зҡ„Labelпјҡ
# Label your nodes with the accelerator type they have.
kubectl label nodes <node-with-k80> accelerator=nvidia-tesla-k80
kubectl label nodes <node-with-p100> accelerator=nvidia-tesla-p100
PodдёӯйҖҡиҝҮNodeSelectorжқҘжҢҮе®ҡеҜ№еә”зҡ„GPUеһӢеҸ·пјҡ
apiVersion: v1
kind: Pod
metadata:
name: cuda-vector-add
spec:
restartPolicy: OnFailure
containers:
- name: cuda-vector-add
# https://github.com/kubernetes/kubernetes/blob/v1.7.11/test/images/nvidia-cuda/Dockerfile
image: "k8s.gcr.io/cuda-vector-add:v0.1"
resources:
limits:
nvidia.com/gpu: 1
nodeSelector:
accelerator: nvidia-tesla-p100 # or nvidia-tesla-k80 etc.
жҖқиҖғпјҡе…¶е®һд»…д»…дҪҝз”ЁNodeSelectorжҳҜдёҚиғҪеҫҲеҘҪи§ЈеҶіиҝҷдёӘй—®йўҳзҡ„пјҢиҝҷиҰҒжұӮжүҖжңүзҡ„podйғҪиҰҒеҠ дёҠеҜ№еә”зҡ„NodeSelectorгҖӮеҜ№дәҺV100иҝҷж ·зҡ„жҳӮиҙөзЁҖжңүзҡ„GPUеҚЎпјҢйҖҡеёёиҝҳиҰҒжұӮдёҚиғҪи®©еҲ«зҡ„и®ӯз»ғд»»еҠЎдҪҝз”ЁпјҢеҸӘз»ҷжҹҗдәӣз®—жі•и®ӯз»ғдҪҝз”ЁпјҢиҝҷдёӘж—¶еҖҷжҲ‘们еҸҜд»ҘйҖҡиҝҮз»ҷNodeжү“дёҠеҜ№еә”зҡ„TaintпјҢз»ҷйңҖиҰҒзҡ„Podзҡ„жү“дёҠеҜ№еә”Tolerationе°ұиғҪе®ҢзҫҺж»Ўи¶ійңҖжұӮдәҶгҖӮ
Deploy
е»әи®®йҖҡиҝҮDaemonsetжқҘйғЁзҪІDevice PluginпјҢж–№дҫҝе®һзҺ°failoverгҖӮ
Device Plugin Podеҝ…йЎ»е…·жңүprivilegedзү№жқғжүҚиғҪи®ҝй—®/var/lib/kubelet/device-plugins
Device Plugin PodйңҖе°Ҷе®ҝдё»жңәзҡ„hostpath /var/lib/kubelet/device-pluginsжҢӮиҪҪеҲ°е®№еҷЁеҶ…зӣёеҗҢзҡ„зӣ®еҪ•гҖӮ
kubernetes 1.8
apiVersion: extensions/v1beta1
kind: DaemonSet
metadata:
name: nvidia-device-plugin-daemonset
spec:
template:
metadata:
labels:
name: nvidia-device-plugin-ds
spec:
containers:
- image: nvidia/k8s-device-plugin:1.8
name: nvidia-device-plugin-ctr
securityContext:
privileged: true
volumeMounts:
- name: device-plugin
mountPath: /var/lib/kubelet/device-plugins
volumes:
- name: device-plugin
hostPath:
path: /var/lib/kubelet/device-plugins
kubernetes 1.10
apiVersion: extensions/v1beta1
kind: DaemonSet
metadata:
name: nvidia-device-plugin-daemonset
namespace: kube-system
spec:
template:
metadata:
# Mark this pod as a critical add-on; when enabled, the critical add-on scheduler
# reserves resources for critical add-on pods so that they can be rescheduled after
# a failure. This annotation works in tandem with the toleration below.
annotations:
scheduler.alpha.kubernetes.io/critical-pod: ""
labels:
name: nvidia-device-plugin-ds
spec:
tolerations:
# Allow this pod to be rescheduled while the node is in "critical add-ons only" mode.
# This, along with the annotation above marks this pod as a critical add-on.
- key: CriticalAddonsOnly
operator: Exists
containers:
- image: nvidia/k8s-device-plugin:1.10
name: nvidia-device-plugin-ctr
securityContext:
privileged: true
volumeMounts:
- name: device-plugin
mountPath: /var/lib/kubelet/device-plugins
volumes:
- name: device-plugin
hostPath:
path: /var/lib/kubelet/device-plugins
е…ідәҺKubernetesеҜ№critical podзҡ„еӨ„зҗҶпјҢи¶ҠжқҘи¶Ҡжңүж„ҸжҖқдәҶпјҢжүҫдёӘж—¶й—ҙеҚ•зӢ¬еҶҷдёӘеҚҡе®ўеҶҚиҜҰз»ҶиҒҠиҝҷдёӘгҖӮ
Device PluginsеҺҹзҗҶеӣҫ
дёҠиҝ°еҶ…е®№е°ұжҳҜKubernetesеҰӮдҪ•йҖҡиҝҮDevice PluginsжқҘдҪҝз”ЁNVIDIA GPUпјҢдҪ 们еӯҰеҲ°зҹҘиҜҶжҲ–жҠҖиғҪдәҶеҗ—пјҹеҰӮжһңиҝҳжғіеӯҰеҲ°жӣҙеӨҡжҠҖиғҪжҲ–иҖ…дё°еҜҢиҮӘе·ұзҡ„зҹҘиҜҶеӮЁеӨҮпјҢж¬ўиҝҺе…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“гҖӮ





