Sqoop是Apache旗下的一款“hadoop和关系型数据库服务器之间传送数据”的工具。
导入数据:MySQL、Oracle导入数据到hadoop的hdfs、hive、HBASE等数据存储系统。
导出数据:从hadoop的文件系统中导出数据到关系型数据库中。
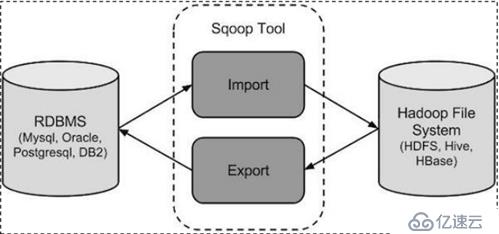
将导入导出的命令翻译成MapReduce程序来实现,并且MapReduce程序不需要reducetask的。在翻译出的MapReduce中主要针对对 InputFormat 和 OutputFormat 进行定制。
数据导入:
sqoop工具是通过MapReduce进行导入作业的。总体来说,是把关系型数据库中的某张表的一行行记录写入hdfs中。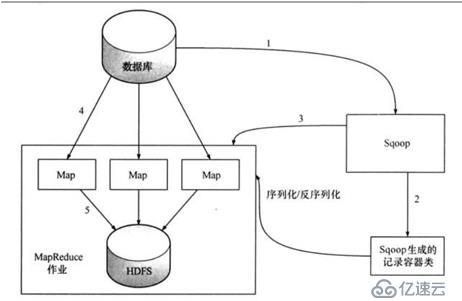
解释:
- sqoop会通过jdbc来获取需要的数据库的元数据信息,例如:导入的表的列名,数据类型。
- 这些数据库的数据类型会被映射成为java的数据类型,根据这些信息,sqoop会生成一个与表名相同的类用来完成序列化工作,保存表中的每一行记录。
- sqoop开启MapReduce作业
- 启动的作业在input的过程中,会通过jdbc读取数据表中的内容,这时,会使用sqoop生成的类进行序列化。
- 最后将这些记录写到hdfs上,在写入hdfs的过程中,同样会使用sqoop生成的类进行反序列化。
数据导出: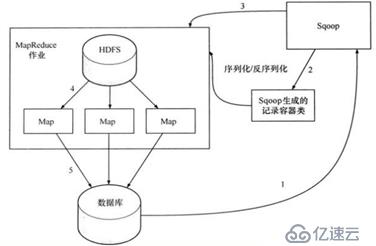
解释:
- 首先sqoop通过jdbc访问关系型数据库,得到需要导出的数据的元数据信息
- 根据获取的元数据信息,sqoop生成一个java类,用来进行数据的传输载体,该类必须实现序列化。
- 启动MapReduce程序
- sqoop利用生成的这个java类,并行的从hdfs中读取数据
- 每一个map作业都会根据读取到的导出表的元数据信息和读取到的数据,生成一批的insert语句然后多个 map 作业会并行的向数据库 mysql 中插入数据。
总结:数据是从hdfs中并发进行读取,也是并发进行写入,那并行的读取时依赖hdfs的性能,而并行的写入到MySQL,就要依赖MySQL的性能。
前置要求:已经具备了Java和hadoop的环境。
安装包下载地址:http://ftp.wayne.edu/apache/sqoop/1.4.6/
这里安装的是qoop-1.4.6.bin_hadoop-2.0.4-alpha.tar.gz(sqoop1.x版本)
具体安装:
#sqoop-env.sh
[hadoop hadoop01@ ~]$cd /application/sqoop-1.4.6/conf/
[hadoop hadoop01@ ~]$mv sqoop-env-template.sh sqoop-env.sh
[hadoop hadoop01@ ~]$vim sqoop-env.sh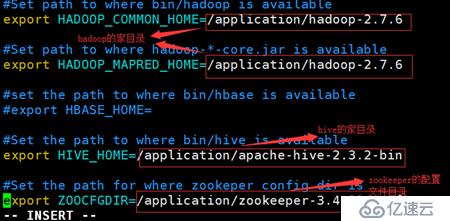
export HADOOP_COMMON_HOME=/application/hadoop-2.7.6
export HADOOP_MAPRED_HOME=/application/hadoop-2.7.6
export HIVE_HOME=/application/apache-hive-2.3.2-bin
export ZOOCFGDIR=/application/zookeeper-3.4.10/conf注意:这里的HADOOP_COMMON_HOME和HADOOP_MAPRED_HOME配成一个就行了,但是我们现在安装的hadoop的开源的版本:所以这两个在一个目录下就行,但是在hadoop的商业版本中这两个配置是分别安装在不同的目录下的。
[hadoop hadoop01@ ~]$vim /etc/profile
export SQOOP_HOME=/application/sqoop-1.4.6
export PATH=$PATH:$ZOOKEEPER_HOME/bin:$SQOOP_HOME/bin
[hadoop hadoop01@ ~]$source /etc/profile
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



