这期内容当中小编将会给大家带来有关GEO数据库架构的原理是什么,文章内容丰富且以专业的角度为大家分析和叙述,阅读完这篇文章希望大家可以有所收获。
GEO是一个国际化的开源项目,允许研究者提交自己的数据到该数据库,在世界范围内公开共享自己的数据,
该数据库最开始主要用于分享芯片数据,后来随着NGS技术的发展,也支持上传高通量测序数据。
在该数据库中,将所有相关信息分成以下几类,示意如下
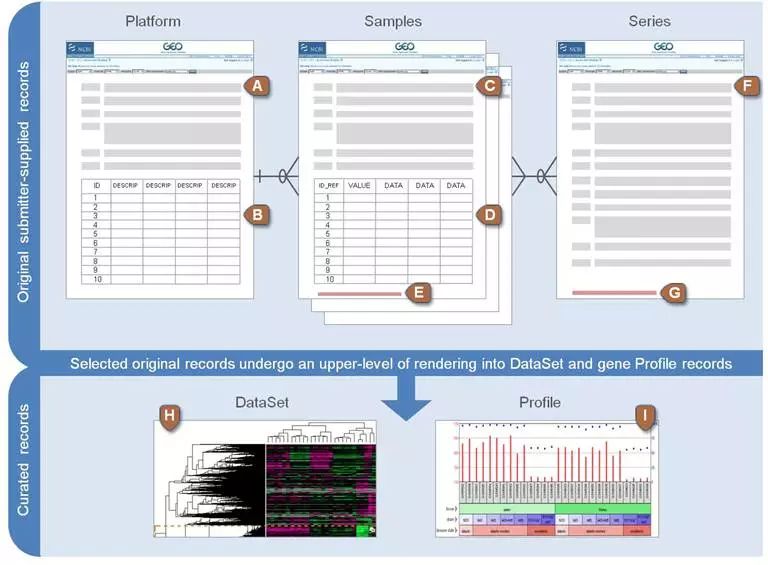
芯片平台或者测序平台,每个平台有一个唯一的以GPL开头的编号,高通量测序平台,示意如下

由测序仪和物种的组合构成了不同的platforn,芯片平台示意如下

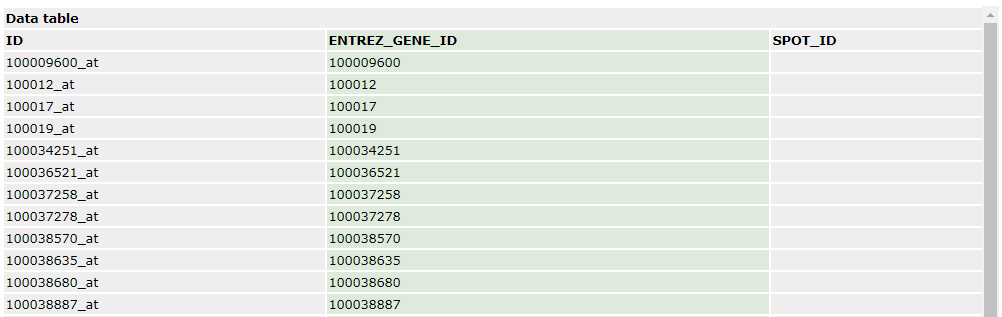
芯片平台会给出探针相关信息,比如对应的基因,探针序列等,示意如下
sample代表的是一个样本的数据,可以是任意platform产生的数据,有一个唯一的以GSM开头的编号,对于芯片数据,会给出探针的表达量值,示意如下

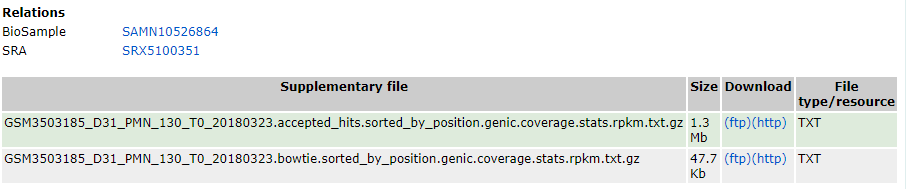
对于高通量测序数据,根据数据类型会给出不同种类的文件,如果原始的测序数据有上传到SRA数据库,也会给出对应SRA编号,示意如下
series代表属于同一个实验设计的一组样本,通常情况下会给出该系列下所有样本的附件文件的压缩包,示意如下

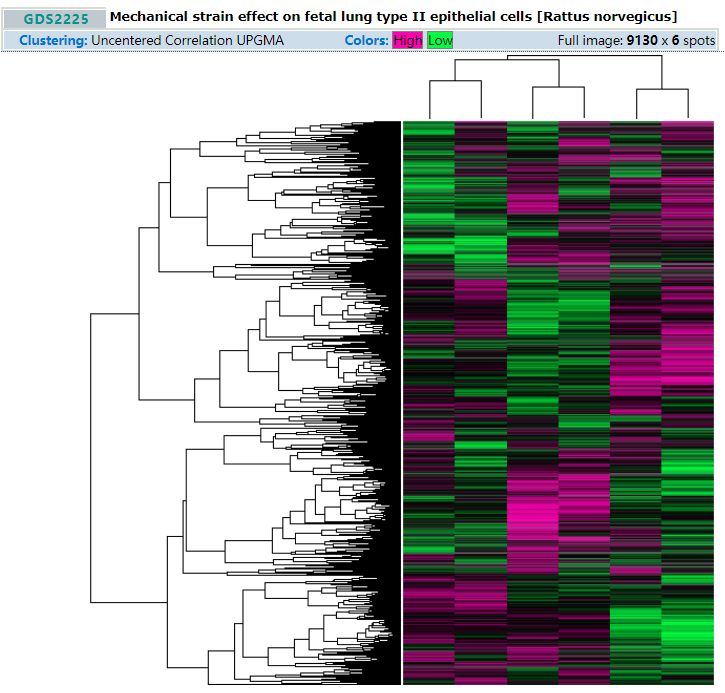
以上这3种信息由数据的提交者提供,对于同一个series下的原始数据,GEO会对其进行简单的挖掘,比如基于表达量进行聚类分析等,这些分析的结果对应的类型为DataSet, 有一个唯一的以GDS开头的编号,GDS2225示意如下

基于GSE3541的数据得到,该数据是一套大鼠的芯片数据,样本分为case和control两组,每组3重复,基于表达量的聚类结果示意如下
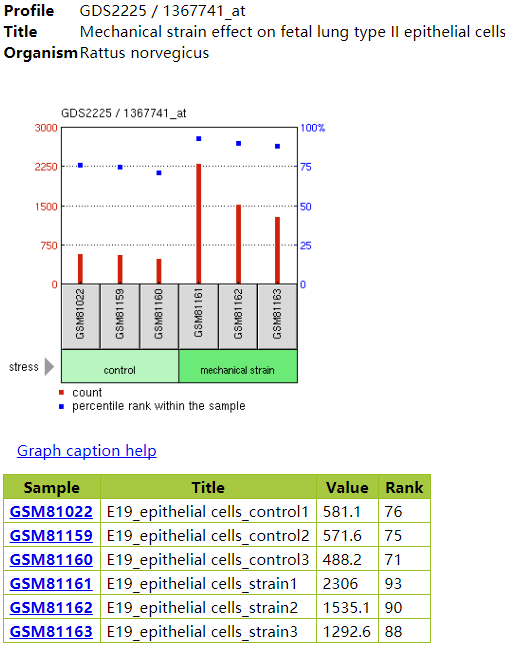
根据DataSet中提供的表达谱数据,对于每个探针或者基因在所有样本中表达量进行探究,就得到了Profile数据,示意如下
数据共享使得基于公共数据库的数据挖掘成为可能,也可以通过分析已有的同种类型数据来和自己的测序数据相互印证。
上述就是小编为大家分享的GEO数据库架构的原理是什么了,如果刚好有类似的疑惑,不妨参照上述分析进行理解。如果想知道更多相关知识,欢迎关注亿速云行业资讯频道。
亿速云「云数据库 MySQL」免部署即开即用,比自行安装部署数据库高出1倍以上的性能,双节点冗余防止单节点故障,数据自动定期备份随时恢复。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/u/4580290/blog/4616013



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



